はじめてのGoogle Analytics Reporting APIをちょっとだけ使ってみる
Google AnalyticsからAPIで情報を取得することになりました。
しかし、Google AnalyticsもGoogle APIも使ったことがないので全く分かりません。
ここでは、調べながらはてなブログの情報をGoogle Analytics Reporting APIで取得するまでをやってみます。
Google Analyticsの設定をする
まずは、情報の基となるGoogle Analyticsを設定します。 今回は、このponsuke_taro's blogをGoogle Analyticsに設定して情報を蓄積できるようにします。
はてなブログ用のデータ解析をユニバーサル アナリティクスプロパティで作成する
参考 : Google Analyticsを導入する - はてなブログ ヘルプ
ユニバーサル アナリティクスは前世代の Google アナリティクスです。ユニバーサル アナリティクス プロパティと Google アナリティクス 4 プロパティとでは、使用できるレポートに違いがあります。
- (ない場合)Google アカウントの作成でアカウントを作成する
- お客様のビジネスに適した分析ツールとソリューション - Google アナリティクス を表示する
- [無料で利用する]ボタンで次の画面へ遷移し、[測定を開始]ボタンで設定画面を表示する
- 「アカウント名」に何のアクセス解析かわかる名前を設定して[次へ]ボタンで進む
- 「プロパティ名」などの入力項目を設定して登録する
- レポートのタイムゾーン」「通貨」 : 日本に設定する

- [プロパティの設定]の下にある[詳細オプションを表示]リンクでユニバーサル アナリティクスプロパティの設定欄を表示して以下を設定して[次へ]ボタンで進む
- ユニバーサル アナリティクス プロパティの作成 : ON
- ウェブサイトの URL : 登録するはてなブログのURL
- ユニバーサル アナリティクスのプロパティのみを作成する : ON
- [ビジネス情報]部分は任意で入力して[作成]ボタンで作成する
- [プロパティ]で作成したプロパティを選択 > [トラッキング情報] > [トラッキングコード] > [トラッキングID]をメモしておく




はてなブログにトラッキングIDを設定する
- はてなブログにログインしてダッシュボード管理画面を表示する
- [設定] > [詳細設定] > [解析ツール] > [Google Analytics 埋め込み]にメモしたGoogle AnalyticsのトラッキングIDを入力する
- ページ下の[変更する]ボタンで変更を確定する
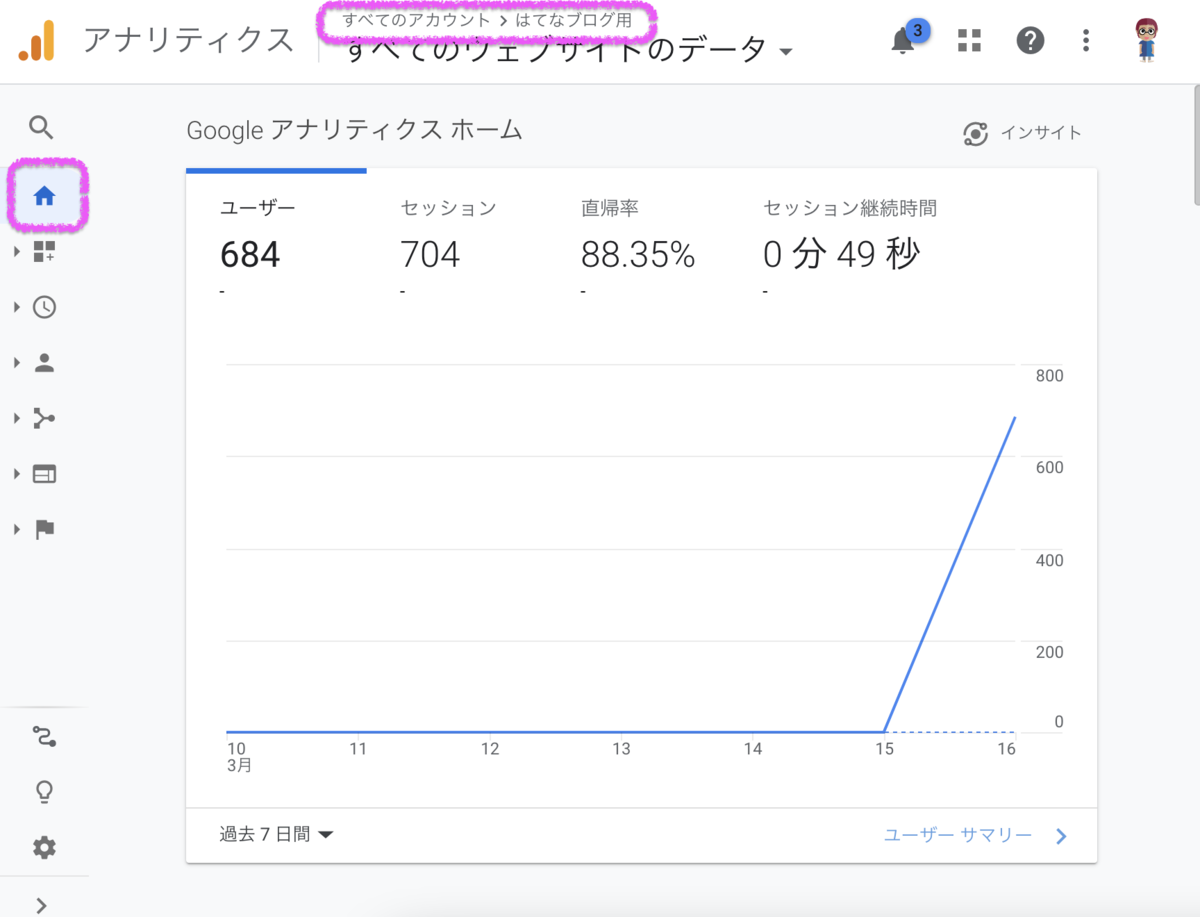
お茶しながら数時間待つとGoogle Analyticsの画面にいろいろ表示され始める
Google Cloud PlatformでAPI使えるようにする
作成したはてなブログ用のデータ解析に溜まった情報をGoogle Cloud Platform(以降GCP)のAPIで取得できるように設定していきます。
Google Analytics Reporting APIを有効化する
まずは、Google Analytics Reporting APIを使えるように設定します。
- Google Cloud Platformにログインする
- (ない場合)プロジェクトを作成する
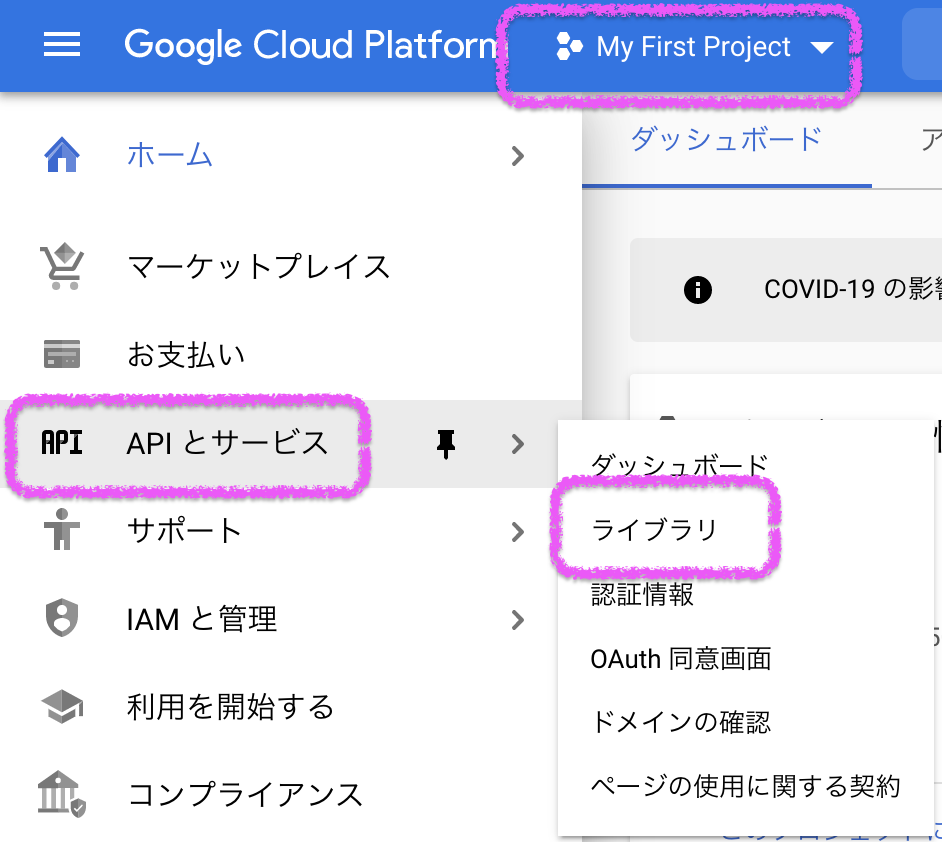
- GCP画面上部でプロジェクトを選択 > [APIとサービス] > [ライブラリ]
- 「Google Analytics API」を検索して、「Google Analytics Reporting API」を選択する
- [有効にする]ボタンでAPIを有効化する
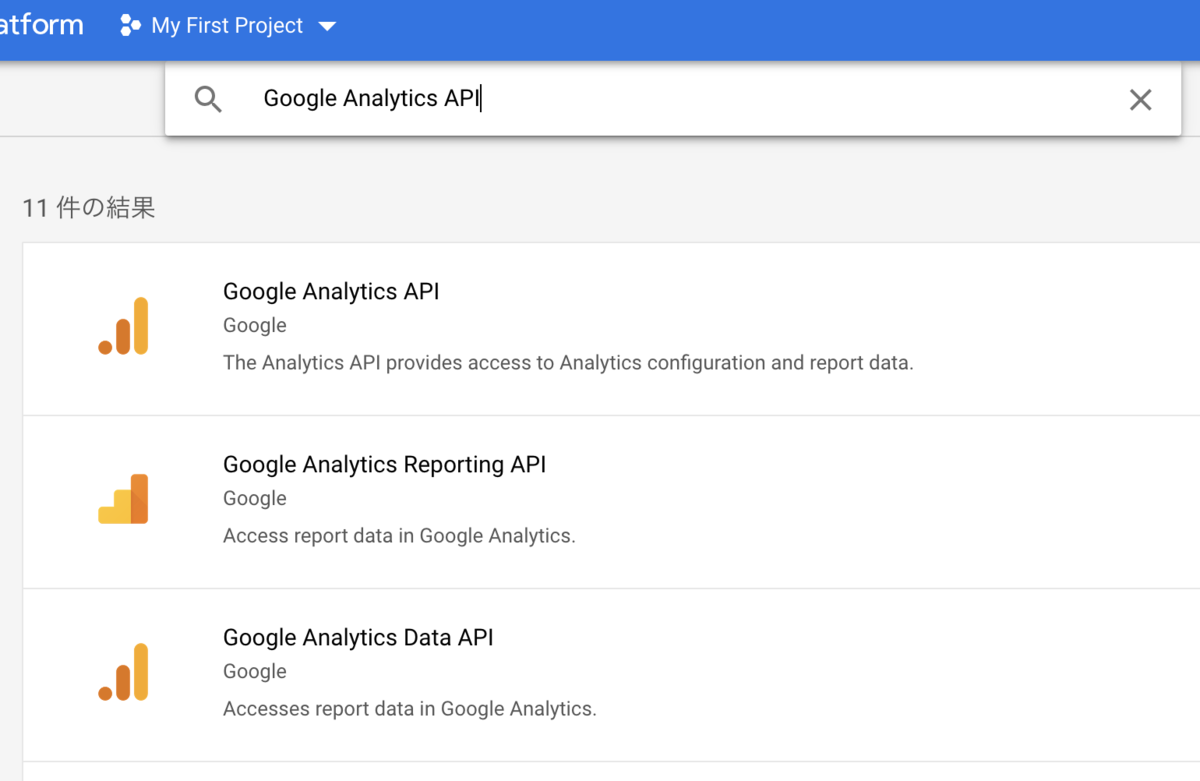
3つ候補に出てきたAPIの違いがいまいちわからないので頑張った概要の和訳を記録として書いておきます。
| API名 | 概要の頑張った和訳 |
|---|---|
| Google Analytics API | Analyticsの設定およびレポートデータへのアクセスを提供します。 |
| Google Analytics Reporting API | Google Analyticsでレポートデータにアクセスするための最も高度なプログラム的方法です。Google AnalyticsレポートAPIを使用すると、カスタムダッシュボードを構築してGoogle Analyticsデータを表示したり、複雑なレポートタスクを自動化して時間を節約したり、Google Analyticsデータを他のビジネスアプリケーションと統合したりすることができます。 |
| Google Analytics Data API | Google Analyticsのレポートデータにアクセスします。 |
サービスアカウントを作成する
APIを利用するサービスアカウントを作成します。
サービス アカウントは IAM によって管理されるもので、人間のユーザー以外のものを指しています。App Engine アプリの実行や Compute Engine インスタンスとのやり取りなど、アプリケーション自体がリソースにアクセスする場合や、アクションを独自に実行する必要がある場合を対象としています。
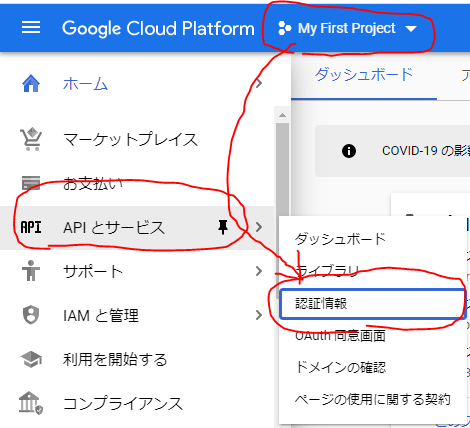
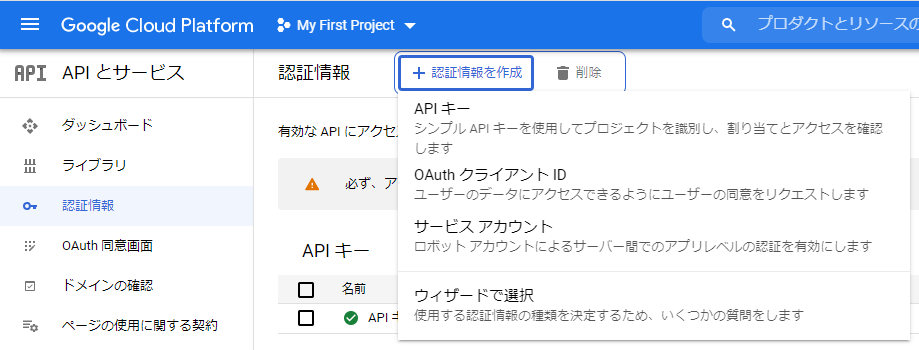
- GCP画面上部でプロジェクトを選択 > サイドメニュー[APIとサービス] > [認証情報]
- [認証情報を作成]ボタン > [サービス アカウント]
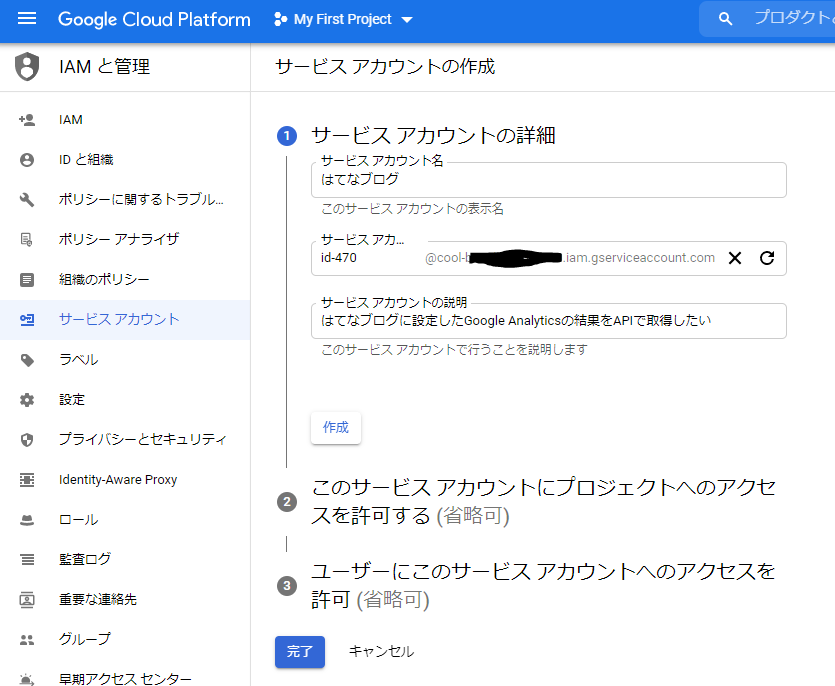
- 「サービス アカウント名」「サービス アカウント ID」に任意の値を入力して[完了]ボタンでアカウントを作成する
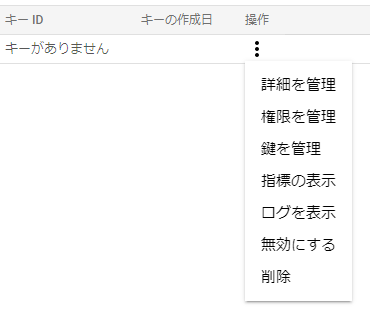
- 一覧にある作成したアカウントの[操作] > [詳細を管理]で詳細画面を表示
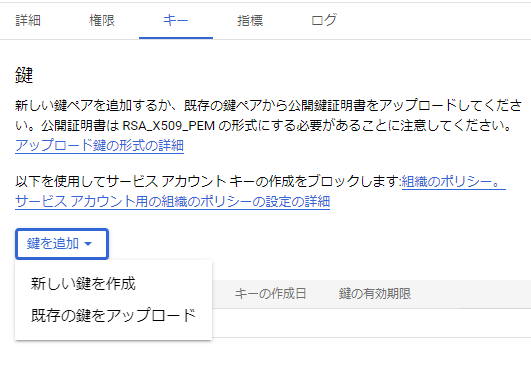
- [キー]タブ > [鍵を追加] > [新しい鍵を作成]
- [キーのタイプ]で「JSON」を選択 > [作成]ボタンで作成して鍵ファイルをダウンロードする
- ここでダウンロードする鍵ファイルは「再作成できない」「鍵があればサービスを使えてしまう」ので超大切に保管する

Google Analyticsで作成したサービスアカウントに権限を設定する
作成したアカウントがGoogle Analyticsにあるはてなブログの情報を取得できるように権限を設定します。
- Google Analyticsにログインする
- 管理 > 対象のアカウント選択 > [アカウントユーザーの管理]
- 右上の[+]ボタン > [ユーザーを追加]
- 以下を設定して[追加]ボタンで追加する
- メールアドレス : 作成したサービスアカウントのサービスアカウントID(
@以降も入力する) - 権限 : 表示と分析
- メールアドレス : 作成したサービスアカウントのサービスアカウントID(

Google Analytics Reporting APIを呼び出す
早速、Google Analytics Reporting APIを呼び出してみます。
PythonとCloud9でちょっとだけ使ってみる
メトリクスとディメンションって何?
レポートの作成 | アナリティクス Reporting API v4 | Google Developersで基本の使い方を見ていくとまずはmetricsとdimensionsなるものに引っかかりました。
Web分析をやっている人には疑問に思わないことなのでしょうが、Google AnalyticsはおろかWeb分析的なことをやったことがないので「メトリクス」「ディメンション」が何なのかわかりません。
アナリティクスのレポートは、すべてディメンションと指標の組み合わせに基づいて構成されます。
ディメンションはデータの属性です。たとえば、ディメンション「市区町村」はセッションの性質を表し、「横浜」、「川崎」などセッションが発生した市区町村を指定します。ディメンション「ページ」は、閲覧されたページの URL を表します。
指標はデータを定量化したものです。指標「セッション」はセッションの合計数です。指標「ページ/セッション」は、セッションあたりの平均閲覧ページ数です。
「メトリクス=量」「ディメンション=量の単位」みたいな感じです(正確には違うけど)。
「日単位のPV数を取得したい」だと「日」がディメンションで「PV数」がメトリクス・・・的な。
HelloAnalytics.pyのget_reportメソッドにあるパラメータをこんな感じに変えると・・・
※. ここのコードははじめてのGoogle Analytics Reporting APIをPythonとCloud9でちょっとだけ使ってみる - ponsuke_tarou’s blogで使ったものを基にしています。
# ...省略... 'reportRequests': [ { 'viewId': VIEW_ID, 'dateRanges': [{'startDate': '7daysAgo', 'endDate': 'today'}], # メトリクスにPVを指定 'metrics': [{'expression': 'ga:pageviews'}], # ディメンションに日にちを指定 'dimensions': [{'name': 'ga:date'}] }] # ...省略...
こんな感じで「日単位のPV数」が取得できました。
ga:date: 20210316 Date range: 0 ga:pageviews: 411 ga:date: 20210317 Date range: 0 ga:pageviews: 845 ga:date: 20210318 Date range: 0 ga:pageviews: 787 ga:date: 20210319 Date range: 0 ga:pageviews: 498
メトリクスとディメンションで指定する値の意味が分からなくなりそうなので使ったものはメモしていきます。
| dimensions | 意味 | レスポンス例 |
|---|---|---|
| ga:date | 日付 | 20210322 |
| ga:pagePath | ページ | "/ponsuke0531/items/edf2eee638202aa7f61f" |
| ga:sourceMedium | 参照元 | "zenn.dev / referral" |
| ga:dimension{インデックス番号} | カスタム ディメンション |
どこかに日本語で一覧があったらいいのに・・・。
| metrics | 意味 | type | レスポンス例 |
|---|---|---|---|
| ga:pageviews | ページビュー数 | INTEGER | 1631 |
| ga:avgTimeOnPage | 平均ページ滞在時間(秒) | TIME | "387.46666666666664" |
| ga:bounceRate | 直帰率 | PERCENT | "0.0" |
Google APIには、リクエスト数の制限がありますので気をつけましょう。
遊びで使っているだけならいいのですが、お仕事で使う場合などにはAPIへのリクエスト数の制限がありますので気をつけましょう。
Node.jsでちょっとだけ使ってみる
1回のAPI呼出しで5こまでリクエストを送信できます
各リクエストには、別々のレスポンスが返されます。リクエストは最大で 5 つ送信できます。すべてのリクエストには、同じ dateRanges、viewId、segments、samplingLevel、および cohortGroup が含まれている必要があります。
リクエストの本文 | メソッド: reports.batchGet | アナリティクス Reporting API v4 | Google Developers
こんな感じで1回のAPI呼出しで2このリクエストを送信してみました。
※. ここのコードははじめてのGoogle Analytics Reporting APIをNode.jsでちょっとだけ使ってみる - ponsuke_tarou’s blogで使ったものを基にしています。
let dateRanges = [{startDate: '2021-03-19', endDate: '2021-03-30'}] // 1回のAPI呼出し const res = await client.reports.batchGet({ requestBody: { reportRequests: [ // 1こ目のリクエスト { viewId: VIEW_ID, dateRanges: dateRanges, dimensions: [{name: 'ga:pagePath'}], metrics: [{expression: 'ga:pageviews'}, {expression: 'ga:avgTimeOnPage'}], orderBys: {fieldName: 'ga:pageviews', sortOrder: 'DESCENDING'}, pageSize: 3 }, // 2こ目のリクエスト { viewId: VIEW_ID, dateRanges: dateRanges, dimensions: [{name: 'ga:sourceMedium'}], metrics: [{expression: 'ga:bounceRate'}, {expression: 'ga:avgTimeOnPage'}], orderBys: {fieldName: 'ga:avgTimeOnPage', sortOrder: 'DESCENDING'}, pageSize: 3 } ] } })
レスポンスも2こ分返ってきました。(レスポンスは手ごろに改行しています。)
{"reports":[ { "columnHeader":{"dimensions":["ga:pagePath"],"metricHeader":{"metricHeaderEntries":[{"name":"ga:pageviews","type":"INTEGER"},{"name":"ga:avgTimeOnPage","type":"TIME"}]}}, "data":{"rows":[ {"dimensions":["/ponsuke0531/items/4629626a3e84bcd9398f"],"metrics":[{"values":["1631","387.46666666666664"]}]}, {"dimensions":["/ponsuke0531/items/df51a784b5ff48c97ac7"],"metrics":[{"values":["1160","601.5056179775281"]}]}, {"dimensions":["/ponsuke0531/items/edf2eee638202aa7f61f"],"metrics":[{"values":["999","401.8253968253968"]}]} ], "totals":[{"values":["35429","382.3464974141984"]}], "rowCount":499, "minimums":[{"values":["1","0.0"]}], "maximums":[{"values":["1631","1679.0"]}]}, "nextPageToken":"3" }, { "columnHeader":{"dimensions":["ga:sourceMedium"],"metricHeader":{"metricHeaderEntries":[{"name":"ga:bounceRate","type":"PERCENT"},{"name":"ga:avgTimeOnPage","type":"TIME"}]}}, "data":{"rows":[ {"dimensions":["27.94.140.223:8080 / referral"],"metrics":[{"values":["0.0","1335.0"]}]}, {"dimensions":["nekorokkekun.hatenablog.com / referral"],"metrics":[{"values":["0.0","996.0"]}]}, {"dimensions":["zenn.dev / referral"],"metrics":[{"values":["0.0","909.0"]}]} ], "totals":[{"values":["86.22115384615384","382.3464974141984"]}], "rowCount":69, "minimums":[{"values":["0.0","0.0"]}], "maximums":[{"values":["100.0","1335.0"]}]}, "nextPageToken":"3" } ]}
試しにリクエストの部分をコピペして6こリクエストを送信したらちゃんと以下のエラーになりました。
$ node analytics.js (node:7580) UnhandledPromiseRejectionWarning: Error: There are too many requests in the batch request. The max allowed is 5 at Gaxios._request (C:\path\google-analytics-api\node_modules\gaxios\build\src\gaxios.js:127:23) at process._tickCallback (internal/process/next_tick.js:68:7) (node:7580) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). (rejection id: 1) (node:7580) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
JavaとSpringBootでちょっとだけ使ってみる(現在奮闘中)
さて、実際に使いたい環境でもやってみようと思ったら・・・そもそもPythonは使っていない・・・本当にぽんすけですね。 ということで今度はJavaを使ってSpring Bootの環境でやってみたいと思います。
- Spring Bootのプロジェクトを用意する
- クライアント ライブラリをインストールする
SpringのRestTemplateでAPIを呼び出す時にクエリパラメータをくっつける
RestTemplateでAPIを使うのにパラメータの設定方法を試しました。
はじめてSpring BootでRestTemplateを使ってAPIを呼び出すことになりました。
public class RestTemplate extends InterceptingHttpAccessor implements RestOperations
HTTP リクエストを実行する同期クライアント。JDK HttpURLConnection、Apache HttpComponents などの基盤となる HTTP クライアントライブラリ上でシンプルなテンプレートメソッド API を公開します。 RestTemplate は、頻度の低いケースをサポートする一般化された exchange および execute メソッドに加えて、HTTP メソッドによる一般的なシナリオのテンプレートを提供します。
クエリパラメータは、必須でない場合に設定したりしなかったりと可変になりますが、どんな方法がいいのでしょう? クエリパラメータを設定するにはどんな方法がいいのか試してみることにしました。
e-StatのAPIをサンプルに使います。
サンプルに呼び出すAPIは、政府統計の総合窓口(e-Stat)−API機能の統計表情報取得を使います。
パラメータには以下の値を設定します。
| パラメータ名 | 意味 | 設定する値 |
|---|---|---|
| appId | アプリケーションID | e-Statのサイトで取得したアプリケーションID |
| openYears | 公開年月 | 202102 |
| statsField | 統計分野 | 0204(人口移動) |
| limit | データ取得件数 | 1 |
ControllerをでAPIを呼び出しちゃいます。
Serviceとかで呼ぶ方がいいと思いますが、とにかくパラメータをくっつける練習としてControllerでAPIを呼び出します。
package com.example.demo.controller; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; import com.fasterxml.jackson.databind.JsonNode; @RestController @RequestMapping("/estat") public class EstatController { private static final String URL = "http://api.e-stat.go.jp/rest/3.0/app/json"; /** アプリケーションID. */ private String appId = "02b...e-Statのサイトで取得したアプリケーションID"; /** 公開年月. */ private String openYears = "202102"; /** 統計分野. */ private String statsField = "0204"; /** データ取得件数. */ private String limit = "1"; @GetMapping("/getStatsList") public JsonNode getStatsList() { RestTemplate restTemplate = new RestTemplate(); ResponseEntity<JsonNode> response = // .....ここに呼び出しの処理を書いていきます......... JsonNode jsonNode = response.getBody(); return jsonNode; } }

クエリパラメータをくっつける
- 環境
パラメータを1つ1つ設定する
public <T> ResponseEntity<T> getForEntity(String url, Class<T> responseType, Object... uriVariables) throws RestClientException 指定された URL で GET を実行して、エンティティを取得します。レスポンスは変換され、ResponseEntity に保存されます。 パラメーター: url - URL responseType - 戻り値の型 uriVariables - テンプレートを展開する変数
上記のgetForEntityを使って書きました。
@GetMapping("/getStatsList") public JsonNode getStatsList() { RestTemplate restTemplate = new RestTemplate(); // 1. getForEntityでクエリパラメータ一つ一つを設定して、APIを呼び出す. ResponseEntity<JsonNode> response = restTemplate.getForEntity( URL + "/getStatsList?appId={appId}&openYears={openYears}&statsField={statsField}&limit={limit}", JsonNode.class, appId, openYears, statsField, limit); JsonNode jsonNode = response.getBody(); return jsonNode; }
UriComponentsBuilderでパラメータを設定する
public <T> ResponseEntity<T> exchange(RequestEntity<?> entity, Class<T> responseType) throws RestClientException 指定された RequestEntity で指定されたリクエストを実行し、レスポンスを ResponseEntity として返します。通常、たとえば RequestEntity の静的ビルダーメソッドと組み合わせて使用されます。 パラメーター: entity - リクエストに書き込むエンティティ responseType - 戻り値の型
UriComponentsBuilderでパラメータを設定して、上記のexchangeでAPIを呼び出しました。
queryParamでパラメータ名と値を設定する
public UriComponentsBuilder queryParam(String name, Object... values) 指定されたクエリパラメーターを追加します。パラメーター名と値の両方に、後で値から展開される URI テンプレート変数を含めることができます。値が指定されていない場合、結果の URI にはクエリパラメーター名のみが含まれます。"?foo=bar" の代わりに "?foo"。 パラメーター: name - クエリパラメーター名 values - クエリパラメーター値
UriComponentsBuilderのqueryParamを使ってクエリパラメータを設定しました。
@GetMapping("/getStatsList") public JsonNode getStatsList() throws URISyntaxException { RestTemplate restTemplate = new RestTemplate(); // 1. エンドポイントからUriComponentsBuilderを作成する. UriComponentsBuilder builder = UriComponentsBuilder.fromUriString(URL + "/getStatsList"); // 2. クエリパラメータを設定して文字列化する. String uri = builder.queryParam("appId", appId) .queryParam("openYears", openYears) .queryParam("statsField", statsField) .queryParam("limit", limit) .toUriString(); // 3. パラメータを設定したURLからRequestEntityを作成する. RequestEntity<Void> requestEntity = RequestEntity.get(new URI(uri)).build(); // 4. exchangeでAPIを呼び出す. ResponseEntity<JsonNode> response = restTemplate.exchange(requestEntity, JsonNode.class); JsonNode jsonNode = response.getBody(); return jsonNode; }
queryParamsでMultiValueMapを使って設定する
public UriComponentsBuilder queryParams(@Nullable MultiValueMap<String, String> params) 複数のクエリパラメーターと値を追加します。 パラメーター: params - パラメーター
UriComponentsBuilderのqueryParamsを使ってクエリパラメータを設定しました。
1つのキーに複数の値を設定できるMap(org.springframework.util.MultiValueMap)
MultiValueMapはよく使うMapとはちょっと違うもののようです。
@GetMapping("/getStatsList") public JsonNode getStatsList() throws URISyntaxException { RestTemplate restTemplate = new RestTemplate(); // 1. エンドポイントからUriComponentsBuilderを作成する. UriComponentsBuilder builder = UriComponentsBuilder.fromUriString(URL + "/getStatsList"); // 2. Mapにクエリパラメータを設定する. MultiValueMap<String, String> params = new LinkedMultiValueMap<>(); params.add("appId", appId); params.add("openYears", openYears); params.add("statsField", statsField); params.add("limit", limit); // 3. Mapでクエリパラメータを設定して文字列化する. String uri = builder.queryParams(params).toUriString(); // ...これ以降は「queryParamでパラメータ名と値を設定する」と同じ...

AWSのSecrets Managerに大切な情報を登録する
認証に使うAPIキーやWebhookに設定したSecretなどをLambda関数で使うことがあります。これらは大切な情報なのでSecrets Managerに登録して、Lambda関数から取得して使うようにします。
- AWSのコンソール > [Secrets Manager]
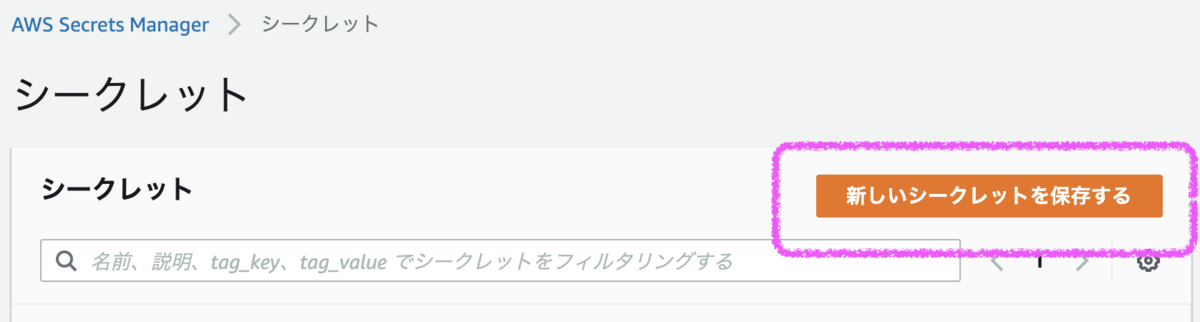
[新しいシークレットを保存する]ボタンから作成画面を表示 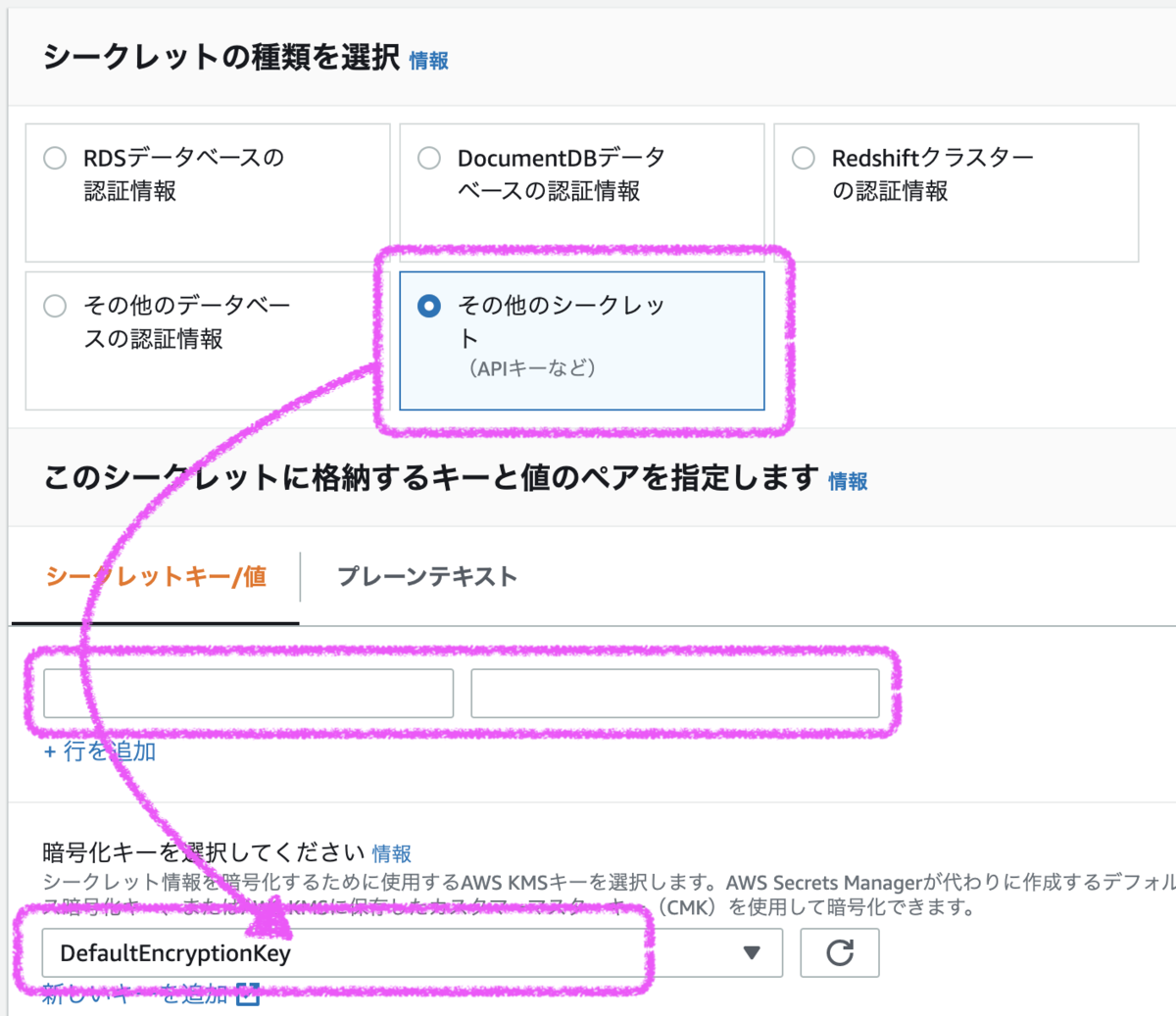
各値を設定して[次へ]ボタン - シークレットの種類: APIキーや各種ユーザ情報などは「その他のシークレット」を選択
- シークレットのペア: 大切な情報の名前(シークレットキー)と大切な情報の値を設定、複数設定してもOK
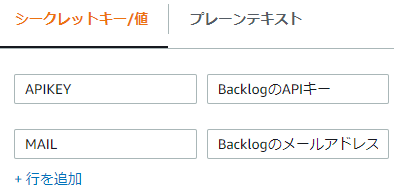
例えばこんな感じです
- 暗号化キー: DefaultEncryptionKey
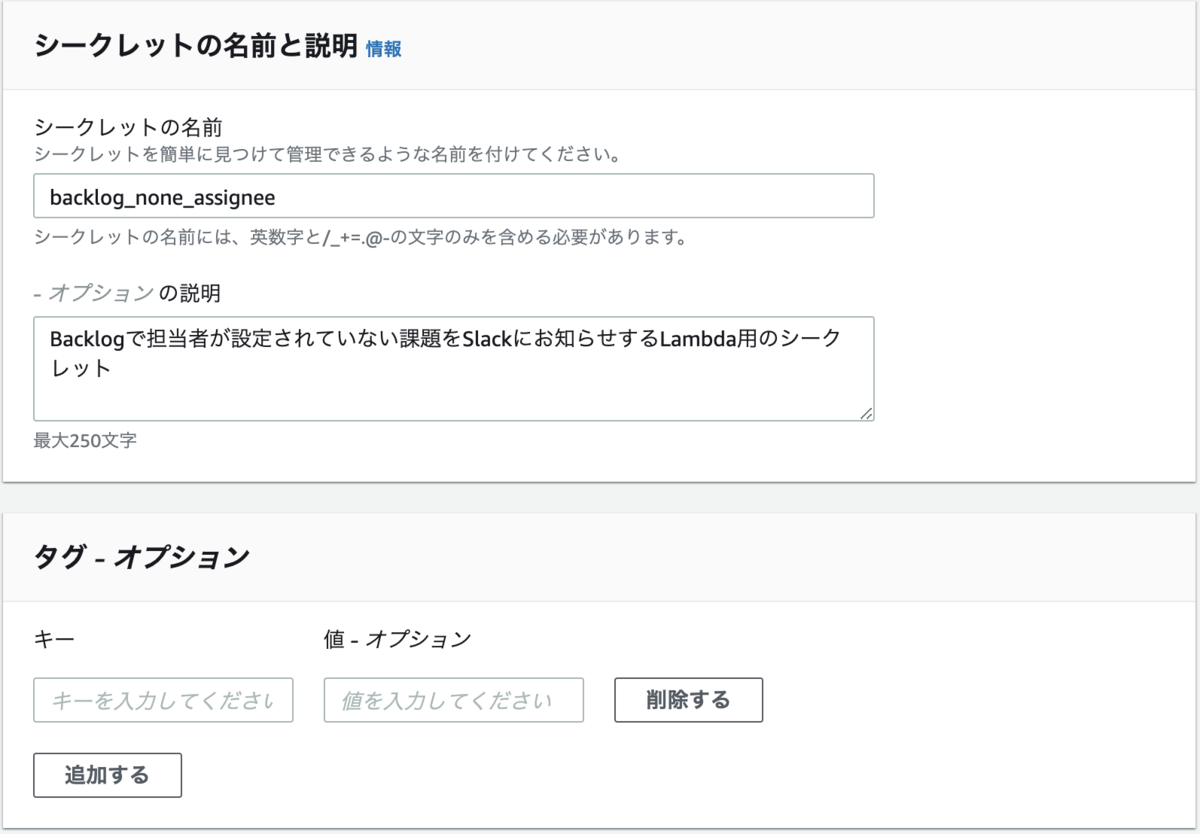
「シークレットの名前」「説明とタグ(任意)」を設定して[次]ボタン 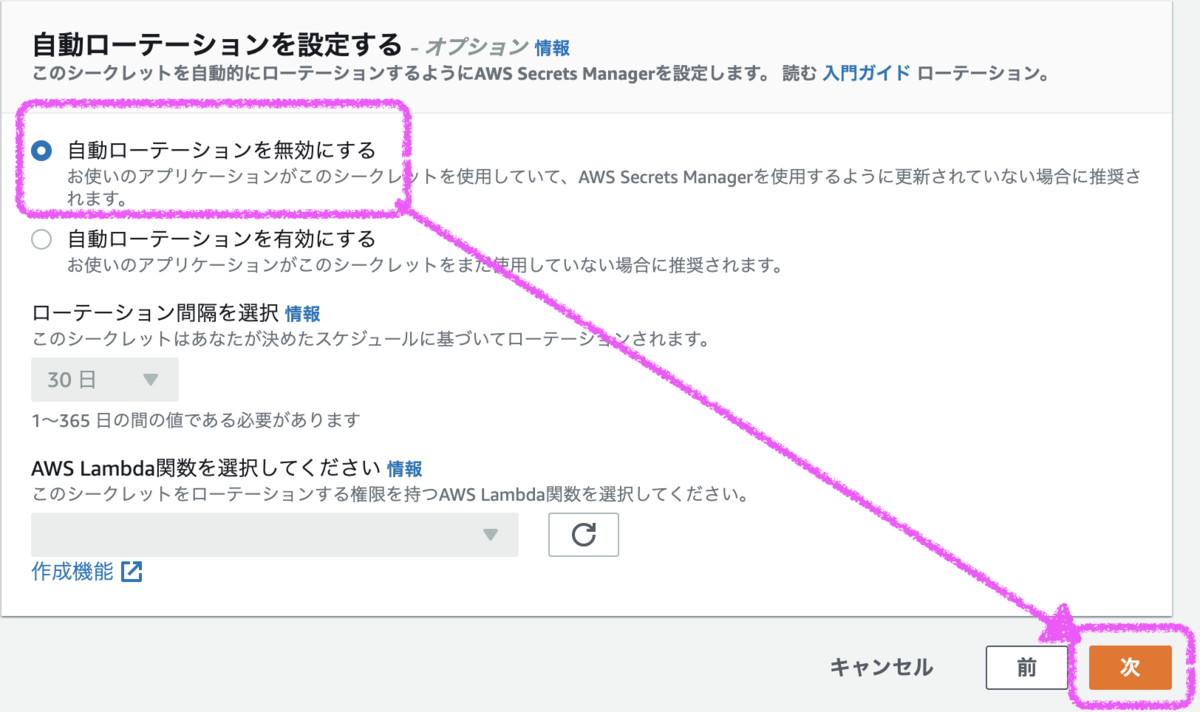
[自動ローテーションを無効にする]を設定して[次]ボタン - [保存]ボタンでシークレットを作成する
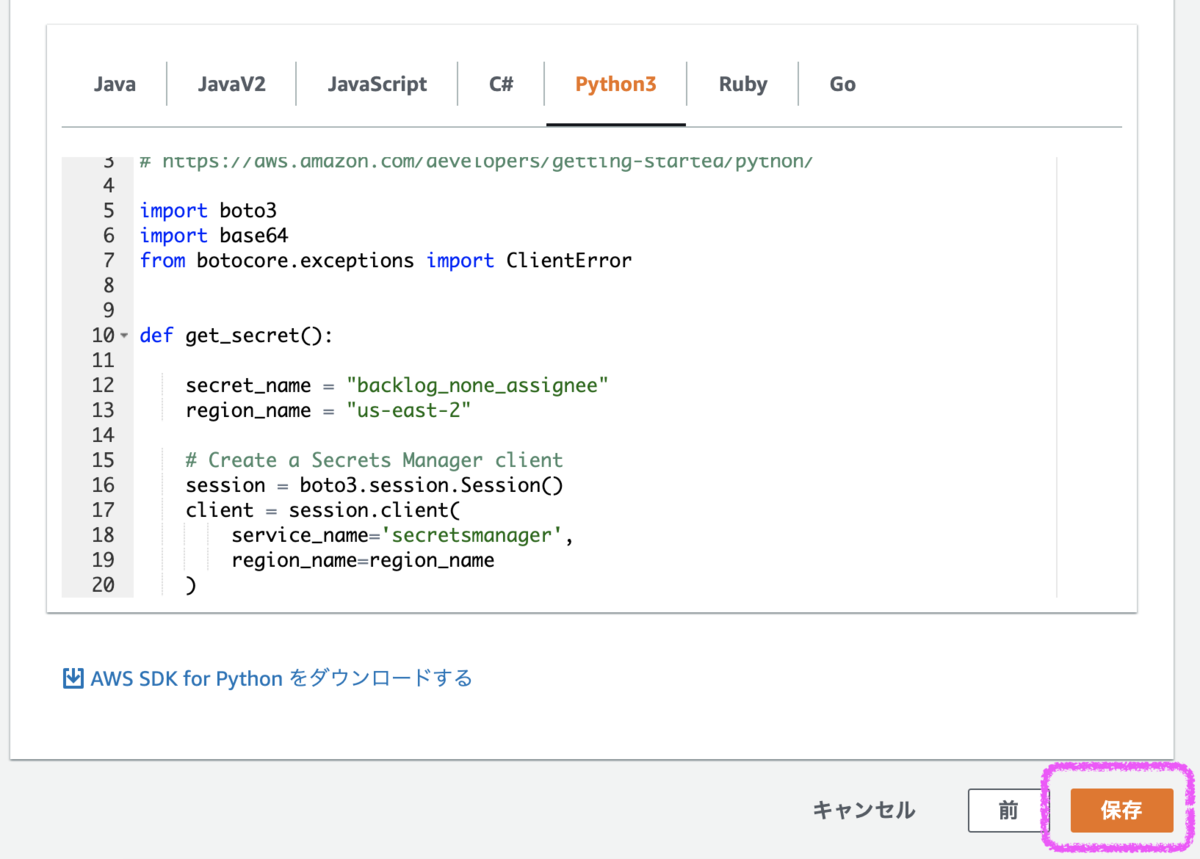
Secrets Managerからシークレットを取得するサンプルコードが表示されて超ありがたいです

AWSのSecrets Managerを使った事例
Lambdaの実行権限とAPI Gatewayを作成する
ポリシーがよくわからないのでちょっと勉強します。

IAMのポリシーを作成する
- AWSマネジメントコンソールにある[IAM] > サイドメニューの[ポリシー]
- [ポリシーの作成]ボタンで作成画面を開きます。
- [JSON]タブを開いて権限の設定内容を入力します。
- [次のステップ:タグ]ボタンから次の画面でタグを設定(設定しなくてもOK) > [次のステップ:確認]ボタン
- 確認画面へ遷移して[名前(必須)]と[説明(任意)]を入力します。
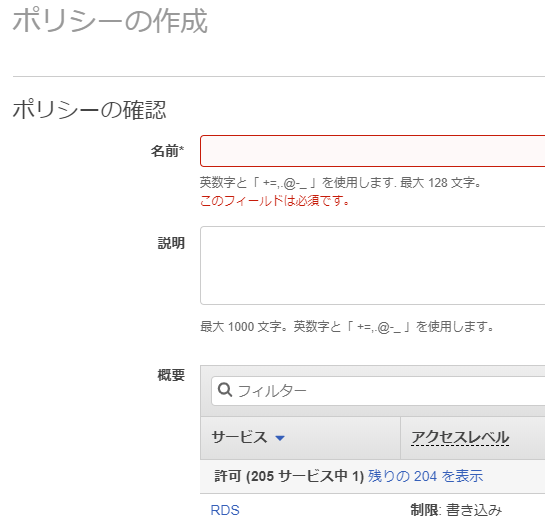
確認画面
- [ポリシーの作成]ボタンでポリシーを作成して一覧画面に戻ります。
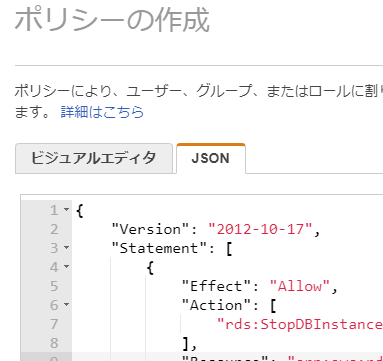
IAMのロールを作成する
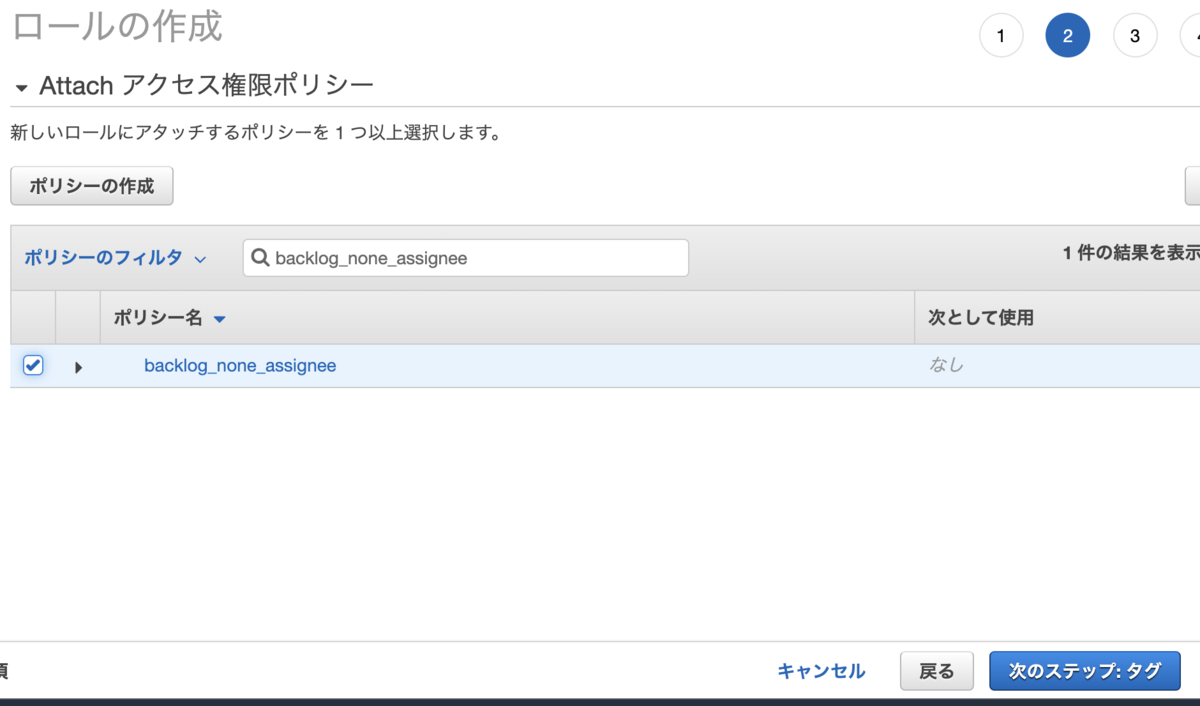
- AWSマネジメントコンソールにある[IAM] > サイドメニューの[ロール]
- [ロールの作成]ボタンで作成画面を開きます。
- [AWSサービス] > [Lambda]を選択後に[次のステップ: アクセス権限]ボタンで次の画面を開きます。
- [Attach アクセス権限ポリシー]の[ポリシーのフィルタ]で作成したポリシーを検索して選択後に[次のステップ: タグ]ボタンで次の画面を開きます。
- [タグの追加 (オプション)]は任意なので設定せずに[次のステップ: 確認]ボタンで確認画面を開きます。
- [ロール名]を入力して[ロールの作成]ボタンでロールを作成して一覧画面に戻ります。


Lambda関数を作る
実装を後回しにして関数だけ作ります。
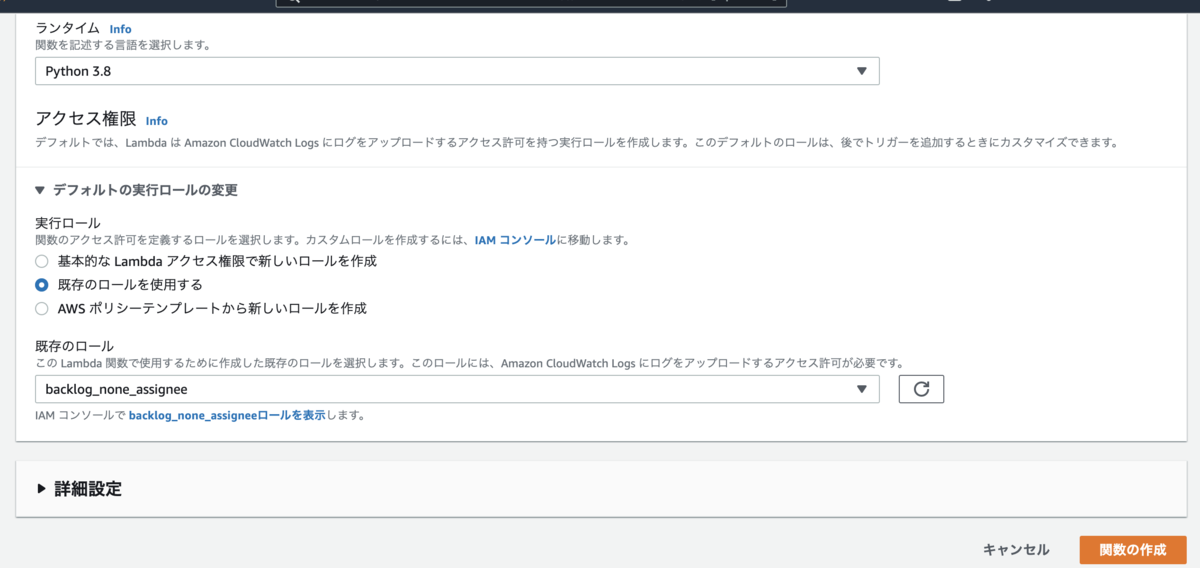
- [AWS マネジメントコンソール]から[Lambda]の画面を開く
- [関数の作成]ボタンで作成画面を表示する
- [一から作成]を選択して以下を設定して[関数の作成]ボタンで関数を作成する
- 関数名 : 任意の名前
- ランタイム : 使いたいもの
- 実行ロール : 既存のロールを使用する
- 既存のロール : 作成したロールを選択
コードには初期コードがあるのでそのまま。実装はAPI Gateway作成後にやります。
import json def lambda_handler(event, context): # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }
API Gatewayを作成する
- 参考
作成する種類は上記の参考リンクを読んで決めました。

HTTP APIで作成する
- [HTTP API]の[構築]ボタンで次の画面へ
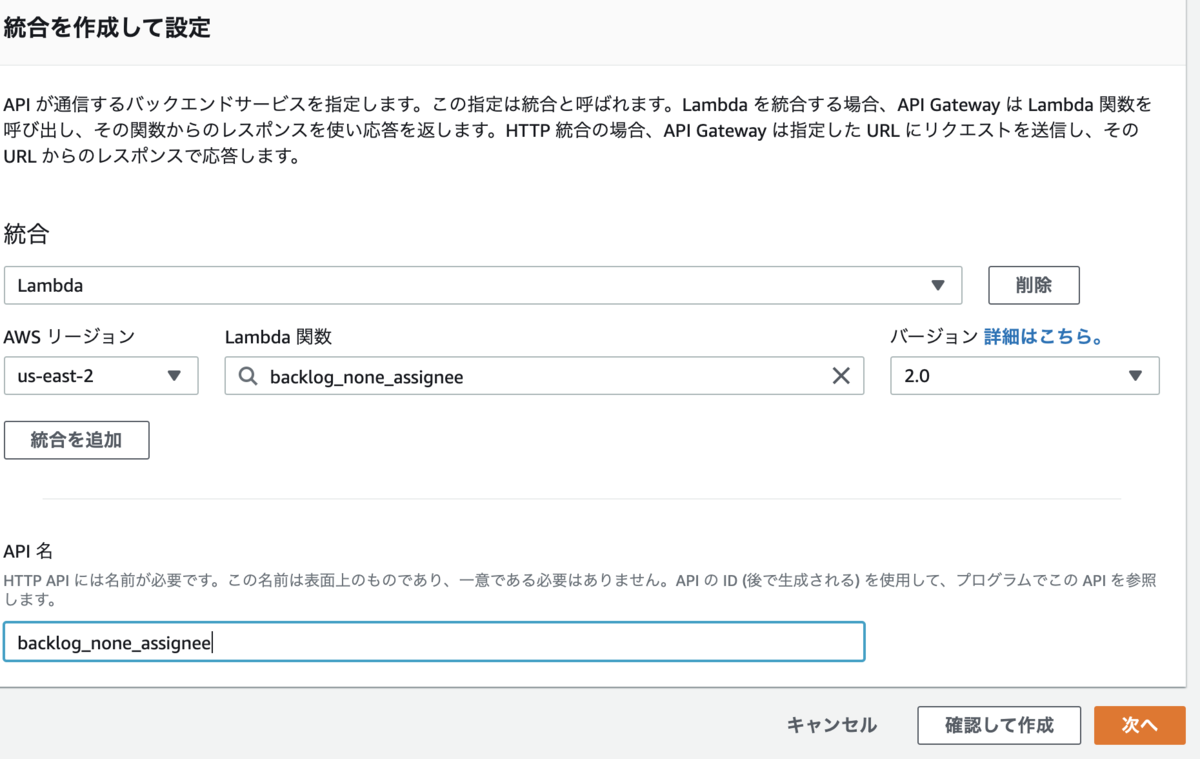
- [統合を追加] > [Lambda] > [Lambda 関数]で作成したLambda関数を選択
- [API 名]に任意の名前を設定して[次へ]ボタンで[ルートを設定]画面へ
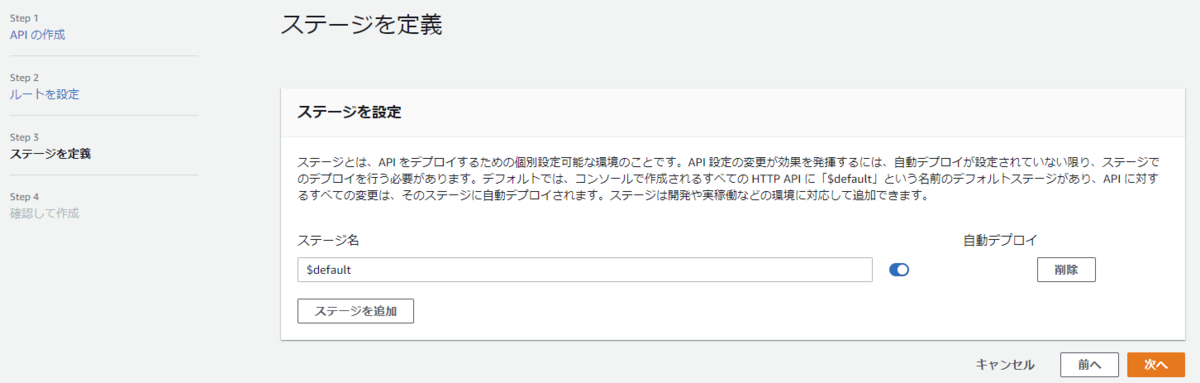
- 以下を設定して[次へ]ボタンで[ステージを定義]画面へ
- メソッド : POST
- リソースパス :
/{Lambda関数名} - 統合ターゲット : {Lambda関数名}

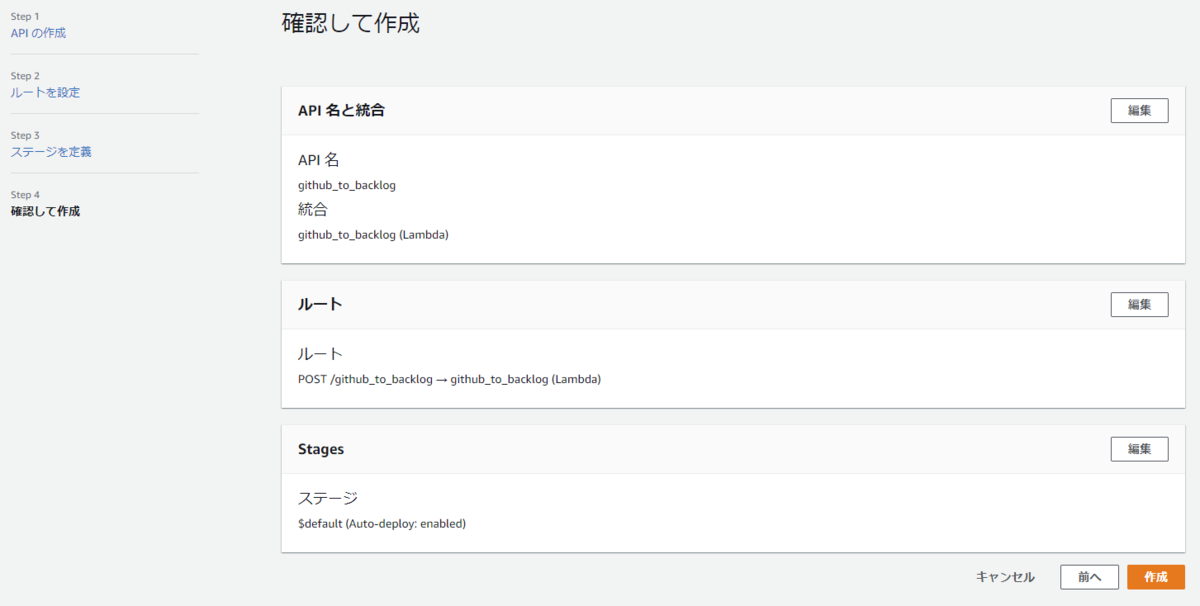
- [ステージを追加]ボタンで以下を追加して[次へ]ボタンで[確認して作成]画面へ
- ステージ名 :
$default - 自動デプロイ : ON
- ステージ名 :
- [作成]ボタンで作成する
- 「{Lambda関数名}のステージ」一覧の[URLを呼び出す]列に「呼び出しURL」が表示される
- curlコマンドを使ってAPI Gatewayを呼び出してAPI GatewayがLambda関数を呼び出せることを確認する
| curlコマンドのオプション | 意味 |
|---|---|
| -X | HTTPメソッドを指定する |
| -H | HTTPヘッダを指定する |
# Lambda関数の初期コードに書いてある「Hello from Lambda!」が返却される $ curl -X POST -H 'Content-Type:application/json' {呼び出しURL}/{リソースパス} % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed } 100 20 100 20 0 0 50 0 --:--:-- --:--:-- --:--:-- 50"Hello from Lambda!" # 失敗例) 「リソースパス」をくっつけ忘れると「Not Found」になるので注意 $ curl -X POST -H 'Content-Type:application/json' {呼び出しURL} % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 23 100 23 0 0 287 0 --:--:-- --:--:-- --:--:-- 291{"message":"Not Found"}
Cloud9のPython環境を作る
最初「Cloud9を作成する」と書いて思いました。Cloud9を作っているのはAWSでぽんすけにそんな能力は塵ほどもありません。作るのは「Cloud9の環境」です。
Cloud9の環境を作る
- AWSのマネジメントコンソール > [Cloud9] > [Create enviroment]ボタン
- [Name]に環境名を入力 > [Next step]ボタン
- 設定項目を選択(VPCやSubnetも設定できる) > [Next step]ボタン
- 内容を確認 > [Create enviroment]ボタン > しばし待つ
- できた!

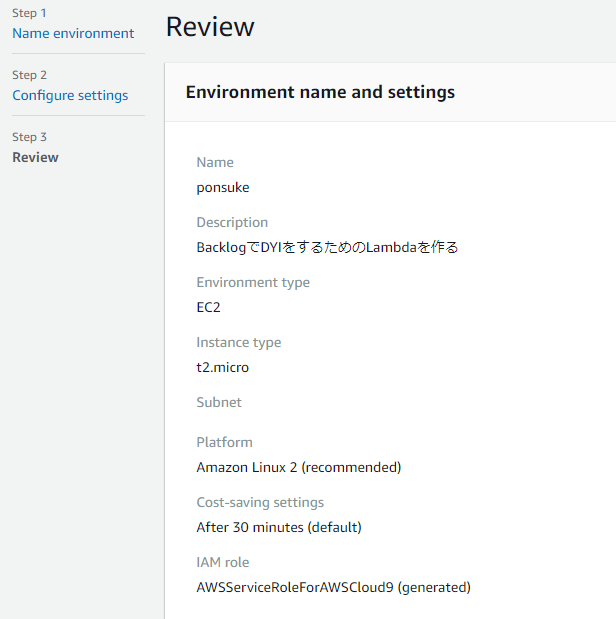
設定項目例
| 設定項目 | 設定値 | 参考になりそうなサイト |
|---|---|---|
| Environment type | Create a new EC2 instance for environment (direct access) | |
| Instance type | t2.micro (1 GiB RAM + 1 vCPU) | |
| Platform | Amazon Linux 2 下の表を参考に決める |
Amazon Linux は何系のディストリビューションに該当するのか – Amazon Web Service(AWS)導入開発支援 |
| Cost-saving setting | After 30 minutes(default) | 【AWS Cloud9 の使い方】最初に覚えておくべき機能まとめ | 初心者向け完全無料プログラミング入門 |
| Platform | 似たようなOS | デフォルトのPython |
|---|---|---|
| Amazon Linux | RHEL5-6 / CentOS5-6 | Python3.6 |
| Amazon Linux 2 | RHEL7 / CentOS7 | Python3.7 |
| Ubuntu Server | Ubuntu | わかったら書く |

Pythonとpipのバージョンを設定する
Cloud9の環境によってPythonやpipのバージョンは違うので、使いたいバージョンに設定していきます。
# Pythonのバージョンは3.8がいいな $ python -V Python 3.7.9 # pipも古いな・・・・ $ python -m pip -V pip 9.0.3 from /usr/lib/python3.7/site-packages (python 3.7)
pyenv使ってバージョンをPython3.8にする
参考 : pyenvのインストール、使い方、pythonのバージョン切り替えできない時の対処法 - Qiita
# pyenvをGitHubからCloneする $ git clone https://github.com/pyenv/pyenv.git ~/.pyenv Cloning into '/home/ec2-user/.pyenv'... remote: Enumerating objects: 67, done. remote: Counting objects: 100% (67/67), done. remote: Compressing objects: 100% (54/54), done. remote: Total 18814 (delta 26), reused 20 (delta 7), pack-reused 18747 Receiving objects: 100% (18814/18814), 3.80 MiB | 16.20 MiB/s, done. Resolving deltas: 100% (12760/12760), done. # バージョンを確認する $ ~/.pyenv/bin/pyenv --version pyenv 1.2.23 # .bashrcに $ vi ~/.bashrc # PATHを通す & pythonの実行パスの差し替えられるように設定して、 $ cat ~/.bashrc | grep pyenv export PATH="$HOME/.pyenv/bin:$PATH" eval "$(pyenv init -)" # 反映する $ source ~/.bashrc # PATHを確認して $ printenv PATH | sed -e 's/:/:\n/g' | grep pyenv /home/ec2-user/.pyenv/shims: /home/ec2-user/.pyenv/bin: # バージョンを確認する $ pyenv --version pyenv 1.2.23 # インストールできるPython3.8を確認する $ pyenv install -l | grep 3.8. 3.8.0 3.8-dev 3.8.1 3.8.2 3.8.3 3.8.4 3.8.5 3.8.6 3.8.7 miniconda-3.8.3 miniconda3-3.8.3 miniconda3-3.8-4.8.2 miniconda3-3.8-4.8.3 miniconda3-3.8-4.9.2 # Python3.8.7をインストールする $ pyenv install 3.8.7 Downloading Python-3.8.7.tar.xz... -> https://www.python.org/ftp/python/3.8.7/Python-3.8.7.tar.xz Installing Python-3.8.7... WARNING: The Python bz2 extension was not compiled. Missing the bzip2 lib? Installed Python-3.8.7 to /home/ec2-user/.pyenv/versions/3.8.7 # Yumをアップデートして、 $ sudo yum -y update ...省略... Complete! # PythonのインストールでWARNINGになった不足なものをインストールする $ sudo yum -y install bzip2 Loaded plugins: extras_suggestions, langpacks, priorities, update-motd 229 packages excluded due to repository priority protections Package bzip2-1.0.6-13.amzn2.0.2.x86_64 already installed and latest version Nothing to do # Python3.8に切り替える $ pyenv versions * system (set by /home/ec2-user/.pyenv/version) 3.8.7 $ pyenv global 3.8.7 # 使いたいバージョンに設定できた! $ python -V Python 3.8.7 $ python -m pip -V pip 20.2.3 from /home/ec2-user/.pyenv/versions/3.8.7/lib/python3.8/site-packages/pip (python 3.8)

プロジェクト設定をする
- 歯車マーク > [Preferences] > [Project Settings]
- [Code Editor (Ace)]
- [Soft Tabs]:ONにするとタブキーで指定された数のスペースが挿入される
- [On Save, Strip Whitespace]:ONにすると保存でファイルから不要なスペースとタブを削除する
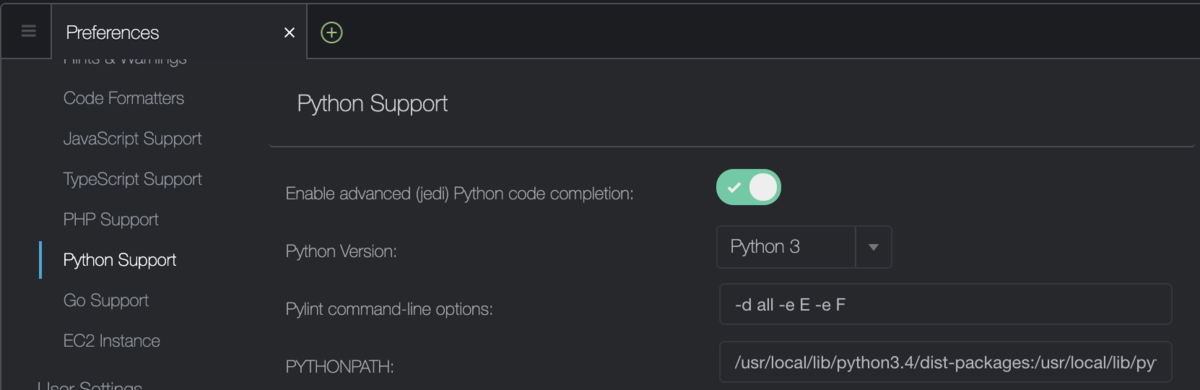
- [Python Support]
- [Enable advanced (jedi) Python code completion]:ONにするとコードが補完を有効になる
基本のライブラリをインストールする
どこでも使いそうな以下をインストールしておきます。
| ライブラリ | 概要 | 参考になるサイト |
|---|---|---|
| wheel | Pythonのパッケージの形式であるwheel(ホイール) | Wheel vs Egg — Python Packaging User Guide ドキュメント |
| ikp3db | Python3でデバックするのに使う | ikp3db · PyPI |
$ python -m pip install wheel Collecting wheel Downloading wheel-0.36.2-py2.py3-none-any.whl (35 kB) Installing collected packages: wheel Successfully installed wheel-0.36.2 $ python -m pip install ikp3db Collecting ikp3db Using cached ikp3db-1.4.1.tar.gz (24 kB) Building wheels for collected packages: ikp3db Building wheel for ikp3db (setup.py) ... done Created wheel for ikp3db: filename=ikp3db-1.4.1-cp38-cp38-linux_x86_64.whl size=40854 sha256=ce8b91f29f673387c3b155c9c0d519803df67e34d7eaec552d11038c401203d2 Stored in directory: /home/ec2-user/.cache/pip/wheels/32/db/4b/66c26f1ee8960dc38bf6d62a4d79eb91d8e360e7b1a7ca2137 Successfully built ikp3db Installing collected packages: ikp3db Successfully installed ikp3db-1.4.1 $ python -m pip list Package Version ---------- ------- ikp3db 1.4.1 pip 20.2.3 setuptools 49.2.1 wheel 0.36.2
Lambda関数をインポートする
Lambda関数をCloud9で実装していくためにCloud9の外部で作ったLambda関数をインポートします。
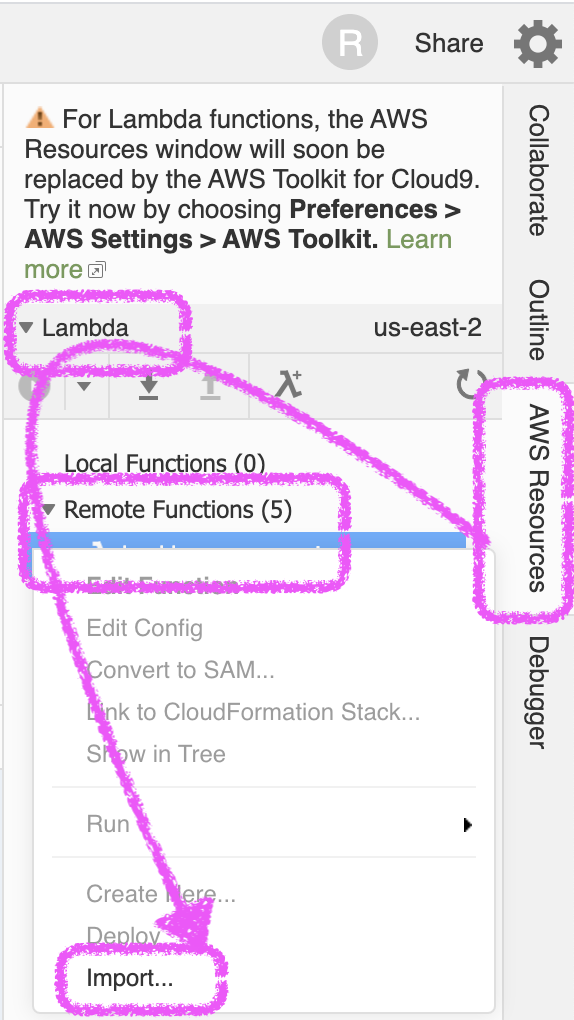
AWS Resourcesを使う場合
[AWS Resources]が表示されない場合は、設定をすることで表示することができます。Cloud9からAWS Resources消失 - Qiitaでやり方を確認してください。
- [AWS Resources] > [Lambda] > [Remote Functions] > 対象のLambda関数を選択して右クリック > [import...]
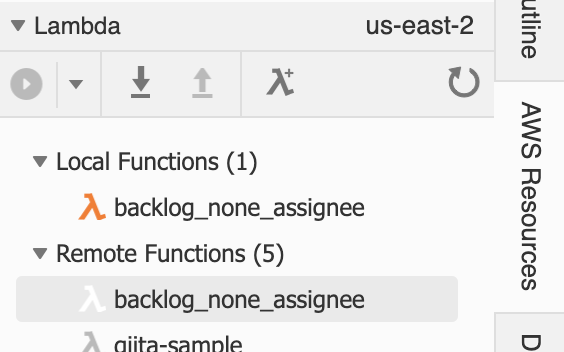
[Local Functions]に追加されました 
[Enviroment]にも追加されました
AWS Toolkitを使う場合
- [AWS] > 対象のリージョン > [Lambda]
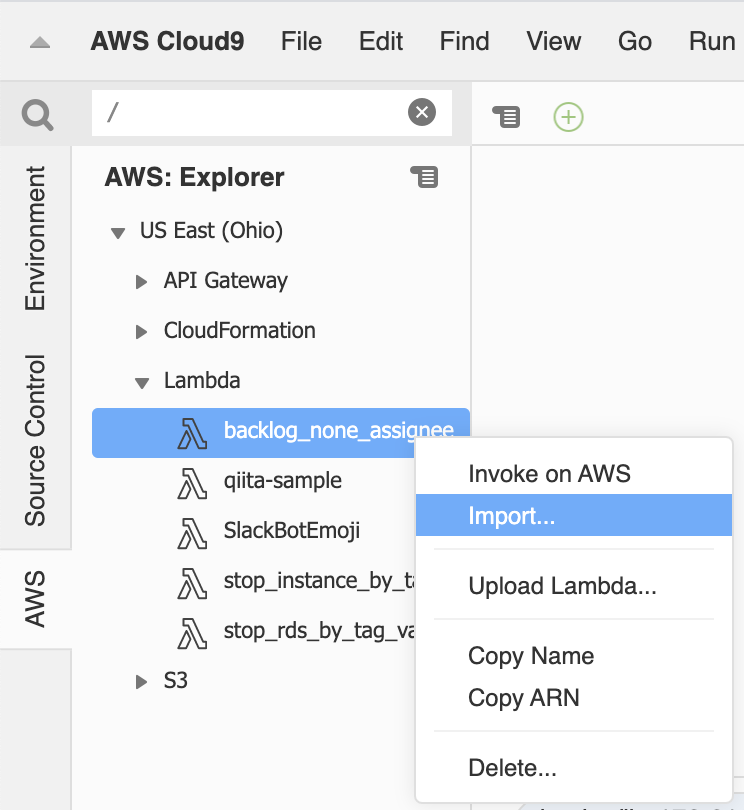
対象の関数を右クリックして[import...]でLambda関数をインポートする 
[Enviroment]のビューを表示するとLambda関数名のディレクトリができている
Lambda関数用にモジュールをインストールする
Lambda関数用にモジュールをインストールする場合は、関数のディレクトリないにインストールします。そうすれば、インストールしたモジュールもろともLambda関数をデプロイすることができます。
# Lambdaのディレクトリに移動する $ cd backlog_none_assignee/ # 場所を指定してパッケージをインストールする(ここではrequests) $ python -m pip install --target=./ requests # 仮想環境にインストールされているパッケージを確認する $ pip freeze certifi==2020.12.5 chardet==4.0.0 idna==2.10 requests==2.25.1 urllib3==1.26.3
とにかくやってみる!Vue.jsに突入し隊
※.このページの内容はとにかく急いで勉強しているので、正確でないことが多々あります。こんな奴いるんだ程度に見てください。
何が何だかわからないので、とにかくやってみます。
初めてすぎて何が何だかわかんない!から公式サイトの説明をそのまま実行してみます。
まずは、さっと基本情報をみておきます。
Node.jsは、JavaScriptをサーバでも動かせるすごい環境です。
Node.js はスケーラブルなネットワークアプリケーションを構築するために設計された非同期型のイベント駆動の JavaScript 環境です。
Vue.jsは、ユーザーインターフェイスを構築するためのフレームワークです。
Vue (発音は /vju:/、view と同様) は、ユーザーインターフェイスを構築するためのプログレッシブフレームワークです。他のモノリシックなフレームワークとは異なり、Vue は少しずつ適用していけるように設計されています。中核となるライブラリはビュー層だけに焦点を当てており、使い始めるのも、他のライブラリや既存のプロジェクトに統合することも容易です。
プログレッシブフレームワークは、必要な時に必要な分だけ使えるようにしたフレームワークです。
プログレッシブフレームワークは,必要になった時に問題解決するライブラリを適宜導入して問題を解決するという姿勢を持っています。最初に始めるときは小さく,大規模になるにつれて適切なライブラリやツールを導入することで大きく対応できる柔軟性を持ちます。不必要な学習コストが発生することもありません。
第1回 プログレッシブフレームワーク Vue.js:Vue.js入門 ―最速で作るシンプルなWebアプリケーション|gihyo.jp … 技術評論社

Vue.jsをとにかくやってみる
とにかく突貫でやるので、Vue.jsはインストールせずにCDNを使います。
プロトタイピングや学習を目的とする場合は、以下のようにして最新バージョンを利用できます:
<script src="https://unpkg.com/vue@next"></script>
はじめに
はじめに | Vue.jsをやってみます。

ここで新しい属性が出てきました。v-bind 属性はディレクティブと呼ばれます。ディレクティブは Vue によって提供された特別な属性であることを示すために v- 接頭辞がついています。
ひたすら読んで書き写して実行して各ディレクティブを体感しました。
| ディレクディブ | 意味 | 参考サイト |
|---|---|---|
| v-bind | レンダリングされた DOM に特定のリアクティブな振る舞いを与える | |
| v-on | イベントリスナをアタッチしてインスタンスのメソッドを呼び出す | |
| v-model | フォームの入力とアプリケーションの状態を双方向にバインディングする | |
| v-if | ブロックを条件に応じて描画 | 条件付きレンダリング — Vue.js |
| v-for="要素 in 配列" | 配列に基づいて、アイテムのリストを描画 | リストレンダリング — Vue.j |
アプリケーションインスタンス
dataのプロパティは、インスタンスが作成時に存在した場合にのみ リアクティブ (reactive) です。次のように新しいプロパティを代入すると:
vm.b = 'hi'
bへの変更はビューへの更新を引き起こしません。あるプロパティがのちに必要であることがわかっているが、最初は空または存在しない場合は、なんらかの初期値を設定する必要があります。


インスタンスのライフサイクル表がありました。頑張って覚えていきます。


初めてPostmanを使ってみた記録
- Postmanをインストールする
- リクエストを整理するためのCollectionsを作成する
- 環境変数を作成する
- 認証情報をリクエストにくっつける
- リクエストをAPIにおくる
- セッションを設定する(ここは結果としてうまくいきませんでした、またいつか挑戦したいです。)
Postmanをインストールする
リクエストを整理するためのCollectionsを作成する
これからPostmanを使っていくといろんなリクエストを作ることになります。そんなたくさんのリクエストを整理するためのフォルダのようなものがCollectionです。
Postman's collection folders make it easy to keep your API requests and elements organized.
- [Cllections] > [+New Collection] > [Name]にAPIがわかるような名前を指定 > [Create]ボタンでCollectionを作成する
- 作成したCollectionの右にある[...] > [Add Folder] > [Name]にローカル環境がわかるような名前を指定 > [Create]ボタンでフォルダを作成する
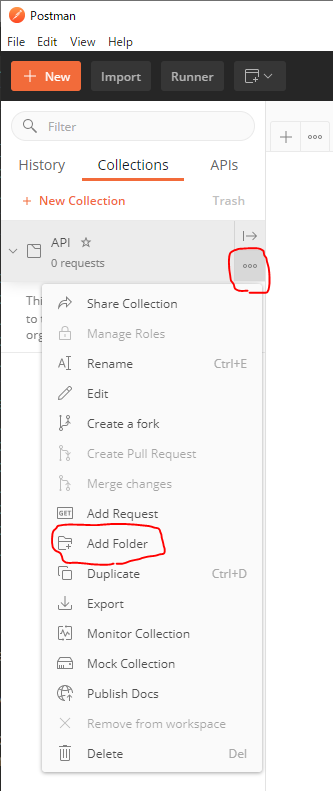

Collectionsにリクエストを追加する
- 環境
- Windows10 Pro バージョン1909
- Postmat v7.36.1
APIにつなぐには認証が必要です。認証に何を使うかAPIによって異なります。初めてのリクエストのサンプルとして、認証してトークンを取得します。
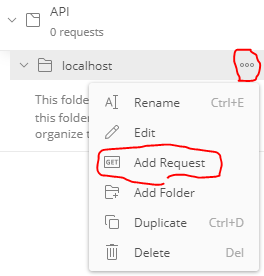
- 作成したフォルダの右にある[...] > [Add Request] > [Name]にやることがわかるような名前を指定 > [Save to {フォルダ名}]ボタンで作成する

HTTPメソッドで「POST」を選択 > APIでトークンを取得するエンドポイントを入力する - APIに合わせて[Parameters]や[Headers]を設定する
- 参考 : APIの開発がむちゃくちゃ捗る「Postman」の使い方 – WPJ
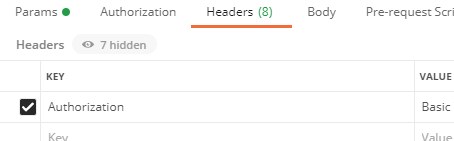
今回のAPIの認証ではSpring SecurityのOAuth2を使っています
- [Send]ボタンでリクエストをおくると[Body]にレスポンスが表示される
環境変数を作成する
APIのURLやらユーザ名やらリクエストにはよく使うものがあります。そんなものは環境変数にして便利に使えるようにします。

画面右上のマークから環境設定ダイアログを表示する 
[Add]ボタンから環境変数セットを追加できる 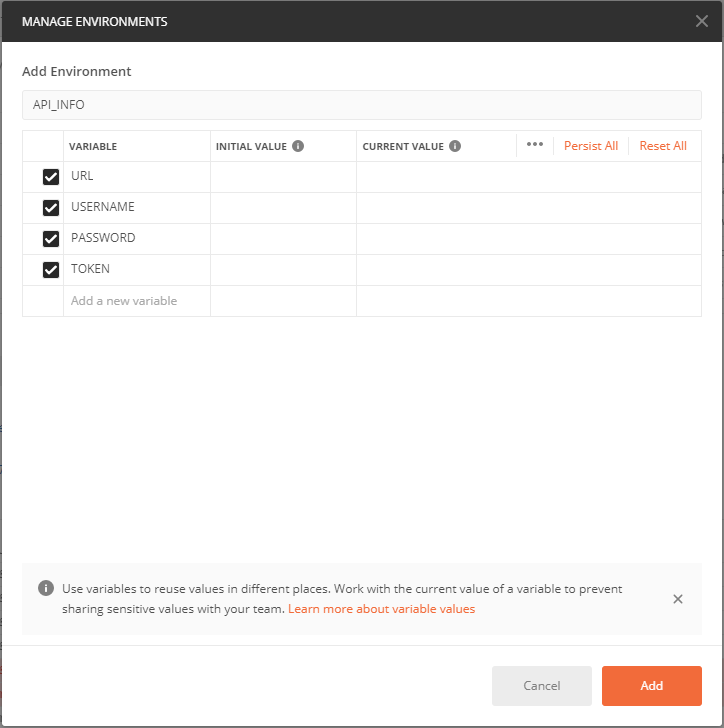
環境変数セットの名前と変数名と値を設定して[Add]ボタンで追加 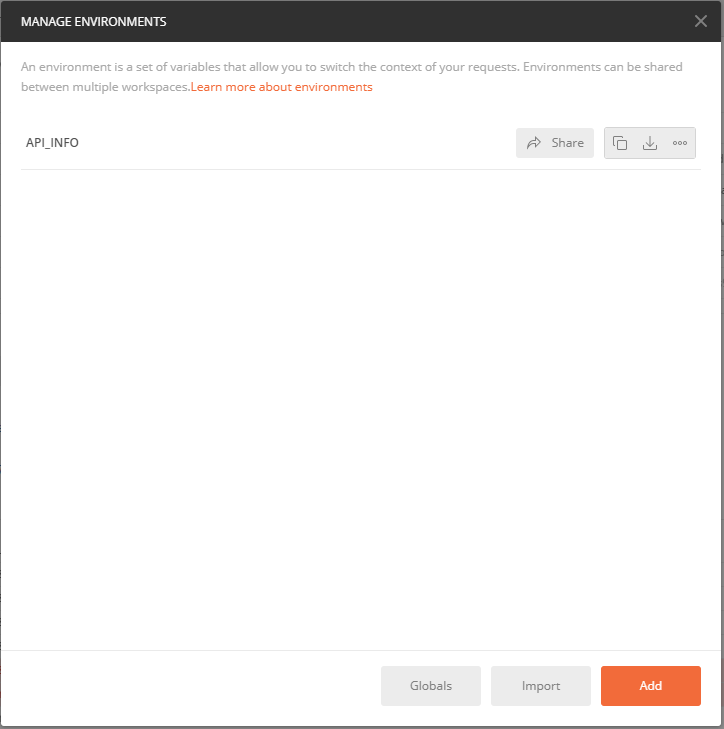
環境変数セットの一覧が表示される 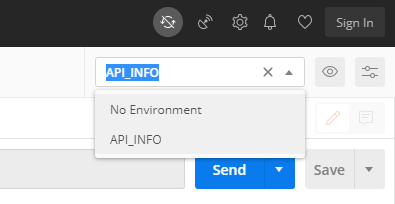
画面右上のプルダウンから作成した環境変数セットの名前を選択する - URLやパラメータの値などで
{{変数名}}の形式で記載すると設定した値が利用される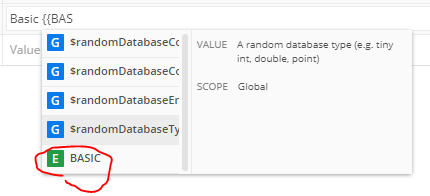
変数名を途中まで入力すると候補が表示されるので便利
なお、INITIAL VALUE と CURRENT VALUE の違いですが、Postman のサーバに情報が送られるか否かになります。
チームでテストしていたり、複数台の PC でテストするときは INITIAL VALUE を使うと便利なのかもしれません。 ですが、検証用 PC は 1台しかないですし、私はボッチですしおすし。(・ω・) セキュリティを高めるためにもっ!CURRENT VALUE を使っています!!! セキュリティを高めるためだからねっ!(大事なことは二度言うスタイル)
任意のCllection専用に環境変数を設定できます。
Postman は変数を使うことができます。変数には Global/Collection/Environment 変数があり、Global は Postman 全体で利用できる変数。Collection は Collection レベルで参照できる変数。Environment は各 Environment(タブ)で利用できる変数です。
- 作成したCollectionの右にある[...] > [Edit]でCollectionの設定ダイアログを開く
- [Variables]タブでCollection専用の環境変数を設定する
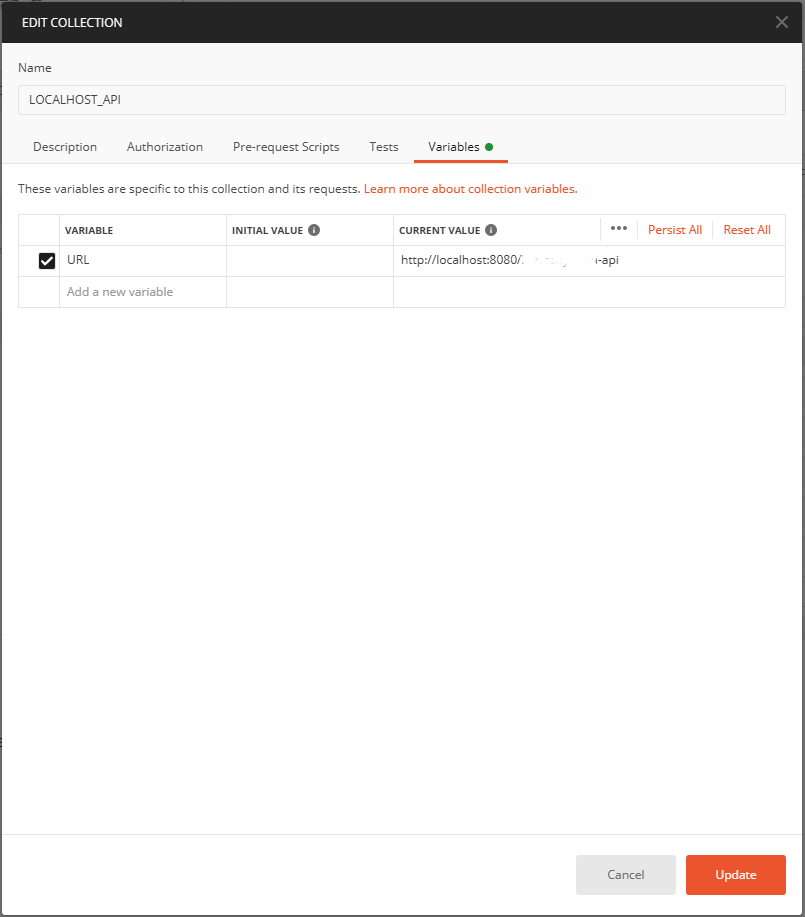
認証情報をリクエストにくっつける
APIにつなぐときに毎回認証情報が必要となることはよくあります。その認証情報をリクエストに自動でくっつけられるようにします。
リクエスト単位で認証を設定することもできますが、API単位でCollectionを作って、API単位で設定することもできます。どちらも[Authorization]タブで設定します。
ヘッダーにBearerトークンをくっつける
先ほどのように取得したトークンをリクエストに設定して認証できるようにします。
Postman を複数環境で使う場合にアクセストークン取得方法を簡略化する | Developers.IOを参考に設定していきます。
- トークンを取得した時と同じようにリクエストを追加する
- [Authorization]タブで設定する
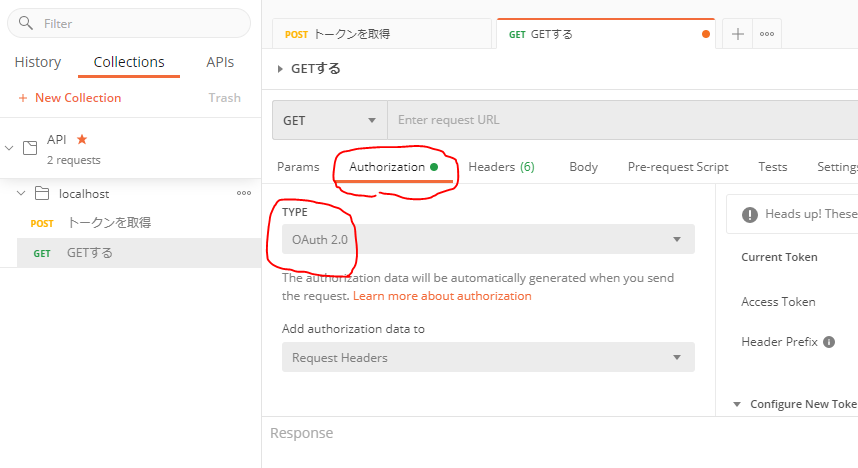
[Type]ではトークンを取得する認証方法を選択する 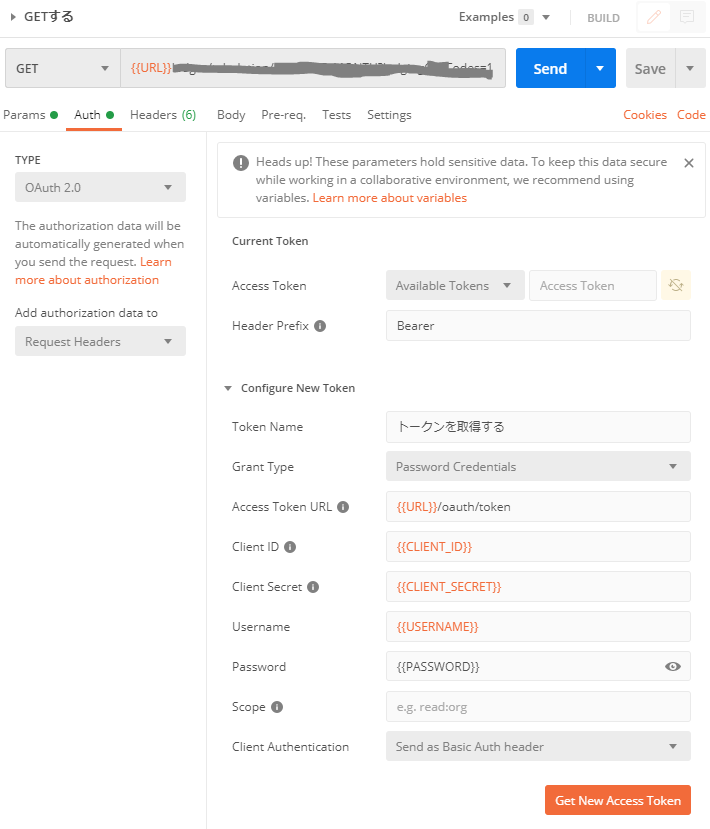
トークンを取得するのに必要な情報やトークンを設定するヘッダ情報などを入力する 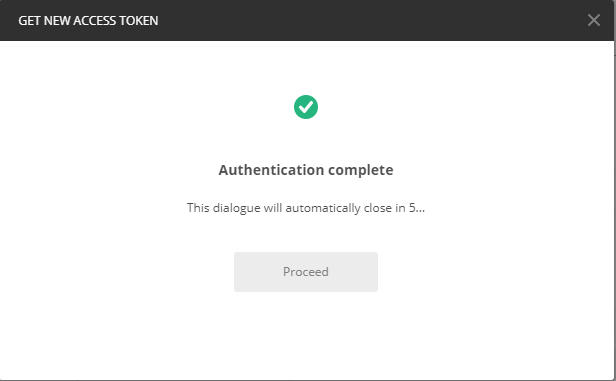
[Get New Access Token]ボタンでトークンを取得して[Proceed]ボタンで進む 
[Use Token]ボタンでリクエストの設定に反映する 
取得したトークンが[Access Token]に反映される
Bearerトークンを直接設定することもできるようですが、トークンの期限切れとなった時に手動で再設定するのは面倒くさいのでOAuth2.0で設定しました。
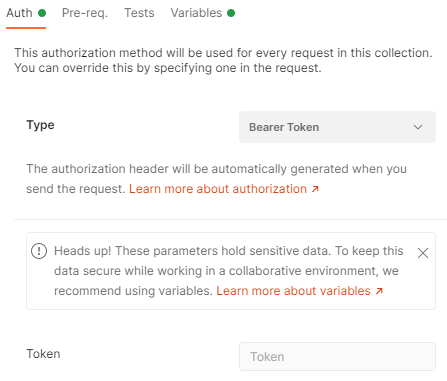
リクエスト単位ではなくCollection単位で認証を設定した場合は、各リクエストの[Authorization]タブの[Type]には「Inherit auth from parent」を設定します。
パラメータにAPIキーをくっつける
認証情報によってはパラメータにくっつけることもあります。
例えば政府統計の総合窓口(e-Stat)のAPIではアプリケーションIDをappIdリクエストパラメータに毎回指定する必要があります。
各APIを利用するには、アプリケーションIDを必ず指定する必要があります。利用登録を行い、アプリケーションIDを取得して下さい。
Collection共通の認証設定としてe-StatのAPIへのリクエストにアプリケーションIDをくっつけます。
Collectionを選択して設定を開く 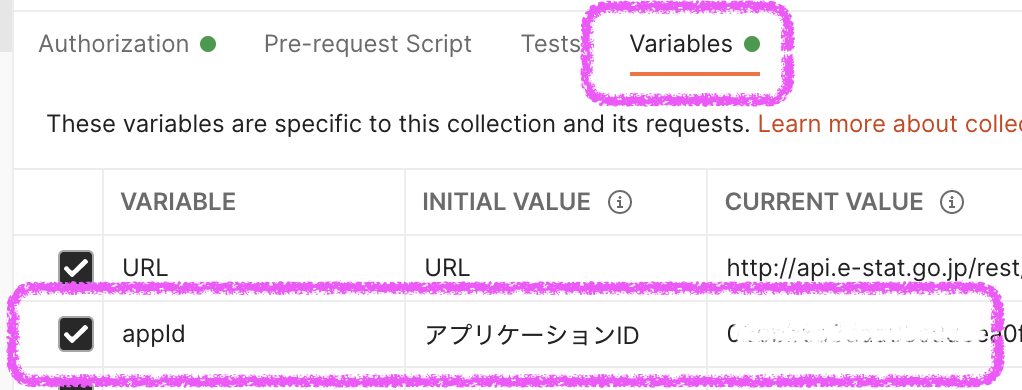
[Variables]で環境変数にアプリケーションIDを設定する 
[Authorization]で[Type]に「API Key」を選択する - 以下を設定して保存する
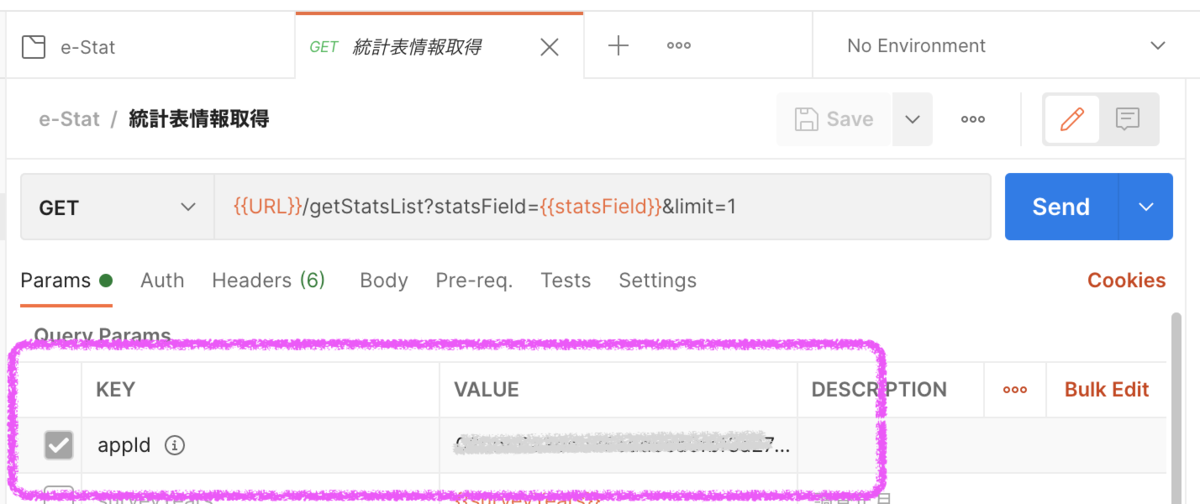
このCollectionのリクエストには自動でアプリケーションIDが設定されるようになった

リクエストをAPIにおくる
ここまでで覚えたことを使っていろんなAPIを使ってみます。
パスパラメータを指定する
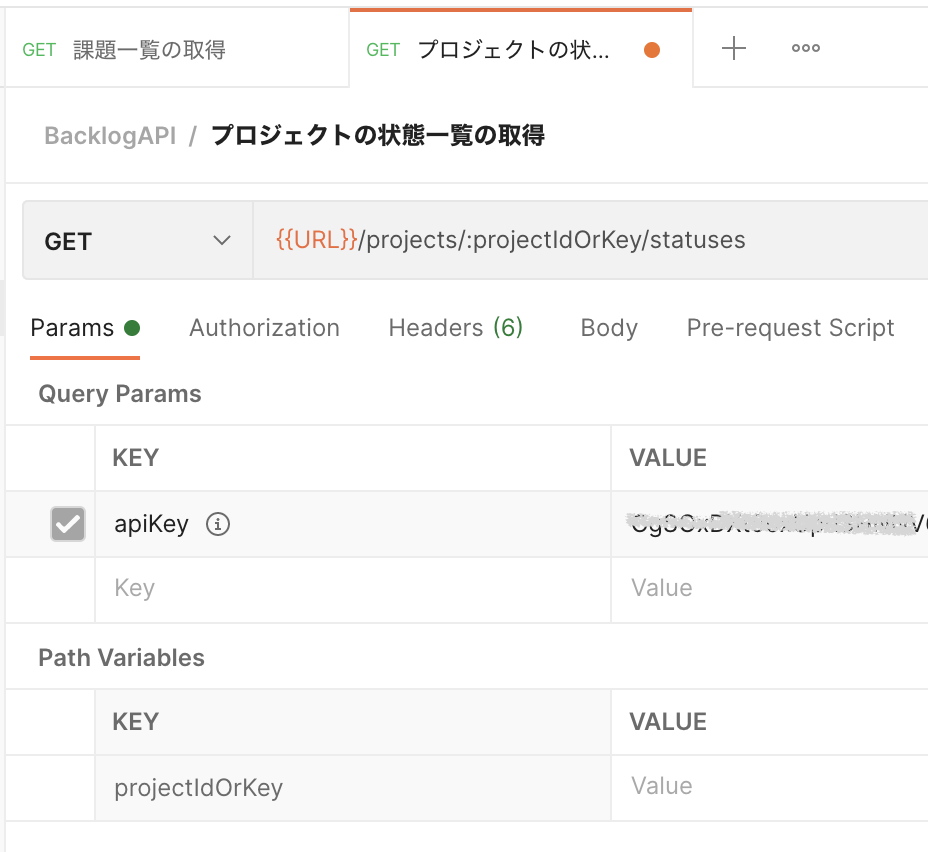
ここではBacklogAPIのプロジェクトの状態一覧の取得 | Backlog Developer API | Nulabをやってみます。
パスパラメータはAPIのエンドポイントのパスに設定されるパラメータです。
URL /api/v2/projects/:projectIdOrKey/statuses
「プロジェクトの状態一覧の取得」の場合はprojectIdOrKeyがパスパラメータになります。
| Parameter Name | Type | Description |
|---|---|---|
| projectIdOrKey | String | Project ID or Project Key |
- (事前準備)使っているBacklogでAPIキーを発行する
- Postmanを起動する
- Backlog用にCollectionsを作成する
- URLとして
{{URL}}/projects/:projectIdOrKey/statusesを入力するとパスパラメータの入力欄が表示される - パスパラメータに取得したいプロジェクトIDを指定する
- [Send]ボタンでプロジェクトの状態一覧の取得 | Backlog Developer API | Nulabの「レスポンスボディ」みたいなのが取れるか確認する
配列形式のクエリパラメータを設定する
Backlog APIを使って課題一覧の取得 | Backlog Developer API | Nulabをやってみます。
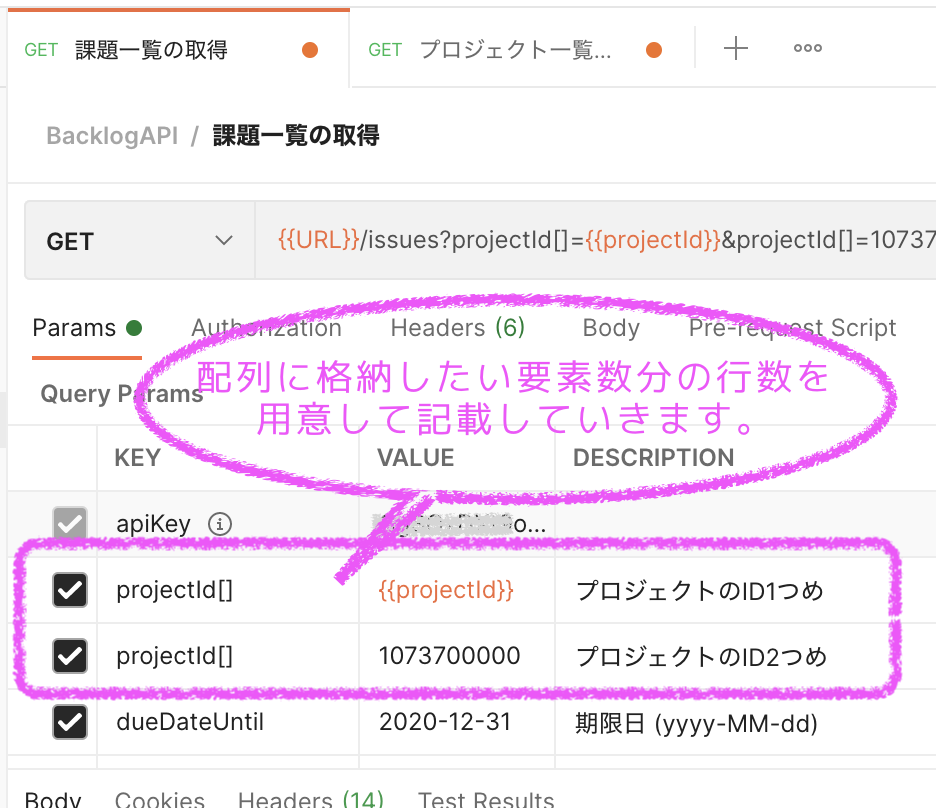
パラメータで配列を指定することがあります。例えばプロジェクトIDの配列する場合にはパラメータ名がprojectIdではなくprojectId[]となり[]がくっ付きます。
今回使ってみる「課題一覧の取得」ではクエリパラメータのに配列を指定します。
以下は「課題一覧の取得」クエリパラメータの一部です(出典 : 課題一覧の取得 | Backlog Developer API | Nulab)。[]がついているのが配列で、[]がついてないのが配列でないものです。
| パラメーター名 | 型 | 内容 |
|---|---|---|
| projectId[] | 数値 | プロジェクトのID |
| issueTypeId[] | 数値 | 種別のID |
| ...省略... | ...省略... | ...省略... |
| keyword | 文字列 | 検索キーワード |
- 使っているBacklogでAPIキーを発行する
- Postmanを起動し、Backlog用にCollectionsを作成して環境変数や認証情報を設定する
- 「課題一覧の取得」用のGETリクエストをCollectionに作成する

URLは「{{URL}}/issues」にするだけでOK
- Query Paramsの[KEY]に
projectId[]を、[VALUE]に1つ目のプロジェクトIDを入力する - 次の行に[KEY]に
projectId[]を、[VALUE]に2つ目のプロジェクトIDを入力する - 他のクエリパラメータを設定する
- [Send]ボタンで課題一覧の取得 | Backlog Developer API | Nulabの「レスポンスボディ」みたいなのが取れるか確認する
セッションを設定する(ここは結果としてうまくいきませんでした、またいつか挑戦したいです。)
呼び出すAPIによっては、画面でログインしてそのセッションを設定て呼び出さねばならないことがあります。そんなときのやり方をやってみました。
Postman InterceptorをChromeに追加する
4. Interceptor(https://www.getpostman.com/docs/capture)
Interceptor機能はChromeを利用して、ブラウザ内で発生したリクエストを自動でPostman Historyに登録する機能です。
- Postman Interceptor - Chrome ウェブストアを表示する
[Chromeに追加]ボタンを押下 
[拡張機能を追加]ボタンで追加する 
拡張機能として追加される - ピンマークを押下するChromeのツールバーにアイコンが表示される

PostmanでリクエストとCookieをキャプチャする
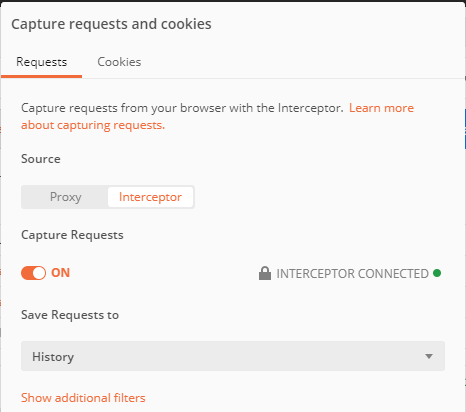
- 右上にある衛星アイコンでダイアログを表示 > [Cokies] > [Install Interceptor Bridge]でInterceptor Bridgeをインストールする
- [Request] > [Source] > 「Interceptor」選択 > [Capture Requests] > ON > [Save Requests to] > 設定対象にしたいCollectionなどを設定
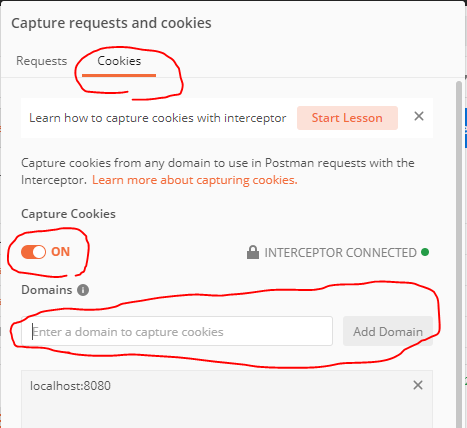
- [Cokies] > [Capture cookies] > ON > [Domains] > 対象のドメインを入力 > [Add Domain]ボタンで追加

Postmanで設定したらChromeのPostman Interceptorアイコンが連動して青くなる


画面からログインしてリクエストを送る

Sublime TextにターミナルとGit環境を作る
Windows
近いうちにやってみよう

Mac
Sublime Textでターミナルを使えるようにする
| 候補のプラグイン | 難点 | 紹介しているサイト |
|---|---|---|
| TerminalView | clearコマンドが使えない |
SublimeText3でターミナルを扱うプラグイン「TerminalView」 | プログラマーを目指す 「中卒」 男のブロ |
| Terminal | 外部でターミナルを開く WindowsはPowerShellになる・・・GitBashがいい |
Sublime Textから手軽にターミナルを開くことができるパッケージ「Terminal」の使い方 |
TerminalViewをインストールする
Sublime Textで完結したいのでTerminalViewをインストールしてみます。
Command + Shift + P> 「install」を入力すると候補が出る > [Package Control: Install Package]選択- 「TerminalView」を入力すると候補が出る > [TerminalView]選択してインストールする
- ターミナルタブを起動する
-
Command + Shift + P> 「terminal」を入力すると候補が出る > [Terminal View: Open Bash Terminal]選択
- ターミナルタブが起動する
ディレクトリを開いているとその場所をカレントディレクトリとして起動します
ショートカットキーを設定する
デフォルトのままだとコピペのショートカットが使えないのでCommand + CとCommand + Vのように設定します。
- [Sublime Text] > [Preferences] > [Package Setting] > [TerminalView] > [Keybindings]
- Userに以下を貼り付けて保存する
[
{"keys": ["command+n"], "command": "new_file", "context": [{"key": "setting.terminal_view"}]},
{"keys": ["command+v"], "command": "terminal_view_paste", "context": [{"key": "setting.terminal_view"}]},
{"keys": ["command+c"], "command": "terminal_view_copy", "context": [{"key": "setting.terminal_view"}]},
]
 ターミナル上でのショートカットが以下表のように変更されます。
ターミナル上でのショートカットが以下表のように変更されます。
| ショートカット | 意味 |
|---|---|
| Command + N | 新規ファイルを開く |
| Command + V | 貼り付け |
| Command + C | コピー |
シェルをBashからZshに変える
TerminalViewのデフォルトはシェルがBashになっています。
使っているMacのターミナルはZshになっているので、合わせてZshにすることで設定(.zshrc)も同じものを読み込めます。
- Zshの場所を確認する
- Sublime Textで
Command + Shift + P> 「terminal」を入力すると候補が出る > [Terminal View: Palette Commands]選択 - User側に以下を記載 > 保存
Command + Shift + P> 「zsh」を入力すると候補が出る > [Terminal View: Open Zsh Terminal]選択- ターミナルタブがZshで起動するようになる
[
{
"caption": "Terminal View: Open Zsh Terminal",
"command": "terminal_view_open",
"args" : {"title": "Terminal (zsh)", "cmd": "/bin/zsh -l"},
},
]

ターミナルにGitのブランチを表示できるようにする
【macOS Catalina】MacのターミナルにGitブランチ名を表示させる | とむじそブログを参考にGitのブランチを表示できるようにします。
今回、こんな感じにしてみました。
# Gitのブランチをターミナルに表示する autoload -Uz vcs_info setopt prompt_subst zstyle ':vcs_info:git:*' check-for-changes true zstyle ':vcs_info:git:*' stagedstr "%F{magenta}!" zstyle ':vcs_info:git:*' unstagedstr "%F{yellow}+" zstyle ':vcs_info:*' formats "%F{cyan}%c%u[%b]%f" zstyle ':vcs_info:*' actionformats '[%b|%a]' precmd () { vcs_info } # ターミナルの表示形式設定 PROMPT=' %F{green}%~%f:%B$vcs_info_msg_0_%b $%f '

解決したい問題
- 実行した内容が画面からはみ出したら見られない・・・スクロールとかできない・・・不便。
- 全角文字が見えない入力できない・・・不便

何?Swaggerって?
お仕事で「APIの仕様書をすわっがーで作ってね」って言われました、既存の仕様書はYAMLファイルになっているのですが・・・何?Swaggerって?
- Swaggerは、OpenAPI仕様に基づいてREST APIの仕様書作成から構築を助けてくれるツールです。
- Serversを書く
- 認証を書く
- 共通で使うオブジェクトや構造の定義を書く
- リクエストを書く
- レスポンスを書く
- YAMLファイルに保存する
Swaggerは、OpenAPI仕様に基づいてREST APIの仕様書作成から構築を助けてくれるツールです。
Swagger は RESTful APIを構築するためのオープンソースのフレームワークのことです。「Open API Initiative」という団体がRESTful APIのインターフェイスの記述をするための標準フォーマットを推進していて、その標準フォーマットがSwaggerです。Swaggerには多くの便利なツールが提供されていることもあり、多くのメリットを享受できそうです。
仕様書のフォーマット?
Swaggerは、OpenAPI仕様(以下OAS)と言われる、REST APIを定義するための標準仕様にもとづいて構築された一連のオープンソースツールです。REST APIの設計、構築、文書化、および使用に役立つ機能を提供します。
フォーマットだけじゃなくて、仕様書から構築までできるらしいです。
OpenAPIは、REST APIの記述フォーマットです。
What Is OpenAPI?
OpenAPI Specification (formerly Swagger Specification) is an API description format for REST APIs.
(省略)
What Is Swagger?
Swagger is a set of open-source tools built around the OpenAPI Specification that can help you design, build, document and consume REST APIs.
About Swagger Specification | Documentation | Swagger - swagger.io
弱い英語力から以下程度に解釈しました。
Swagger3.0は、OpenAPI?
OpenAPI は Swagger 3.0
Swagger 3.0 から OpenAPI に名前が変わったため、 OpenAPI 3.0 は Swagger 3.0 でもあります。
もともと他にも API 周りのインターフェース定義ができるルールが存在してたのですが、 Swagger が晴れて標準となったようです。 他には API Blueprint などがあるようですが、僕もそこまで詳しくはありません。 OpenAPI の仕様の、現時点での最新は
3.0.2です。 仕様書はこちらにあります。https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md
Swaggerは、2から3でなにやらずいぶん変わったようですが・・・初めてなのでとにかくSwagger3.0を使えるようになることを優先します。
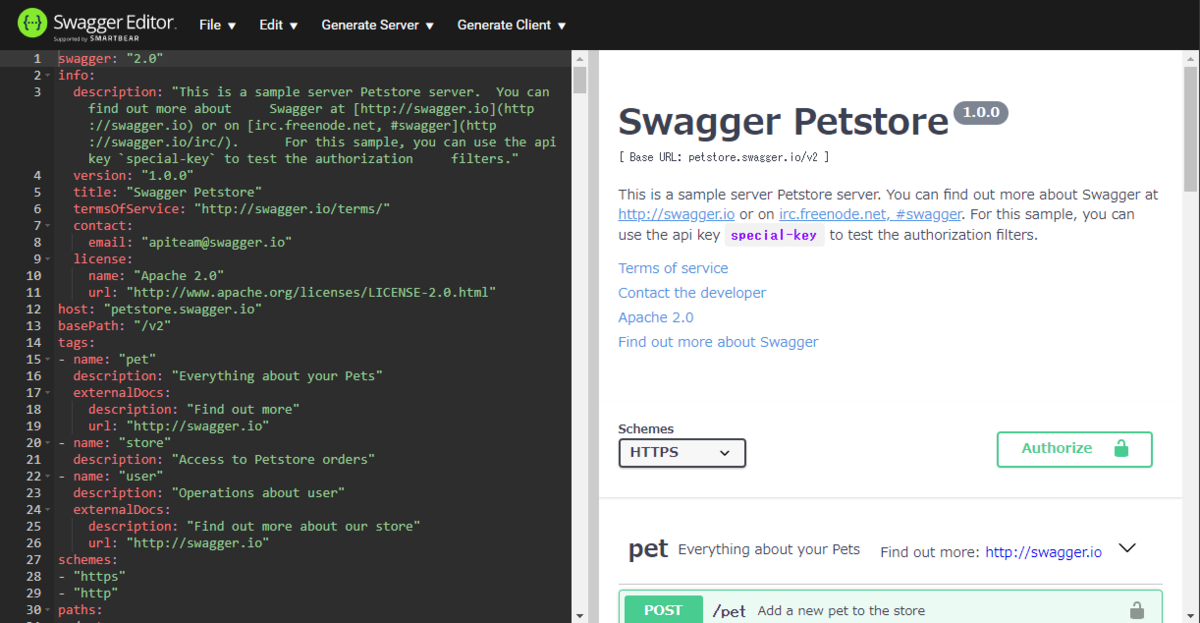
ブラウザで仕様書を見て書けます。
ツールをインストールしたり環境を構築したりしなくてもすぐに使えそうです。
- Swagger Editorをブラウザで表示する
- [File] > [Import file] > 既存の仕様書をインポートする
- 仕様書に定義されたインターフェースが横に見やすく表示された!
- 左のYMLを修正すると右側に反映される
実行もできます。
呼出し先が起動していれば、必要な情報を入力して実行することもできました。
- 仕様書のAPIを起動して接続できるようにする
このボタンを押下すると入力できるようになる - ヘッダやパラメータなど必須になっている項目を入力する
このボタンで実行できる - 「TypeError」になったけれどAPIのログを見てみるとちゃんとAPIを呼び出していた

Server responseにAPIからのレスポンスが表示される
GitにあるSwaggerのファイルをプレビューできるChrome拡張機能があるらしいです。

Serversを書く
APIのサーバを定義します。 サーバには、本番環境やらテスト環境など複数を定義できます。
認証を書く
試しに「OAuth2.0で取得したBearerのトークンをヘッダにAuthorizationで設定する」みたいに書こうとした・・・ら、なんか言われました。
Header parameters name "Authorization" are ignore. Use the `securitySchemes` and `security` sections instead to define authorization.
 どうやら、ヘッダやパラメータに「Authorization」を設定しても無視されるようです。
どうやら、ヘッダやパラメータに「Authorization」を設定しても無視されるようです。
You have used a restricted value as the name of a header parameter. The values Accept, Content-Type, and Authorization are restricted values and should not be used as the header name. A header with any of these values as the header name is ignored.
Header parameter with the name 'Authorization' is ignored - apisecurity.io
では、どう書くのか?調べながら書いてみました。
Bearer スキームを書く
トークンを利用した認証・認可 API を実装するとき Authorization: Bearer ヘッダを使っていいのか調べた - Qiitaを読むとやりたいことは「Bearer スキーム」というものでした。
- OpenAPI (Swagger) 3.0 で Bearer トークンの使用を定義する | Articles | Riotz.works
- Bearer Authentication - swagger.io
共通で使うオブジェクトや構造の定義を書く
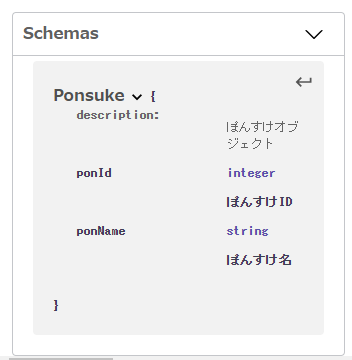
APIのパラメータやレスポンスで共通のオブジェクトや構造を使うことがあります。
そんな共通のオブジェクトや構造は、components配下に定義して$refを使うことで参照できます。
Components Section
Often, multiple API operations have some common parameters or return the same response structure. To avoid code duplication, you can place the common definitions in the global components section and reference them using $ref.
リクエストを書く
各リクエストのエンドポイントは、paths配下に定義していきます。
paths: /{エンドポイント}: summary: {短い説明文} description: > {長い説明文、 ここにはMarkdownで複数行にわたって書くことができます。}
typeに定義するデータ型は、Data Typesに記載されているものを使用します。
| type | 意味 | 参考になりそうなサイト |
|---|---|---|
| string | 文字列 | |
| number | 整数と浮動小数点付き数値 | 浮動小数点って何? - Qiita |
| integer | 整数 | |
| boolean | 真偽値 | |
| array | 配列 | |
| object | オブジェクト |
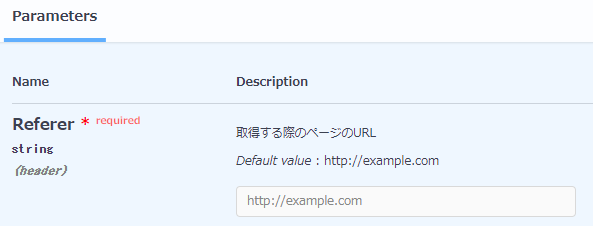
パラメータを定義する
Describing Parameters
In OpenAPI 3.0, parameters are defined in the parameters section of an operation or path. To describe a parameter, you specify its name, location (in), data type (defined by either schema or content) and other attributes, such as description or required.
パラメータといっても種類があります。基本の書き方は同じで- inに指定する値を変えて書き分けます。各パラメータがどんな感じのものかはSwaggerの上記ドキュメントページにサンプルがあってわかりやすいです。
| パラメータの種類 | inに指定する値 | 参考になりそうなサイト |
|---|---|---|
| パスパラメータ | path | |
| クエリパラメータ | query | |
| ヘッダパラメータ | header | HTTP ヘッダー - HTTP | MDN |
| Cookieパラメータ | cookie |
フォーマットはこんな感じです。
parameters: - in: pathかqueryかheaderかcookie name: パラメータ名やヘッダのフィールド名 schema: type: パラメータの型 enum: - パラメータの値が特定の値しか受付ない場合に指定する example: パラメータの例 required: 必須かどうかをboolで指定、パスパラメータは省略できないのでtrueを指定する description: パラメータの説明文 allowEmptyValue: パラメータ名の指定のみで値がなくてもいいかどうかをbookで指定する

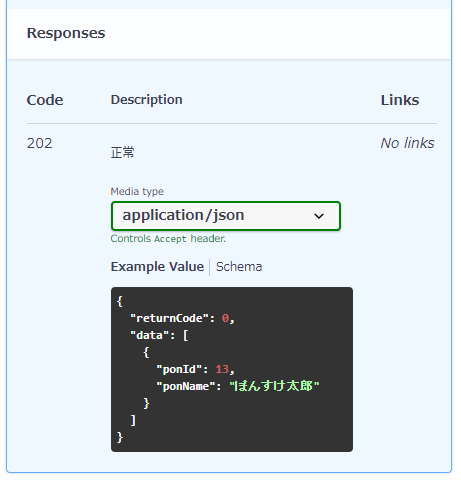
レスポンスを書く
Describing Responses - swagger.ioを参照すると、
各レスポンスは以下のようにresponses配下にHTTPステータスコード毎に定義していくようです。
responses: {ステータスコード}: description: {説明} content: {メディアタイプ}: schema: # ここからレスポンスボディを定義する type: {レスポンスボディのタイプ「object」「array」} properties: {プロパティ名}: type: {プロパティのタイプ} description: {プロパティの説明}
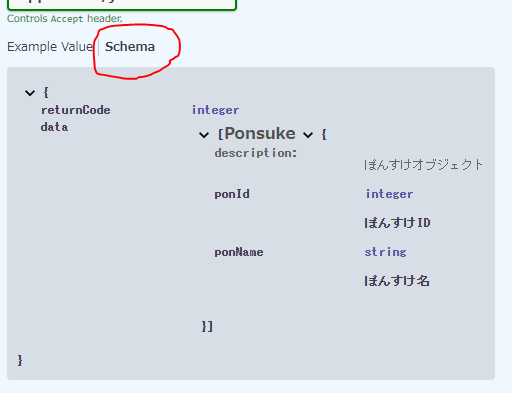
レスポンスのexampleを複数定義する
APIのレスポンスで同じHTTPステータスにexampleを複数定義したいということがあります。そんな場合の書き方です。
Adding Examples - swagger.ioを参考にするとフォーマットはこんな感じです。
paths: #...省略... responses: 'HTTPステータスコード': #...省略... examples: # <<<複数定義する場合は「example」ではなく「s」をつけて「examples」になります。 examples1: summary: 説明文、例えば「データがある場合」 value: # ここ以降にレスポンスの例を記載します。 examples2: summary: 説明文、例えば「データがない場合」 value: # ここ以降にレスポンスの例を記載します。
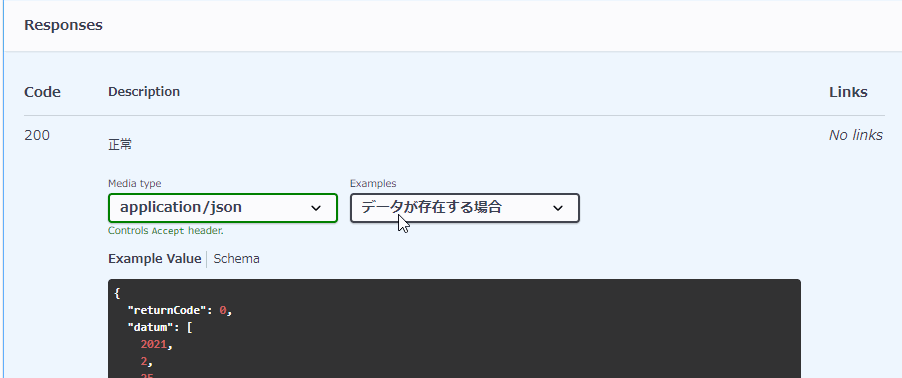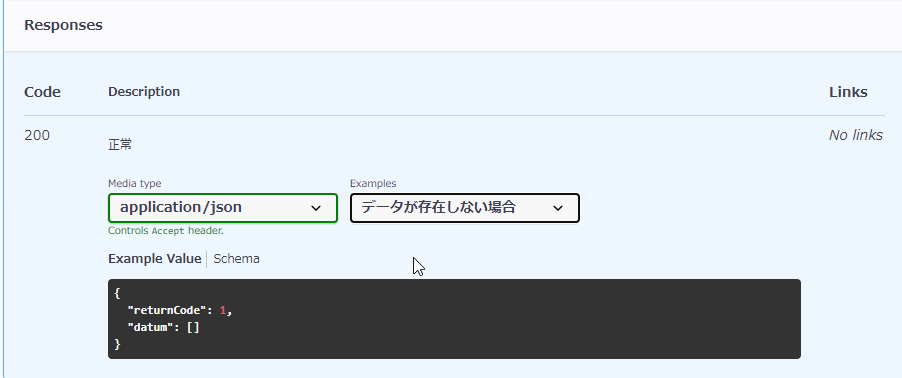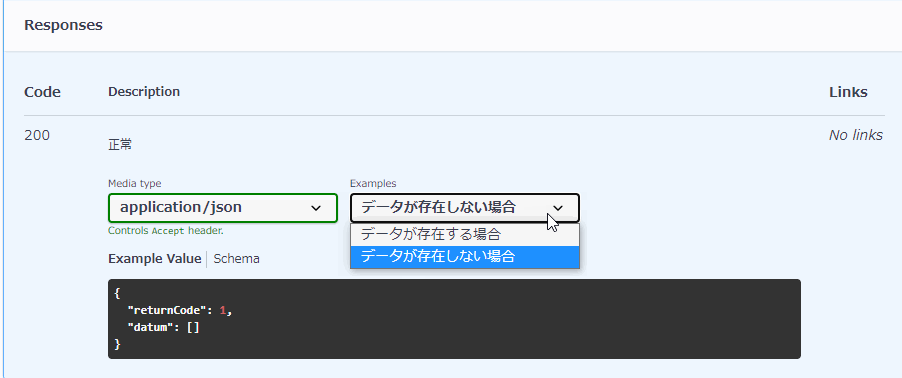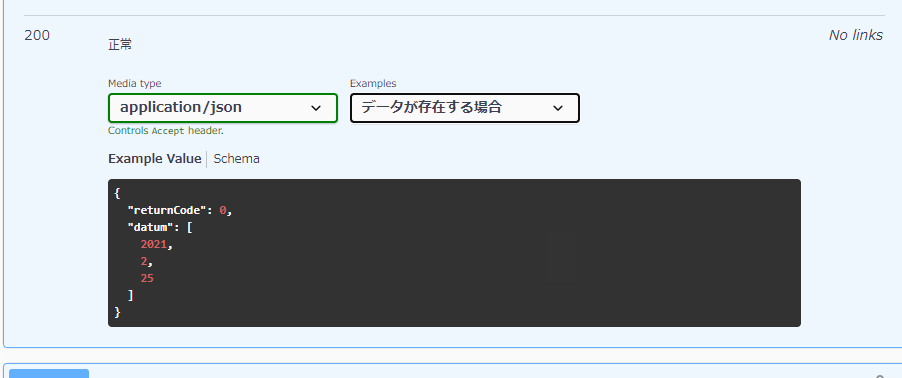
同じHTTPステータスで、exampleだけではなく返却するオブジェクトを複数定義することもできるようです。
Swaggerで、とあるapiのレスポンスにおいて、「同じステータスコードを返すんだけれど、bodyの内容が違う場合がある」時、SwaggerのoneOfという書き方で対応できます。(swagger3.0以上だったはず)
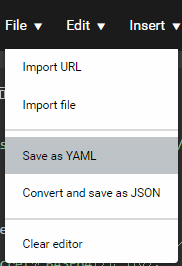
YAMLファイルに保存する
ブラウザ上で書いたものをローカルにダウンロードしてYAMLファイルとして保存します。

はまゆう日記
基本情報
我が家に来た経緯
お向かいさんがはまゆうの種を玄関先で配っていたのでたくさんいただいてみた。

分類
- 学名:Crinum asiaticum L.
- 日本に自生するのは亜種の
Crinum asiaticum var. japonicum
- 日本に自生するのは亜種の
- APG体系 : キジカクシ目
Asparagales> ヒガンバナ科Amaryllidaceae> ハマオモト属Crinum> ハマユウC. asiaticum- クロンキスト体系 : ユリ科
- 別名:浜木綿(ハマユウ)、浜万年青(ハマオモト)
- 常緑 / 多年草 / 半耐寒性
生態 : 鉢植えにして寒くなったら家に入れる
- 温暖な海岸砂地に自生する大形常緑の多年草
- 花茎:約50~100cm(葉:50~80cm)
- でかい・・・うちのぷてぃーとな花壇には入らない・・・
- 葉の間の真ん中から太くてまっすぐな茎を上に伸ばし、先端に白い花弁が25~40個ほど集まって、散形花序を作る
- 根(鱗茎)に有毒なリコリン(アルカロイド)を含む
- 食べるとよだれが出て、吐き気、下痢、血圧低下、中枢神経の麻痺などの症状が現れる
- しかし、ハマオモトヨトウはハマユウを食べる
| 時期 | 補足 | |
|---|---|---|
| 播種 | 種を採取した後すぐ | 種から花が立派につくようになるまで数年かかる |
| 肥料 | 4月(発芽) | 緩効性化成肥料 |
| 苗植え | 4~8月 or 11月 | |
| 花期 | 7~9月 | 花は夕方から開き始め深夜に満開になる。よい香りを放つ |
| 肥料 | 9月(花の終わり) | 緩効性化成肥料 |

(土)赤玉土7:腐葉土3
| 日当たり | 水はけ | 乾燥 | 寒さ | 暑さ |
|---|---|---|---|---|
| 朝から晩まで日陰にならない場所が | 良い | 弱い | 弱い |


MacでJSFのプロジェクトを作る
- 以前、CentOSでJSFのプロジェクトを作ったので今回はMacでつくる
- Eclipseを配置する
- Payaraをインストールする
- Mavenプロジェクトを作成する
- JSFを設定する
- 最初に表示されるページを作成する
- 環境
- macOS Big Sur バージョン11.0.1
- openjdk version "11.0.8" 2020-07-14
以前、CentOSでJSFのプロジェクトを作ったので今回はMacでつくる
CentOSでせっかく作っても・・・Dockerイメージを取らずに、Gitにコミットせずに・・・うっかりEC2インスタンスもろとも削除してしまいました。
というわけでMacで再び作ります。

Eclipseを配置する
- Mac 版 Eclipse Pleiades All in One リリース - Qiitaを参考にEclipseを配置する
- eclipse.iniで以前インストールしたJava11を設定する
| オプション | 意味 | 参考 |
|---|---|---|
| -vm | JVM(Javaプログラムを動かすためのソフトウェア)のパスを設定 | eclipse.iniに-vmを指定する方法 - Qiita |
| --illegal-access=deny | コマンドで起動するときに出るワーニングを抑制 | 警告を出ないようにする - Qiita |
#...省略...以下追記箇所... -vm /usr/local/opt/openjdk@11/bin/java -vmargs --illegal-access=deny #...省略...
Payaraをインストールする
Mavenプロジェクトを作成する
- [パッケージ・エクスプローラー]にカーソルを入れて「Ctrl + N」で新規作成ダイアログを表示する。
- [プロジェクト・エクスプローラー]でもOK
- [Maven] > [Mavenプロジェクト] > [次へ]ボタン
- [シンプルなプロジェクトの作成(アーキタイプ選択のスキップ)]チェックボックスをONにする > [次へ]ボタン
- 以下を設定して[完了]ボタンでプロジェクトを作成する
- GroupId : プロジェクトのルートパッケージ名
- ArtifactId : プロジェクト名
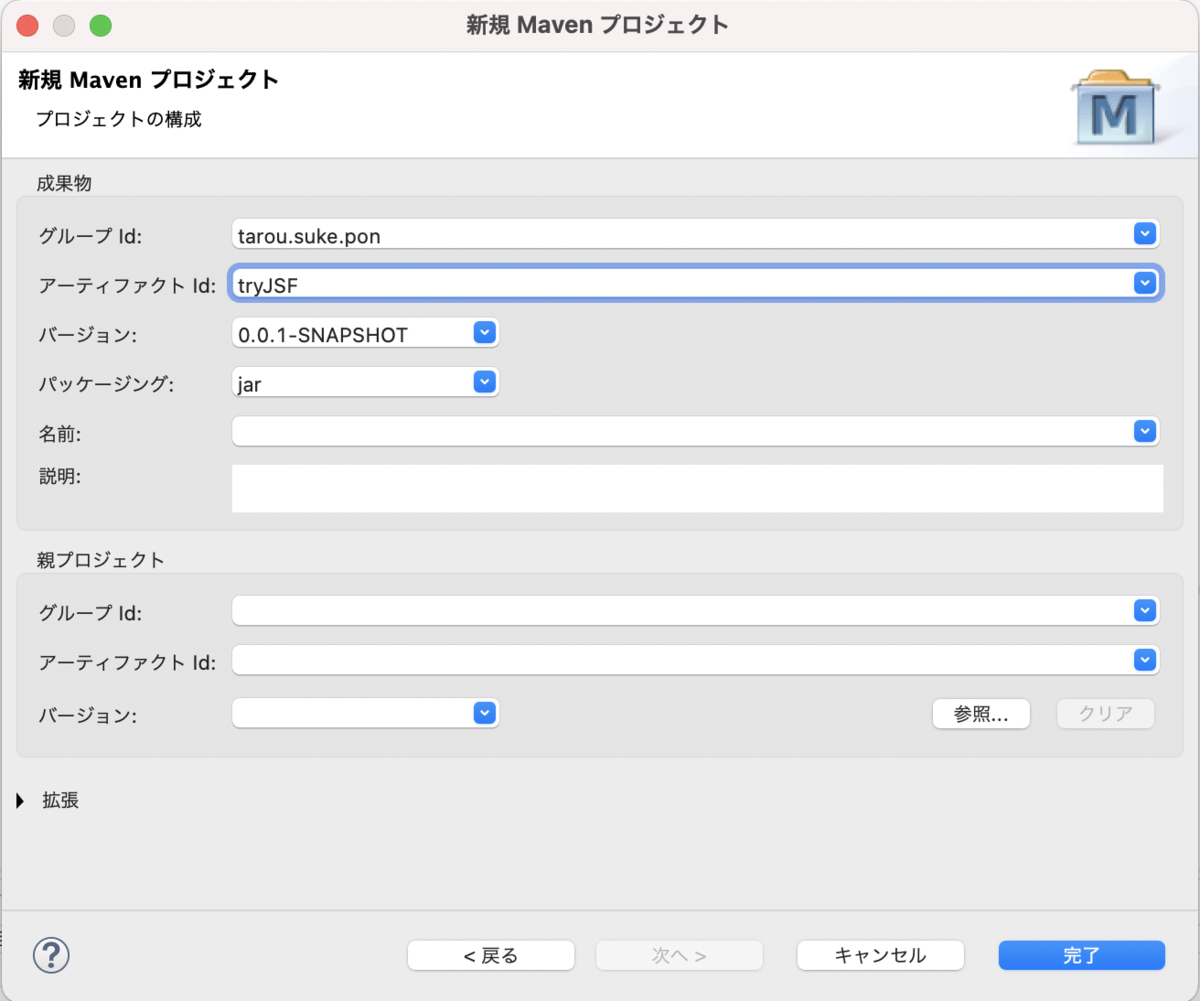
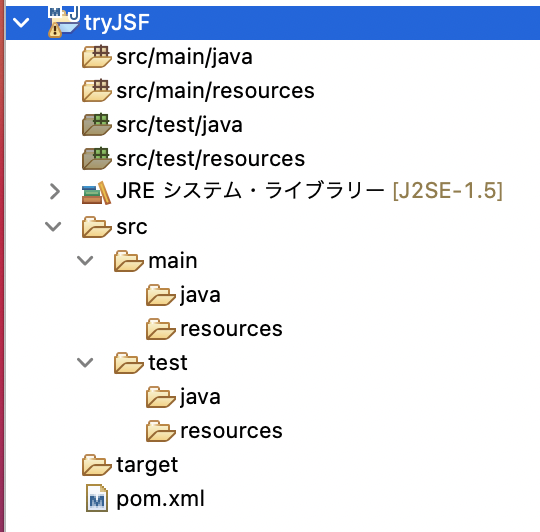
pom.xmlに文字コード「UTF-8」を設定する
文字コードを設定しないと各OSの文字コードでコードがビルドされます。 そうなるとビルドする環境によって内容が変わってしまいます。
なので、プラットフォームのエンコーディング (実際は UTF-8) を使用してフィルターされたリソースをコピーします。つまり、ビルドはプラットフォームに依存します!というメッセージがログや[エラー・ログ]ビューに出力されます。
<!-- ...省略... --> <properties> <!-- ソースの文字コードを定義 --> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> </project>
コンパイラを設定する
- [パッケージ・エクスプローラー]でプロジェクトを選択 > 「Command + I」でプロパティダイアログを表示する
- [プロジェクト・エクスプローラー]でもOK
- [Java コンパイラー] > [Javaビルド・パス上の実行環境'J2SE-1.5'から準拠を使用]チェックボックスをOFFにする
- [コンパイラー準拠レベル]で「11」を選択
- [デフォルトの準拠設定の使用]チェックボックスをOFFにする
- [適用]ボタン > メッセージダイアログが表示されるので[はい]でビルドを行う

pom.xmlにMavenコンパイル用のJDKを定義する
JDKを定義しないとMavenビルド後にJava compiler level does not match the version of the installed Java project facet.というエラーになることがあります。
<!-- ...省略... --> <properties> <!-- ソースの文字コードを定義 --> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <!-- Mavenコンパイル用のJavaを定義 --> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> </properties> </project>

JSFを設定する
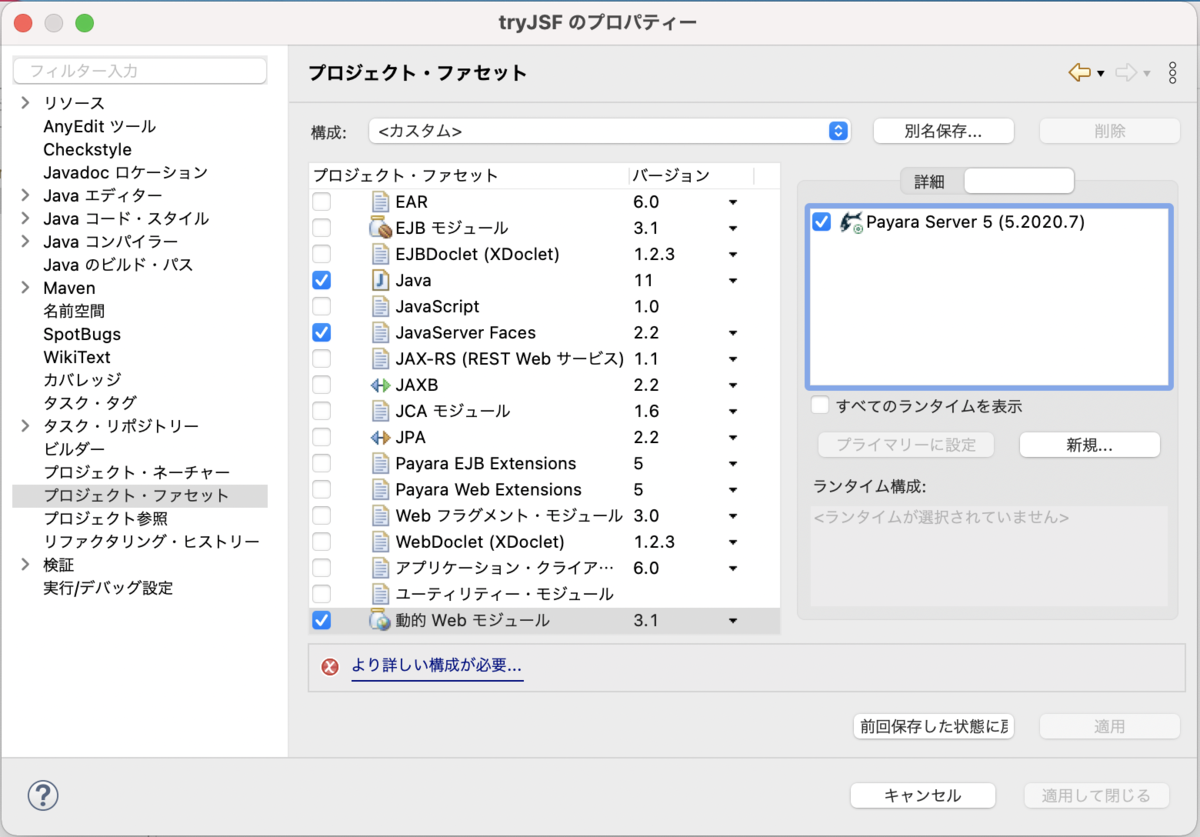
- [パッケージ・エクスプローラー]でプロジェクトを選択 > 「Command + I」でプロパティダイアログを表示する
- [プロジェクト・ファセット] > [ファセット・フォームへ変換...]リンクから一覧を表示する
- [Java]をONにして[Version]を「11」にする
- [JavaServer Faces]をONにして[Version]を「2.2」にする
- ここを「2.3」にすると後でコードをサーバで実行するときにUnable to find CDI BeanManager.となることがあるので注意してください
- [動的Webモジュール]をONにして[Version]を「3.1」にする
- [適用して閉じる]ボタンでプロパティダイアログを閉じる
- メッセージダイアログが表示されるので[はい]でビルドを行う
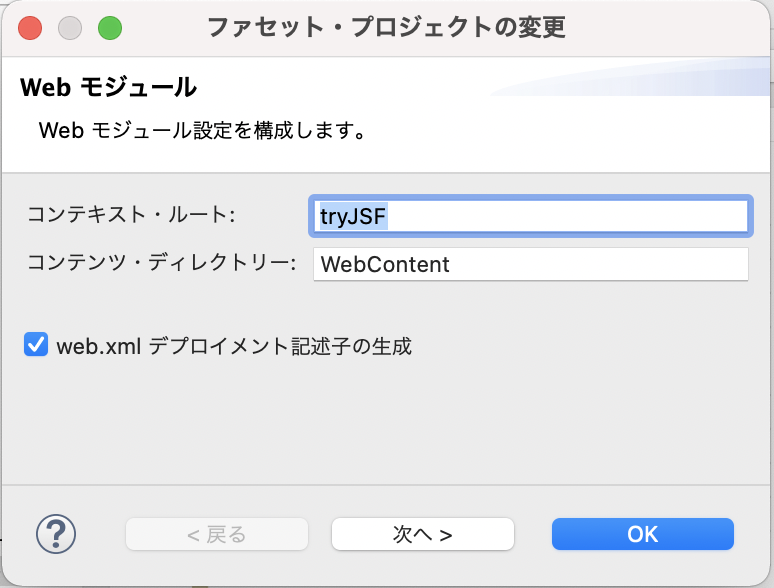
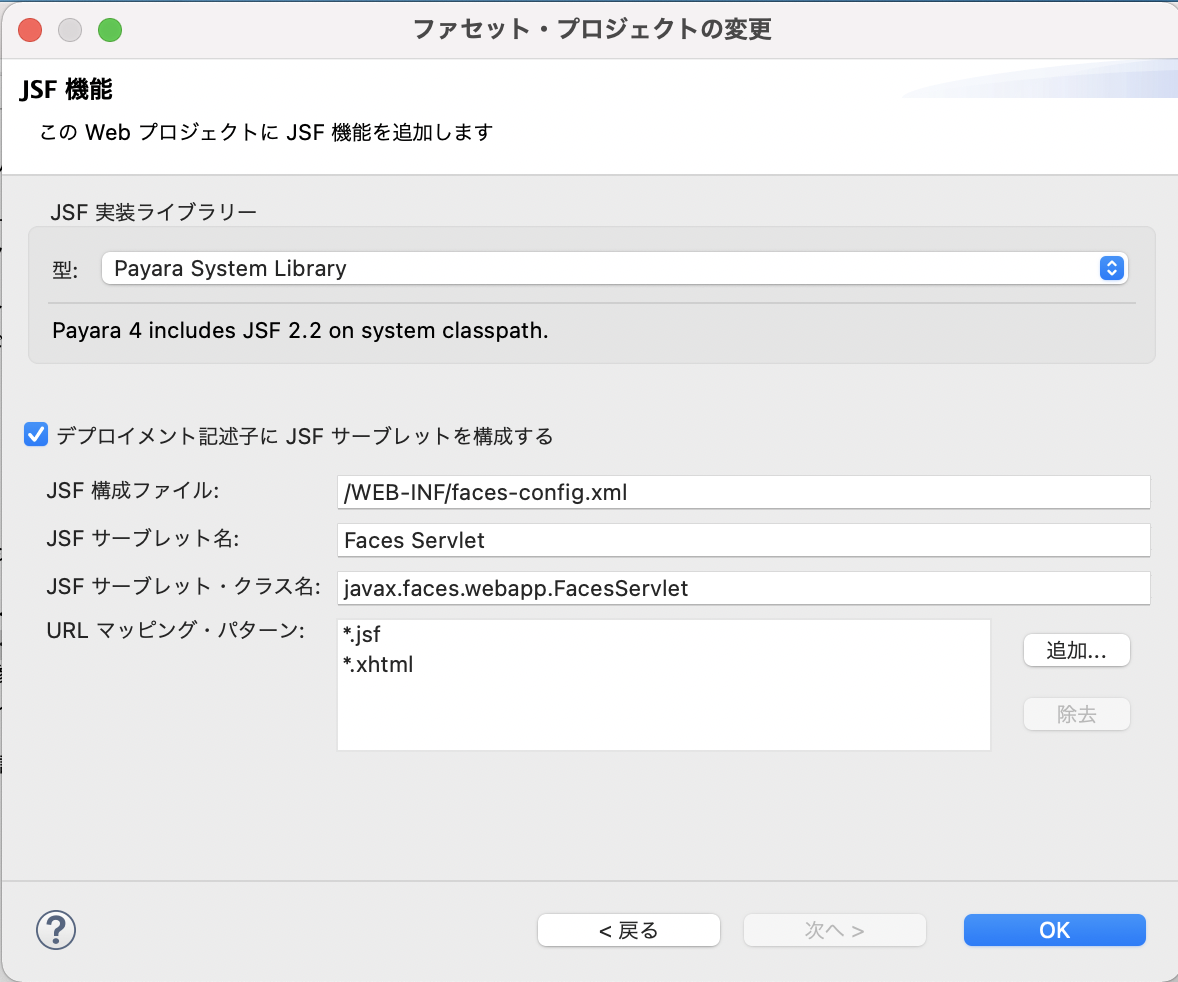
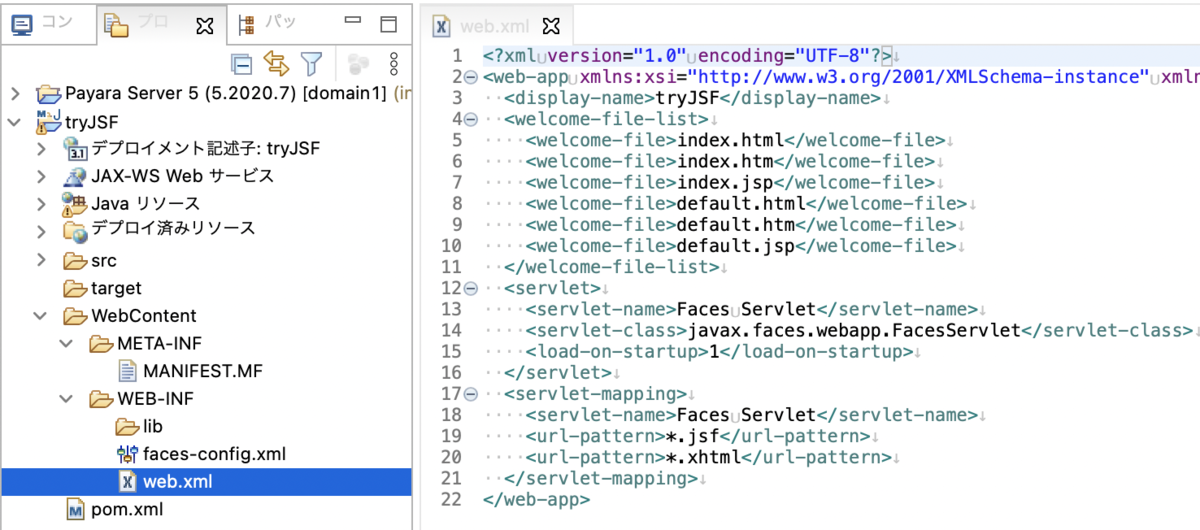
WebContentディレクトリは、コンテキストディレクトリともいいます。 コンテキストディレクトリは、任意のディレクトリに変更することもできます。
中身はこんな感じです。(まだないものもあります)
| ディレクトリ/ファイル名 | 内容 |
|---|---|
| WebContent/WEB-INF | コンパイル済みのプログラムや各種のライブラリファイル、設定ファイルなどが入ります。 このディレクトリ配下のリソースは、クライアント(WEBブラウザ)からアクセスすることはできません。 |
| WebContent/WEB-INF/lib | 各種ライブラリのJARファイル。 ここに配置したJARファイル中のクラスファイルはWebアプリケーションから参照することができます。 |
| WebContent/WEB-INF/classes | 作成したプログラムのclassファイルやメッセージプロパティファイルが格納されます。 |
| WebContent/WEB-INF/faces-config.xml | JSF の構成ファイルです。エラー・メッセージの国際化などに使用するリソース・バンドルの情報が記述されています。 |
| WebContent/WEB-INF/web.xml | アプリケーションの動作を指定する必須ファイルです。 FacesServletの動作環境や条件を定義します。 |
| WebContent/resources | 画像やCSSなどWebページに読み込ませるデータを配置します。 |
- 参考
出力されたweb.xmlはこんな感じです。
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd" id="WebApp_ID" version="3.1"> <display-name>tryJSF</display-name> <welcome-file-list> <welcome-file>index.html</welcome-file> <welcome-file>index.htm</welcome-file> <welcome-file>index.jsp</welcome-file> <welcome-file>default.html</welcome-file> <welcome-file>default.htm</welcome-file> <welcome-file>default.jsp</welcome-file> </welcome-file-list> <servlet> <servlet-name>Faces Servlet</servlet-name> <servlet-class>javax.faces.webapp.FacesServlet</servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>Faces Servlet</servlet-name> <url-pattern>*.jsf</url-pattern> <url-pattern>*.xhtml</url-pattern> </servlet-mapping> </web-app>
出力されたfaces-config.xmlはこんな感じです。
<?xml version="1.0" encoding="UTF-8"?> <faces-config xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-facesconfig_2_2.xsd" version="2.2"> </faces-config>
pom.xmlにJSFのライブラリを定義する
- Maven Repository: org.glassfish » javax.facesから任意のバージョンのMaven用定義をコピーしてpom.xmlに定義を貼り付ける
- 今回は作業時点で最新の「2.4」を使う
- Maven Repository: org.primefaces » primefacesから任意のバージョンのMaven用定義をコピーしてpom.xmlに定義を貼り付ける
- 今回は作業時点で最新の「8.0」を使う
- 参考 : Primefacesの紹介
- [Package Explorer]でプロジェクトを選択 > 「fn + option + F5」でダイアログを表示 > [OK]ボタンでMavenを更新する
<!-- ...省略... --> </properties> <dependencies> <!-- https://mvnrepository.com/artifact/org.glassfish/javax.faces --> <dependency> <groupId>org.glassfish</groupId> <artifactId>javax.faces</artifactId> <version>2.4.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.primefaces/primefaces --> <dependency> <groupId>org.primefaces</groupId> <artifactId>primefaces</artifactId> <version>8.0</version> </dependency> </dependencies> </project>
最初に表示されるページを作成する
JSFのページはWebContentディレクトリにXHTMLで作成します。
index.xhtmlを作成する
- [パッケージ・エクスプローラー]で[WebContent]を選択して「Command + N」で新規ダイアログを開く
- [Web] > [HTML ファイル] > [次へ]ボタン > [ファイル名:]に「index.xhtml」を入力し[次へ]ボタン
- [テンプレート:] > [新規Faceletテンプレート] > [完了]ボタンで新規ページを作成する
今はとりあえずなのでindex.xhtmlはテンプレートのままにします(改行は調整済み)。
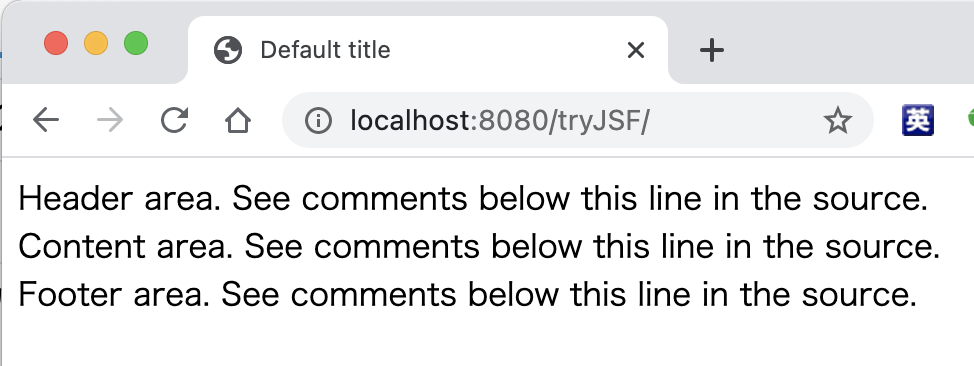
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:ui="http://xmlns.jcp.org/jsf/facelets"> <head> <title><ui:insert name="title">Default title</ui:insert></title> </head> <body> <ui:debug hotkey="x" rendered="#{initParam['javax.faces.FACELETS_DEVELOPMENT']}"/> <div id="header"> <ui:insert name="header"> Header area. See comments below this line in the source.<!-- include your header file or uncomment the include below and create header.xhtml in this directory --> <!-- <ui:include src="header.xhtml"/> --> </ui:insert> </div> <div id="content"> <ui:insert name="content"> Content area. See comments below this line in the source. <!-- include your content file or uncomment the include below and create content.xhtml in this directory --> <!-- <div> --> <!-- <ui:include src="content.xhtml"/> --> <!-- </div> --> </ui:insert> </div> <div id="footer"> <ui:insert name="footer"> Footer area. See comments below this line in the source. <!-- include your header file or uncomment the include below and create footer.xhtml in this directory --> <!--<ui:include src="footer.xhtml"/> --> </ui:insert> </div> </body> </html>
index.xhtmlをウェルカムページに設定する
ファイル名を指定しなかった場合に、既定で返されるドキュメントは設定ファイルで指定することが出来ます。 この既定のファイルのことを、ウェルカムページ (Welcome page) といいます。
JSP のウェルカムページ (デフォルトページ) の設定 - Java による Web アプリケーション開発 - Java の基本 - Java 入門
web.xmlにあるwelcome-file-listタグ配下を以下のように変更します。
<!-- ...省略... --> <welcome-file-list> <welcome-file>index.jsf</welcome-file> </welcome-file-list> <!-- ...省略... -->
Payaraを起動する
- [パッケージ・エクスプローラー]でプロジェクトを選択 > Option + Shift + X + R(サーバーで実行)
- ダイアログでPayaraを選択 > [OK]ボタンで実行
- ブラウザでhttp://localhost:8080/tryJsf/にアクセスしてページが表示されたら動作確認完了

Cloud9でLambdaを作ろうとして失敗した記録
- 残念ながら
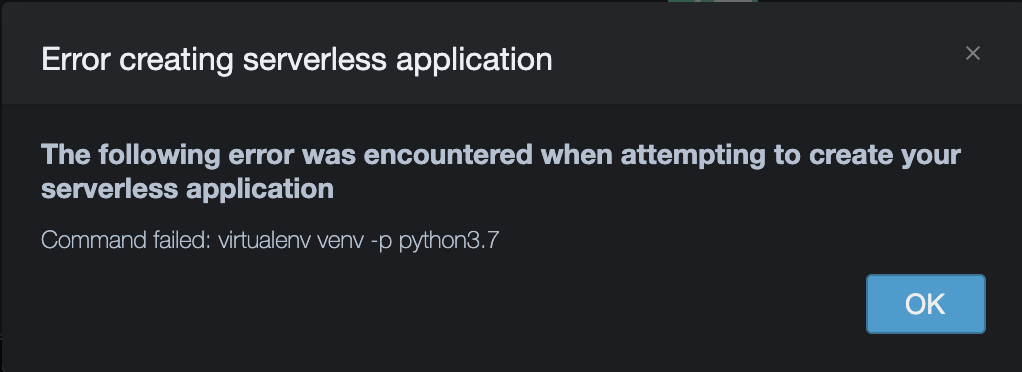
- Command failed: virtualenv venv -p python3.7
- Sorry, IKPdb only supports Python 3.6.x for now.
- Command failed: virtualenv venv -p python3.6
残念ながら
このページは残念な記録しかないので、こういうことが起こるんだぁぐらいにしか役立ちません。 解決方法もありません。誰かに教えてほしい状態です。
Command failed: virtualenv venv -p python3.7
$ python -V Python 3.6.12 $ python -m pip -V pip 20.3.1 from /home/ec2-user/.local/lib/python3.6/site-packages/pip (python 3.6) $ sudo python -V Python 3.6.12 $ sudo pip -V pip 9.0.3 from /usr/lib/python3.6/dist-packages (python 3.6)
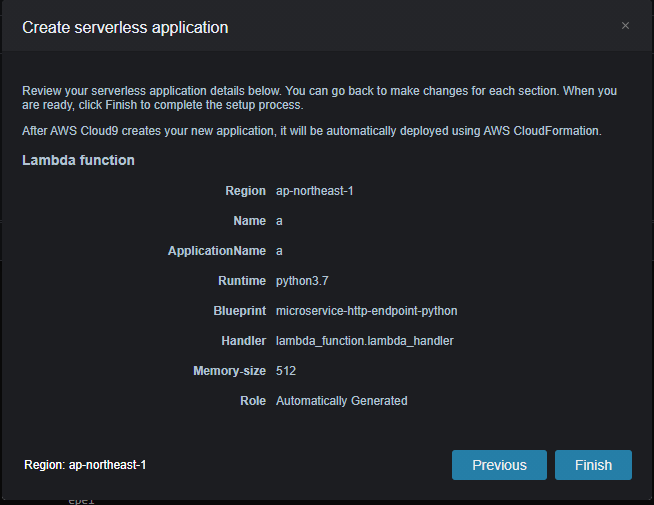
作成内容

エラー
原因 : 不明
# インストールディレクトリを見てみると $ which python /usr/bin/python # Pythonは「2.7」「3.6」はあるが「3.7」はない $ ls -la /usr/bin/ | grep python lrwxrwxrwx 1 root root 24 Dec 7 09:52 python -> /etc/alternatives/python lrwxrwxrwx 1 root root 17 Dec 4 16:25 python2 -> /usr/bin/python27 -rwxr-xr-x 1 root root 5104 Nov 2 22:27 python27 -rwxr-xr-x 1 root root 5104 Nov 2 22:27 python2.7 -rwxr-xr-x 1 root root 1846 Nov 2 22:27 python2.7-config lrwxrwxrwx 1 root root 25 Dec 4 16:26 python3 -> /etc/alternatives/python3 -rwxr-xr-x 3 root root 6872 Aug 31 18:58 python36 -rwxr-xr-x 3 root root 6872 Aug 31 18:58 python3.6 lrwxrwxrwx 1 root root 17 Dec 4 16:26 python3.6-config -> python3.6m-config -rwxr-xr-x 3 root root 6872 Aug 31 18:58 python3.6m -rwxr-xr-x 1 root root 173 Aug 31 18:57 python3.6m-config -rwxr-xr-x 1 root root 3373 Aug 31 18:41 python3.6m-x86_64-config lrwxrwxrwx 1 root root 32 Dec 4 16:26 python3-config -> /etc/alternatives/python3-config lrwxrwxrwx 1 root root 31 Dec 7 09:52 python-config -> /etc/alternatives/python-config
Python3.7をインストールしてもダメだった
参考 : pyenvによる仮想Python環境をAWS Cloud9上で構築する | Developers.IO
#### pyenvをインストールする # pyenvをGitHubからCloneする $ git clone https://github.com/pyenv/pyenv.git ~/.pyenv Cloning into '/home/ec2-user/.pyenv'... remote: Enumerating objects: 18376, done. remote: Total 18376 (delta 0), reused 0 (delta 0), pack-reused 18376 Receiving objects: 100% (18376/18376), 3.67 MiB | 2.61 MiB/s, done. Resolving deltas: 100% (12514/12514), done. # バージョンを確認する $ ~/.pyenv/bin/pyenv --version pyenv 1.2.21-1-g943015eb # .bashrcに定義を書いて $ vi ~/.bashrc $ cat ~/.bashrc | grep pyenv export PATH="$HOME/.pyenv/bin:$PATH" eval "$(pyenv init -)" # 反映させてPATHを通す $ source ~/.bashrc $ printenv PATH | sed -e 's/:/:\n/g' | grep pyenv /home/ec2-user/.pyenv/bin: $ pyenv --version pyenv 1.2.21-1-g943015eb #### Python3.7をインストールする # インストールできるPython3.7を確認する $ pyenv install -l | grep 3.7 2.3.7 3.3.7 3.7.0 3.7-dev 3.7.1 3.7.2 3.7.3 3.7.4 3.7.5 3.7.6 3.7.7 3.7.8 3.7.9 miniconda-3.7.0 miniconda3-3.7.0 stackless-3.3.7 stackless-3.7.5 # Python3.7.9をインストールする $ pyenv install 3.7.9 Downloading Python-3.7.9.tar.xz... -> https://www.python.org/ftp/python/3.7.9/Python-3.7.9.tar.xz Installing Python-3.7.9... python-build: use readline from homebrew WARNING: The Python bz2 extension was not compiled. Missing the bzip2 lib? WARNING: The Python readline extension was not compiled. Missing the GNU readline lib? Installed Python-3.7.9 to /home/ec2-user/.pyenv/versions/3.7.9 # WARNINGで出ている不足したものをインストールする $ sudo yum -y install bzip2 readline Loaded plugins: priorities, update-motd, upgrade-helper amzn-main | 2.1 kB 00:00:00 amzn-updates | 3.8 kB 00:00:00 1067 packages excluded due to repository priority protections Package bzip2-1.0.6-8.12.amzn1.x86_64 already installed and latest version Package readline-6.2-9.14.amzn1.x86_64 already installed and latest version Nothing to do # Python3.7に切り替える $ pyenv versions * system (set by /home/ec2-user/.pyenv/version) 3.7.9 $ pyenv global 3.7.9 $ python -V Python 3.7.9 ### ターミナルでエラーになったコマンドは実行できる・・・でもLambda関数が作れない・・・ $ virtualenv venv -p python3.7 Running virtualenv with interpreter /home/ec2-user/.pyenv/shims/python3.7 Using base prefix '/home/ec2-user/.pyenv/versions/3.7.9' New python executable in /home/ec2-user/environment/venv/bin/python3.7 Also creating executable in /home/ec2-user/environment/venv/bin/python Installing setuptools, pip, wheel... done.
Sorry, IKPdb only supports Python 3.6.x for now.
$ python -V Python 3.7.9 $ pip -V pip 20.3 from /home/ec2-user/.local/lib/python3.7/site-packages/pip (python 3.7) $ sudo python -V Python 2.7.18 $ sudo pip -V sudo: pip: command not found
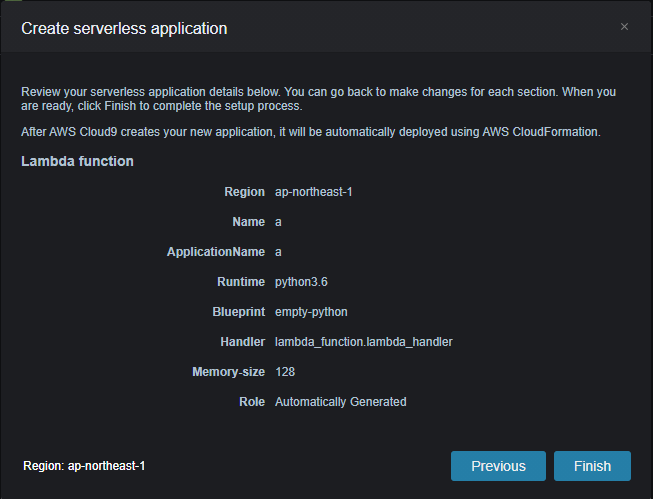
作成内容
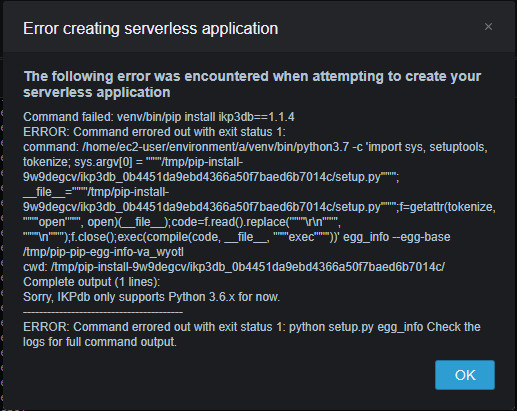
エラー
The following error was encountered when attempting to create your serverless application Command failed: venv/bin/pip install ikp3db==1.1.4 ERROR: Command errored out with exit status 1: command: /home/ec2-user/environment/a/venv/bin/python3.7 -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-9w9degcv/ikp3db_0b4451da9ebd4366a50f7baed6b7014c/setup.py'"'"'; __file__='"'"'/tmp/pip-install-9w9degcv/ikp3db_0b4451da9ebd4366a50f7baed6b7014c/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-pip-egg-info-va_wyotl cwd: /tmp/pip-install-9w9degcv/ikp3db_0b4451da9ebd4366a50f7baed6b7014c/ Complete output (1 lines): Sorry, IKPdb only supports Python 3.6.x for now. ---------------------------------------- ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
原因 : 不明
そもそもIKPdbとはなんぞや?
これには ikpdb という名前のモジュールが含まれており、AWS Cloud9 はこれを使用して Python アプリケーションをデバッグします。
との共同作業 AWS Lambda の関数 AWS Cloud9 Integrated Development Environment (IDE) - AWS Cloud9
Python2.7しかサポートしないよ的なことを言っている気がします。
Please note that IKPdb supports only CPython 2.7, CPython 3 support is the next step.
Welcome to IKPdb’s documentation! — IKPdb 1.0.0 documentation
いや、Python3以降は「IKPdb」ではなく「IKP3db」を使うのか?エラーもikp3db==1.1.4になっている。
IKP3db is a Python 3 debugger. For Python 2 see the IKPdb project on github and pypi.
「IKP3db」はバージョン「1.3」以降でPython3.7に対応している・・・のかな?
1.3
Add Python 3.7 support (debugger can now be invoked using the
breakpoint()function).
対応 : あきらめる
Lambdaの画面から関数を作成しようっと
Command failed: virtualenv venv -p python3.6
$ python -V Python 3.7.9 $ pip -V pip 20.3 from /home/ec2-user/.local/lib/python3.7/site-packages/pip (python 3.7) $ sudo python -V Python 3.7.9 $ sudo pip -V sudo: pip: command not found
作成内容
エラー
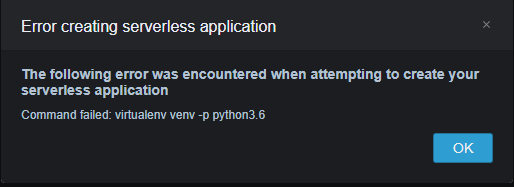
原因 : 不明
# インストールディレクトリを見てみると $ which python alias python='python3' /usr/bin/python3 # Pythonは「2.7」「3.7」はあるが「3.6」はない $ ls -la /usr/bin/ | grep python lrwxrwxrwx 1 root root 24 Dec 7 05:07 python -> /etc/alternatives/python lrwxrwxrwx 1 root root 9 Nov 6 19:45 python2 -> python2.7 -rwxr-xr-x 1 root root 7048 Aug 27 21:23 python2.7 -rwxr-xr-x 1 root root 1846 Aug 27 21:23 python2.7-config lrwxrwxrwx 1 root root 16 Nov 6 19:45 python2-config -> python2.7-config lrwxrwxrwx 1 root root 9 Nov 6 19:57 python3 -> python3.7 -rwxr-xr-x 2 root root 7048 Aug 27 22:02 python3.7 lrwxrwxrwx 1 root root 17 Nov 6 19:57 python3.7-config -> python3.7m-config -rwxr-xr-x 2 root root 7048 Aug 27 22:02 python3.7m -rwxr-xr-x 1 root root 173 Aug 27 22:02 python3.7m-config -rwxr-xr-x 1 root root 3210 Aug 27 21:16 python3.7m-x86_64-config lrwxrwxrwx 1 root root 16 Nov 6 19:57 python3-config -> python3.7-config lrwxrwxrwx 1 root root 14 Nov 6 19:45 python-config -> python2-config
対応 : Python3.6にこだわりがないのであきらめる
- Python2からPython3へ自力でバージョンアップしてYumが壊れたので修理する
- yumをアップデート
- Python3.6を探す >> インストールできそうなものがわからないので面倒くさくてあきらめた
$ sudo yum -y update Loaded plugins: extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 ... Complete! $ yum search python36-dev Loaded plugins: extras_suggestions, langpacks, priorities, update-motd 220 packages excluded due to repository priority protections ========================================================================================= N/S matched: python36-dev ========================================================================================== boost-python36-devel.x86_64 : Shared object symbolic links for Boost.Python 3 shiboken-python36-devel.x86_64 : Development files for shiboken Name and summary matches only, use "search all" for everything.
Backlogの課題にGitHubのコミットを連携する方法
このブログはBacklog Advent Calendar 2020 の7日目の記事です。 はじめてのAdvent Calendar参加でドキドキです。 adventar.org
- Backlogの課題にGitHubのコミットやプルリクをコメントとして入れたい!
- GitHubとBacklogを連携するLambda関数を作る
- できた!!
Backlogの課題にGitHubのコミットやプルリクをコメントとして入れたい!
やりたいことは、「Backlogの課題にGitHubのコミットやプルリクをコメントとして入れたい」です。 BacklogのGitを使っていればコミットコメントに課題キーがあればその課題のコメントにコミットが連携されます。 なのでGitHubを使っていても同じようにしたい!
[GithubとBacklogの連携] Backlogでissue管理して、Githubへのコミット内容をBacklogにも反映させる様に連携する方法 - Qiitaを見て簡単にできる!とおもったら・・・GitHubのServiceはWebhookに統合されて消えていました。
We have deprecated GitHub Services in favor of integrating with webhooks. Replacing GitHub Services | GitHub Developer Guide
似たようなことをやっている人は世の中にいるのでいろいろ調べながら手作りすることにしました。

GitHubとBacklogを連携するLambda関数を作る
1. BacklogでAPIキーを発行する
BacklogではAWSからやってくる処理を受け取るためのAPIキーを発行します。
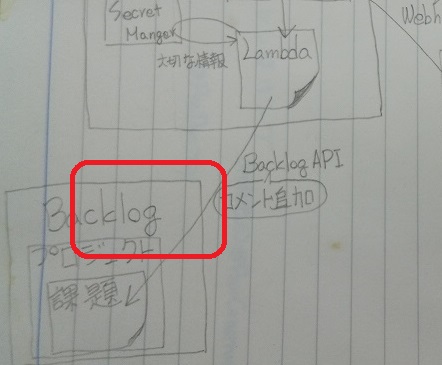
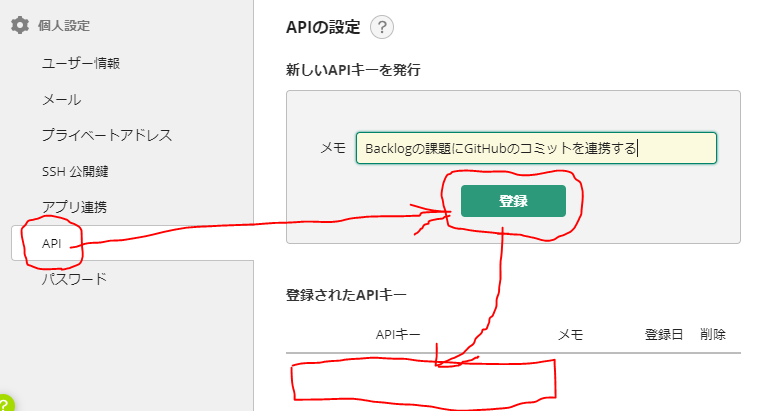
2. AWSでLambdaとAPI Gatewayを作成する
AWSではGitHubからやってくる情報をAPI Gatewayで受け取ってLambda関数を呼び出して処理できるようにします。
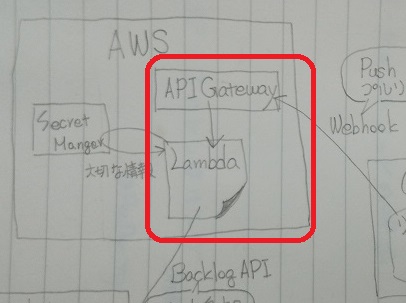
IAM ポリシーを作成する
Lambda関数で使用する権限を作成します。
- [AWS マネジメントコンソール]から[IAM]の画面を開く
- サイドメニューの[ポリシー] > [ポリシーの作成]ボタンで作成画面を表示
- [JSON]タブを開いて以下のJSONを設定 > [ポリシーの確認]ボタンで内容を確認
- {アカウントID}に設定する値はAWS アカウント ID の確認方法 | AWSで確認する
- [名前]に任意の値を設定 > [ポリシーの作成]ボタンで作成する
Lambdaのログを作成する権限とSecrets Managerからシークレットを取得する権限を設定している
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:対象のリージョン:{アカウントID}:*" }, { "Action": "secretsmanager:GetSecretValue", "Effect": "Allow", "Resource": "*" } ] }
IAM ロールを作成する
Lambda関数にアタッチするロールを作成してさっき作ったポリシーを設定します。
- [AWS マネジメントコンソール]から[IAM]の画面を開く
- サイドメニューの[ロール] > [ロールの作成]ボタンで作成画面を表示
- [AWSサービス] > [Lambda]を選択後に[次のステップ: アクセス権限]ボタンで次の画面を表示
- [ポリシーのフィルタ]で作成したポリシーを検索して選択後に[次のステップ: タグ]ボタンで次の画面を表示
- [タグの追加 (オプション)]は任意なので設定せずに[次のステップ: 確認]ボタンで次の画面を表示
- [ロール名]を入力して[ロールの作成]ボタンでロールを作成する
Lambda関数をとりあえず作る
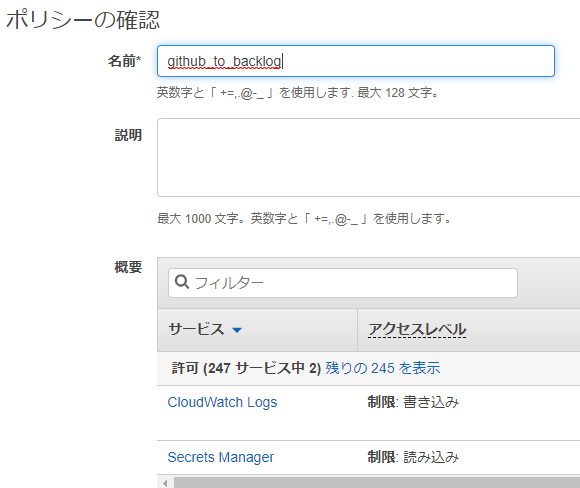
まずは、実装を後回しにして関数だけ作ります。
- [AWS マネジメントコンソール]から[Lambda]の画面を開く
- [関数の作成]ボタンで作成画面を表示する
- [一から作成]を選択して以下を設定して[関数の作成]ボタンで関数を作成する
- 関数名 : 任意の名前(今回は
github_to_backlog) - ランタイム : Python3.7
- 実行ロール : 既存のロールを使用する
- 既存のロール : 作成したロールを選択
- 関数名 : 任意の名前(今回は
コードには初期コードがあるのでそのまま。実装は後でやります。
import json def lambda_handler(event, context): # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }
API Gatewayを作成する
- 参考
今回は、[HTTP API]と[REST API]のどちらを使おうか迷ったけれど、「使ったことがない」「GitHubのWebhookを受け取りたいだけ」なんといっても「低コストらしいぞ」という理由で[HTTP API]にしました。
- [AWS マネジメントコンソール]から[API Gateway]の画面を開く
- [APIを作成]ボタンで[APIの作成]画面を表示する
- [HTTP API]の[構築]ボタンで次の画面へ
- [統合を追加] > [Lambda] > [Lambda 関数]で作成したLambda関数を選択
- [API 名]に任意の名前を設定して[次へ]ボタンで[ルートを設定]画面へ
- 以下を設定して[次へ]ボタンで[ステージを定義]画面へ
- メソッド : POST
- リソースパス :
/{Lambda関数名} - 統合ターゲット : {Lambda関数名}
- [ステージを追加]ボタンで以下を追加して[次へ]ボタンで[確認して作成]画面へ
- ステージ名 :
$default - 自動デプロイ : ON
- ステージ名 :
- [作成]ボタンで作成する
- 「{Lambda関数名}のステージ」一覧の[URLを呼び出す]列に「呼び出しURL」が表示される
- curlコマンドを使ってAPI Gatewayを呼び出してAPI GatewayがLambda関数を呼び出せることを確認する

| curlコマンドのオプション | 意味 |
|---|---|
| -X | HTTPメソッドを指定する |
| -H | HTTPヘッダを指定する |
# Lambda関数の初期コードに書いてある「Hello from Lambda!」が返却される $ curl -X POST -H 'Content-Type:application/json' {呼び出しURL}/{リソースパス} % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed } 100 20 100 20 0 0 50 0 --:--:-- --:--:-- --:--:-- 50"Hello from Lambda!" # 失敗例) 「リソースパス」をくっつけ忘れると「Not Found」になるので注意 $ curl -X POST -H 'Content-Type:application/json' {呼び出しURL} % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 23 100 23 0 0 287 0 --:--:-- --:--:-- --:--:-- 291{"message":"Not Found"}
3. GithubでWebhook設定する
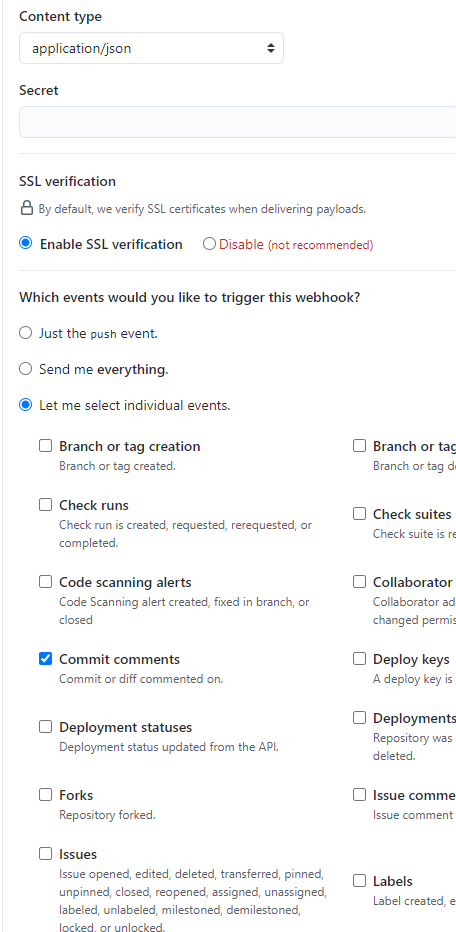
GitHubでのプッシュやプルリクの情報がAPI Gatewayに送られるようにWebhookを設定します。
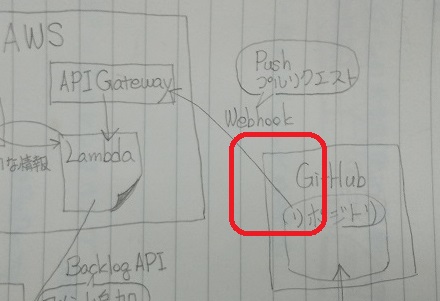
- ブラウザでGitHubのリポジトリを表示する
- [Settings] > [Webhooks] > [Add webhook]ボタン
- 以下を設定して[Add webhook]ボタン
- 表示されたWebhookの横につくマークが緑チェックになるのを確認する
- URLが間違っていたりすると赤バツが付くので、その場合は内容を確認する

4. AWSでSecrets Managerに情報を登録する
BacklogのAPIキーやGitHubのWebhookに設定したSecretは大切な情報なのでSecrets Managerに登録して、Lambda関数から取得して使うようにします。
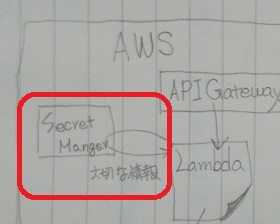
- [新しいシークレットを保存する]ボタンから作成画面を表示して以下を設定して[次]ボタン
- シークレットの種類: その他のシークレット
- シークレットのペア: 下記表参照
Backlogの情報は1つのシークレットに2つのキーを設定する
- 暗号化キー: DefaultEncryptionKey
- 以下を設定して[次]ボタン
- シークレットの名前: 下記表参照
- 説明とタグ: 任意
- [自動ローテーションを無効にする]を設定して[次]ボタン
- [保存]ボタンでシークレットを作成する
| シークレットの名前 | シークレットキー | シークレットの値 | 使うところ |
|---|---|---|---|
| github/to/backlog | GITHUB_SECRET | GitHubのWebhookに 設定したSecret |
GitHubから来た情報 をHMAC認証する時に使う |
| backlog/{GitHubのusername} | APIKEY | BacklogのAPIキー | Backlogに各ユーザで コメント追加するのに使う |
| 同上 | Backlogに登録され ているメールアドレス (以下手順で確認) 1.Backlogの[個人設定]の画面を開く 2. [ユーザー情報] > [メールアドレス] |
プルリクエストの通知を つけるためのid取得に使う |
5. Lambda関数を実装する
環境変数を設定する
Backlogの課題にコメント追加するにはBacklog APIを使用します。 そのためにBacklog APIの情報としてLambdaの環境変数に以下を設定して使用します。
| 環境変数のキー | 値 | 説明 |
|---|---|---|
| BACKLOG_ENDPOINT | BacklogAPIのエンドポイント | https://BacklogのURLと同じ値/api/v2/参考:認証と認可 | Backlog Developer API | Nulab |
| PROJECT_KEY | Backlogのプロジェクトキー | 参考 : プロジェクトの追加 – Backlog ヘルプセンター |
Secrets Managerからシークレットの値を取得する
登録したBacklogのAPIキーやGitHubのWebhookに設定したSecretを取得できるようにします。 基本的な実装はシークレットを登録した際にSecrets Managerの画面に表示されるサンプルコードを使用しました。
def get_secrets_manager_dict(secret_name: str) -> dict: """Secrets Managerからシークレットのセットを辞書型で取得する""" secrets_dict = {} if not secret_name: print('シークレットの名前未設定') else: session = boto3.session.Session() client = session.client( service_name='secretsmanager', region_name='対象のリージョン' ) try: get_secret_value_response = client.get_secret_value( SecretId=secret_name ) except ClientError as e: print('シークレット取得失敗:シークレットの名前={}'.format(secret_name)) print(e.response['Error']) else: if 'SecretString' in get_secret_value_response: secret = get_secret_value_response['SecretString'] else: secret = base64.b64decode(get_secret_value_response['SecretBinary']) secrets_dict = ast.literal_eval(secret) return secrets_dict
GitHubのWebhookから送られてくる内容を取得する処理を作る
GitHubのWebhookから送られてくる内容は以下サイトに説明があります。
まずは、GitHubから送られてきた情報が本当に設定したWebhookからなのを確認するためにHMAC認証します。 GitHubのWebhookに設定したSecretとGitHubから送られてきた情報で認証を行います。
参考 : GitHubのWebhookでプルリクエストをマージした際にツイートできるようしてみた - Qiita
def is_correct_signature(signature: str, body: dict) -> bool: """GitHubから送られてきた情報をHMAC認証する.""" if signature and body: # GitHubのWebhookに設定したSecretをSecrets Managerから取得する secret = get_secrets_manager_key_value('github/to/backlog', 'GITHUB_SECRET') if secret: secret_bytes = bytes(secret, 'utf-8') body_bytes = bytes(body, 'utf-8') # Secretから16進数ダイジェストを作成する signedBody = "sha1=" + hmac.new(secret_bytes, body_bytes, hashlib.sha1).hexdigest() return signature == signedBody else: return False
プッシュとプルリクではGitHubからくる情報が異なるというのとBacklogの課題に追加するコメントをちょっと変えるために処理を切り分けます。
| 操作 | action | pull_request | commits |
|---|---|---|---|
| Pull requests | o | o | x |
| Pushes | x | x | o |
def lambda_handler(event, context): # GitHubから送られてきた情報をHMAC認証する if is_correct_signature(event['headers']['x-hub-signature'], event['body']): body = json.loads(event['body']) # プッシュとプルリクを識別して処理を切り分ける if 'pull_request' in body and 'action' in body: # Pull requestsの場合 add_pull_request_comment(body['action'], body['pull_request'], body['sender']['login']) elif 'commits' in body: # Pushesの場合 add_push_comment(body['commits']) else: print('処理対象外のリクエストなので処理しない' + json.dumps(body)) else: print('認証できないGitHubのsignatureが送られてきた')
コメントから課題キーを検索する
コメント追加する課題を決めるためにコミットコメントやプルリクのコメントから課題キーを検索します。 複数の課題キーがあればそれぞれの課題にコメントが追加できるようにリストに課題キーを入れて返却します。
def get_issue_key(message: str) -> list: """コメントから課題キーを検索する.""" issue_key = [] # 「[プロジェクトキー] + [-] + [数字の繰り返し]を全て抜出 key_format = '{}-[\d]+'.format(os.environ.get('PROJECT_KEY')) match_list = re.findall(key_format, message) if match_list: # 抜き出した課題キーのリストから重複を削除する issue_key = list(set(match_list)) else: print('コメントにBacklogの課題キーが設定されていない') return issue_key
プルリクエストはレビューアーに通知をつけたいので通知リストを作る
通知リストは次の流れで作成します。
- プルリクエストに設定されたレビューアーのGitHubユーザー名でSecrets ManagerからBacklogのメールアドレスを取得する
- APIで取得したBacklogのユーザー一覧からメールアドレスでBacklogのユーザーIDを探す
- 通知リストへ追加する
def create_notified_list(requested_reviewers: list, backlog_users: list) -> list: """レビューアーにBacklogの通知をつけるため、にコメント登録の通知を受け取るユーザーIDリストを作成する""" notified_list = [] if requested_reviewers and backlog_users: for reviewer in requested_reviewers: # Secrets ManagerからBacklogのメールアドレスを取得する backlog_mail = get_secrets_manager_key_value('backlog/' + reviewer['login'], 'MAIL') if backlog_mail: for user in backlog_users: # 取得したメールアドレスと同じメールアドレスのユーザーをBacklogユーザー一覧から探す if backlog_mail == user['mailAddress']: # ユーザーのIDをリストへ追加する notified_list.append(user['id']) return notified_list
Backlogにコメントを追加する
def add_backlog_comment(api_key: str, issue_keys: list, comment: str, notified_list: list): """Backlogの課題にコメントを追加する.""" if not api_key or not issue_keys: print('BacklogのAPIキーまたは課題キー未設定') else: params = {'apiKey': api_key} payload = {'content': comment} # コメント登録の通知を受け取るユーザーIDがある場合は設定する if notified_list: payload['notifiedUserId[]'] = notified_list # コメントにある課題すべてにコメントを追加する for issue_key in issue_keys: header = {'Content-Type': 'application/x-www-form-urlencoded'} api_path = urllib.parse.urljoin(os.environ.get('BACKLOG_ENDPOINT'), '/'.join(['issues', issue_key, 'comments'])) result = requests.post(api_path, headers=header, params=params, data=payload)
できた!!
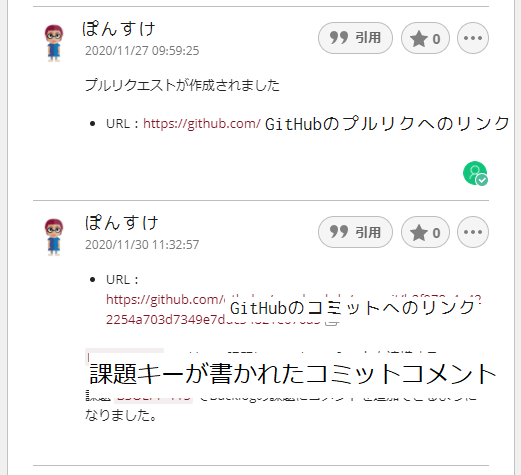
今回はシンプルにコメント追加をしました。 今後、BacklogのGitみたいに課題のステータス変更をしたり、レビューコメントも追加したりしたら楽しそうです!
コードの全体
ここ以降は、コード全部を張っているだけなので興味のある人だけ見てください。
import json, os import hmac, hashlib import requests, urllib import boto3 import base64 import ast, re from botocore.exceptions import ClientError def get_secrets_manager_dict(secret_name: str) -> dict: """Secrets Managerからシークレットのセットを辞書型で取得する""" secrets_dict = {} if not secret_name: print('シークレットの名前未設定') else: session = boto3.session.Session() client = session.client( service_name='secretsmanager', region_name='対象のリージョン' ) try: get_secret_value_response = client.get_secret_value( SecretId=secret_name ) except ClientError as e: print('シークレット取得失敗:シークレットの名前={}'.format(secret_name)) print(e.response['Error']) else: if 'SecretString' in get_secret_value_response: secret = get_secret_value_response['SecretString'] else: secret = base64.b64decode(get_secret_value_response['SecretBinary']) secrets_dict = ast.literal_eval(secret) return secrets_dict def get_secrets_manager_key_value(secret_name: str, secret_key: str) -> str: """AWS Secrets Managerからシークレットキーの値を取得する.""" value = '' secrets_dict = get_secrets_manager_dict(secret_name) if secrets_dict: if secret_key in secrets_dict: # secrets_dictが設定されていてsecret_keyがキーとして存在する場合 value = secrets_dict[secret_key] else: print('シークレットキーの値取得失敗:シークレットの名前={}、シークレットキー={}'.format(secret_name, secret_key)) return value def is_correct_signature(signature: str, body: dict) -> bool: """GitHubから送られてきた情報をHMAC認証する.""" if signature and body: # GitHubのWebhookに設定したSecretをSecrets Managerから取得する secret = get_secrets_manager_key_value('github/to/backlog', 'GITHUB_SECRET') if secret: secret_bytes = bytes(secret, 'utf-8') body_bytes = bytes(body, 'utf-8') # Secretから16進数ダイジェストを作成する signedBody = "sha1=" + hmac.new(secret_bytes, body_bytes, hashlib.sha1).hexdigest() return signature == signedBody else: return False def get_backlog_api_key(github_username: str) -> str: """GitHubのユーザ名から該当ユーザのBacklogのAPIキーを取得する.""" api_key = '' if github_username: api_key = get_secrets_manager_key_value('backlog/' + github_username, 'APIKEY') else: print('GitHubユーザー名未設定') return api_key def add_backlog_comment(api_key: str, issue_keys: list, comment: str, notified_list: list): """Backlogの課題にコメントを追加する.""" if not api_key or not issue_keys: print('BacklogのAPIキーまたは課題キー未設定') else: params = {'apiKey': api_key} payload = {'content': comment} # コメント登録の通知を受け取るユーザーIDがある場合は設定する if notified_list: payload['notifiedUserId[]'] = notified_list # コメントにある課題すべてにコメントを追加する for issue_key in issue_keys: header = {'Content-Type': 'application/x-www-form-urlencoded'} api_path = urllib.parse.urljoin(os.environ.get('BACKLOG_ENDPOINT'), '/'.join(['issues', issue_key, 'comments'])) result = requests.post(api_path, headers=header, params=params, data=payload) def get_backlog_users(api_key: str) -> list: """Backlogユーザー一覧の取得""" users = [] if not api_key: print('BacklogのAPIキー未設定') else: # ユーザーの取得対象はプロジェクト内に設定する api_path = urllib.parse.urljoin(os.environ.get('BACKLOG_ENDPOINT'), '/'.join(['projects', os.environ.get('PROJECT_KEY'), 'users'])) api_result = requests.get(api_path, params={'apiKey': api_key}).json() if type(api_result) == list and api_result: # Backlogのユーザー一覧を取得する users = api_result else: print('Backlogプロジェクトのユーザー一覧取得失敗:{}'.format(json.dumps(api_result))) return users def create_notified_list(requested_reviewers: list, backlog_users: list) -> list: """レビューアーにBacklogの通知をつけるため、にコメント登録の通知を受け取るユーザーIDリストを作成する""" notified_list = [] if requested_reviewers and backlog_users: for reviewer in requested_reviewers: # Secrets ManagerからBacklogのメールアドレスを取得する backlog_mail = get_secrets_manager_key_value('backlog/' + reviewer['login'], 'MAIL') if backlog_mail: for user in backlog_users: # 取得したメールアドレスと同じメールアドレスのユーザーをBacklogユーザー一覧から探す if backlog_mail == user['mailAddress']: # ユーザーのIDをリストへ追加する notified_list.append(user['id']) return notified_list def get_issue_key(message: str) -> list: """コメントから課題キーを検索する.""" issue_key = [] # 「[プロジェクトキー] + [-] + [数字の繰り返し]を全て抜出 key_format = '{}-[\d]+'.format(os.environ.get('PROJECT_KEY')) match_list = re.findall(key_format, message) if match_list: # 抜き出した課題キーのリストから重複を削除する issue_key = list(set(match_list)) else: print('コメントにBacklogの課題キーが設定されていない') return issue_key def add_push_comment(commits: list): print('プッシュの情報をBacklogの課題へコメント追加する') print(json.dumps(commits)) # プッシュに含まれるコミットを1つずつ処理する for commit in commits: issue_key = [] if 'message' in commit: issue_keys = get_issue_key(commit['message']) if issue_keys: backlog_api_key = get_backlog_api_key(commit['committer']['username']) if backlog_api_key: comment_format = '- URL:{}\n{}' comment = comment_format.format(commit['url'], commit['message']) add_backlog_comment(backlog_api_key, issue_keys, comment, []) def add_pull_request_comment(action: str, pull_request: dict, username: str): print('プルリクエストの情報をBacklogの課題へコメント追加する\nアクション:{}\nマージ:{}'.format(action, str(pull_request['merged']))) print(json.dumps(pull_request)) # プルリクのタイトルとコメントから課題キーを取得する issue_keys = get_issue_key(pull_request['title'] + pull_request['body']) if issue_keys: # BacklogのAPIキーを取得する backlog_api_key = get_backlog_api_key(username) if backlog_api_key: notified_list = [] if 'requested_reviewers' in pull_request and pull_request['requested_reviewers']: # Backlogのユーザー一覧を取得する backlog_users = get_backlog_users(backlog_api_key) if backlog_users: # レビューアーが設定されている場合は追加するコメント用の通知リストを作成する notified_list = create_notified_list(pull_request['requested_reviewers'], backlog_users) # プルリクのアクションによってコメントを作成する comment = '' if action == 'opened' or action == 'reopened': comment = 'プルリクエストが作成されました' elif action == 'closed': if pull_request['merged']: comment = 'プルリクエストがマージされました' else: comment = 'プルリクエストが却下されました' else: comment = 'プルリクエストが変更されました' comment += '\n\n- URL:{}'.format(pull_request['html_url']) add_backlog_comment(backlog_api_key, issue_keys, comment, notified_list) def lambda_handler(event, context): # GitHubから送られてきた情報をHMAC認証する if is_correct_signature(event['headers']['x-hub-signature'], event['body']): body = json.loads(event['body']) # プッシュとプルリクを識別して処理を切り分ける if 'pull_request' in body and 'action' in body: # Pull requestsの場合 add_pull_request_comment(body['action'], body['pull_request'], body['sender']['login']) elif 'commits' in body: # Pushesの場合 add_push_comment(body['commits']) else: print('処理対象外のリクエストなので処理しない' + json.dumps(body)) else: print('認証できないGitHubのsignatureが送られてきた')
Kintoneの開発環境を作成する
Kintoneの開発環境って何?
kintone API を使った開発用に1年間Kintoneが使えるようになります。
kintone 開発者ライセンスは、kintoneのアプリケーション開発を目的として、ご利用いただける開発環境です。本運用のご利用はできません。
開発環境を作成する
cybozu developer networkにアカウントを作成する
- cybozu developer networkを表示する
- 右上の[サインイン]ボタンでポップアップを表示する
- [cybozu developer network を初めてご利用の方: アカウント登録]リンクから登録用のポップアップを表示する
- 入力項目を入力して[アカウント登録]で仮登録する
- 入力したメールで件名が「cybozu developer networkへようこそ」のメールに書かれたURLからサイトを表示する
- パスワードを設定してログインする
kintone開発者ライセンスを取得する
- ログイン後の画面で[kintone開発者ライセンスを取得]ボタンでページを表示する
- 内容を確認した後で[開発者ライセンスを申し込む]ボタンで申込ページを表示する
- 申込みフォームを入力して[申込み]ボタンで申し込む
- 申し込み完了メッセージは画面上部に表示される

画面が上部に移動しのでエラーがあったのかと思ったけど大丈夫だった。
- メールがやってくるのをしばし待つ > メールが来たら書いてある[アクセスURL][ログイン名][パスワード]でKintoneにログインする

開発環境のKintoneが使えるようになった!
使ってみる
パスワード認証を使ってスペース情報取得してみる
- [Kintone] > [スペース]の右にある[+]ボタン > [スペースを作成]からポップアップを表示
- [はじめから作る] > [基本設定]タブの内容を入力([参加メンバー]タブは誰もいないので設定しない)
- [保存]ボタンでスペースを作成する
- 「ログイン名:パスワード」をbase64エンコードする
- 以下を実行してスペース情報を取得する
crul+-H X-Cybozu-Authorization:{base64エンコードしたもの}+https://{サブドメイン名}.cybozu.com/k/v1/space.json?id={スペースのID}
| コード | 意味 | 参考 |
|---|---|---|
-H X-Cybozu-Authorization:{base64エンコードしたもの} |
ユーザ認証用のリクエストヘッダ | kintone REST APIの共通仕様 – cybozu developer network |
https://{サブドメイン名}.cybozu.com/k/v1/space.json?id={スペースのID} |
スペース情報の取得用のURIとリクエストパラメータ | スペース情報の取得 – cybozu developer network |
# 最後の改行を出力しない(-n)ようにしてbase64エンコードする % echo -n '{ログイン名}:{パスワード}' | base64 xxxxx== # スペース情報を取得する % curl -H 'X-Cybozu-Authorization:xxxxx==' https://hoge.cybozu.com/k/v1/space.json?id=1 {"id":"1","name":"はじめてのスペース","defaultThread":"1","isPrivate":true,"creator":{"code":"...
APIトークン認証を使ってアプリ情報取得してみる
- スペースのページを表示する
- [アプリ]の右にある[+]ボタンで作成画面を表示する
- [初めから作成] > 手頃にパーツを配置する > [アプリを公開] > [OK]ボタンでアプリを作成する
手頃にこんな感じで作りました。
- APIトークンを生成するを参考にトークンを作成する
- 以下を実行してスペース情報を取得する
crul+-H X-Cybozu-API-Token:{APIトークン}+https://{サブドメイン名}.cybozu.com/k/v1/app/form/fields.json?app={アプリのID}\&lang=ja
| コード | 意味 | 参考 |
|---|---|---|
-H X-Cybozu-API-Token:{APIトークン} |
APIトークン認証用のリクエストヘッダ | kintone REST APIの共通仕様 – cybozu developer network |
https://{サブドメイン名}.cybozu.com/k/v1/app/form/fields.json?app={アプリのID}\&lang=ja |
フィールドの一覧を取得用のURIとリクエストパラメータ | フォームの設定の取得 – cybozu developer network |
% curl -H X-Cybozu-API-Token:XxxxXx https://hoge.cybozu.com/k/v1/app/form/fields.json?app={アプリのID}\&lang=ja
{"revision":"4","properties":{"カテゴリー":{"type":"CATEGORY","code":"カテゴリー","label":"カテゴリー","enabled":false},"テーブル":{"type":"SUBTABLE","code":"テーブル","noLabel":false,"label":"テーブル","fields":{"数値":{"type":"NUMBER","code":"数値","label":"数値","noLabel":false,...

万二郎岳と万三郎岳 in 天城山
先週は那須で登山をしました。
万二郎岳

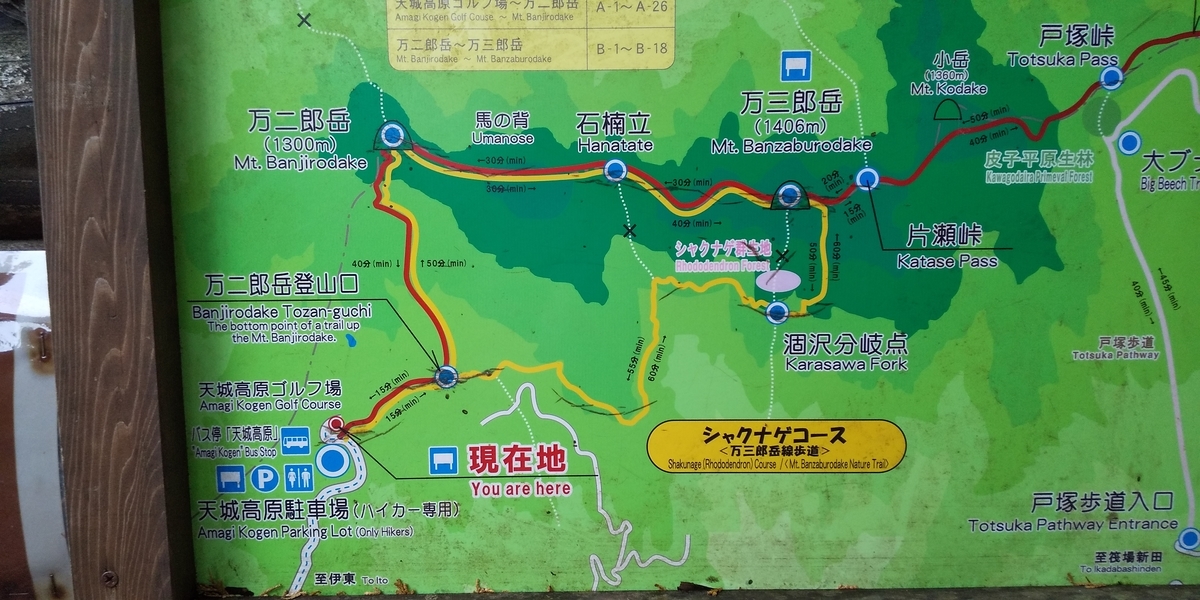



万三郎岳
 万三郎岳が近づいてくるとコースの名前にもなっているアマギシャクナゲが登山道に増えてきます。
標識によると5~6月に見頃を迎えるそうなので次はぜひ咲いているときに来てみたいです。
万三郎岳が近づいてくるとコースの名前にもなっているアマギシャクナゲが登山道に増えてきます。
標識によると5~6月に見頃を迎えるそうなので次はぜひ咲いているときに来てみたいです。


裸の木がいっぱい!です。木についているフダをみるとヒメシャラとリョウブなのですが・・・見分けがつきません。 すっかり落葉したこの時期に「リョウブ」「ヒメシャラ」「サルスベリ」を木の幹と樹形だけで見分けられるようになりたいです。 botanica-media.jp


 基本的にシャクナゲコースは初心者向けらしいのですが山頂から戻る道はちょっと足場が不安定なところが多いです。
基本的にシャクナゲコースは初心者向けらしいのですが山頂から戻る道はちょっと足場が不安定なところが多いです。

登山の後はやっぱり温泉!
温泉だ!と検索して出てきたのは伊豆市冷川にある「源泉湯治の宿 ごぜんの湯」。早速向かってみると・・・休業のふだがかかっていた・・・ onsen.surugabank.co.jp というわけで道の駅伊東マリンタウンで温泉に入って帰りました。 ito-marinetown.co.jp
天城山(シャクナゲコース)| 山ガールのための山歩きガイド コースガイド 女性のための登山情報サイト 山ガールネットで紹介されている日帰り温泉「東海館」というところを次は狙うべし!