レスポンシブ対応で知ったメディアクエリの基本
- メディアクエリは、表示するディバイスなどによって適用するCSSを切り替える機能です。
- メディアクエリの指定方法
- メディアは、メディアタイプかメディア特性を論理演算子で組み合わせて指定します。
- スマートフォン用にはどんな指定がいいか集めてみました。
- メディアクエリを使うにはHTMLのheadタグにviewportを指定します。
メディアクエリは、表示するディバイスなどによって適用するCSSを切り替える機能です。
表示された画面環境に応じて適用するスタイルを切り替える機能。
メディアクエリ(Media Queries)とは - IT用語辞典 e-Words
メディアクエリは画面の解像度 (例えばスマートフォンの画面とコンピュータの画面) といった条件に対応してコンテンツの描画が行えるようにするCSS3のモジュールである。
メディアクエリ - Wikipedia
メディアクエリは、一般的な端末の種類 (プリンタと画面など)や特定の特性 (画面の解像度やブラウザーのビューポートの幅など) に応じてサイトやアプリを変更したいときに便利です。
メディアクエリの使用 - CSS: カスケーディングスタイルシート | MDN
メディアクエリの指定方法
HTMLファイルにタグの属性として指定する
<!--linkタグのmedia属性で指定する--> <link rel="stylesheet" href="hoge.css" media="screen, projection, tv" /> <!--styleタグのmedia属性で指定する--> <style type="text/css" media="aural, speech"> ...スタイルの指定... </style> <!--pictureタグの内部でのみsourceタグで使える--> <picture> <source media='(min-width: 650px)' srcset='hoge.png'> </picture>
CSSファイルに指定する
/* @mediaで指定する */ @media only screen and (max-device-width: 480px){ ...スタイルの指定... } /* @importでCSSファイルと一緒に指定する */ @import url(example.css) screen and (color);
メディアは、メディアタイプかメディア特性を論理演算子で組み合わせて指定します。
メディアタイプの種類
メディアタイプは端末の全般的なカテゴリを説明します。 not 又は only の論理演算子を使用する場合を除いて、メディアタイプは任意であり、 all タイプが暗黙に含まれています。
メディアクエリの使用 - CSS: カスケーディングスタイルシート | MDN
| メディアタイプ | 対象 |
|---|---|
| all | すべての端末 |
| screen | printに一致しないすべての端末 |
| ページ付きの素材や、印刷プレビューモードで画面に表示された文書 |
- 以下のメディアタイプは、メディアクエリ4から非推奨
- tty(文字幅が固定の機器) / tv(テレビ) / projection(プロジェクタ) / handheld(携帯機器) / braille(点字ディスプレイ) / embossed(点字プリンタ) / aural(音声出力) / speech(音声出力)
- 参考 : Media Queries Level 4
メディア特性の種類
メディア特性は、特定のユーザーエージェントや、出力端末や、環境などの特性を記述します。メディア特性式は、存在又は値を検査するもので、完全に任意です。それぞれのメディア特性式は、括弧で囲む必要があります。
メディアクエリの使用 - CSS: カスケーディングスタイルシート | MDN
| 名前 | 概要 | 値 |
|---|---|---|
| color | 出力端末の色コンポーネントあたりの色数、または端末がカラーでなければゼロ | |
| height | ビューポートの高さ | |
| orientation | ビューポート (またはページ付きメディアではページボックス) の向き | portrait(縦長) / landscape(横長) |
| scripting | スクリプト(例えばJavaScript)が利用できるかを検出する | |
| width | ビューポートの幅 |
※. 使いそうなのだけ抜き出したましたが、@media - CSS: カスケーディングスタイルシート | MDNにはたくさん乗っているので参照してください。


論理演算子の種類
論理演算子 not, and, only を使用して、複雑なメディアクエリを構成することができます。複数のメディアクエリをカンマで区切って、単一の規則にまとめることもできます。
メディアクエリの使用 - CSS: カスケーディングスタイルシート | MDN
| 論理演算子 | 意味 | 例 |
|---|---|---|
| and | 複数のメディア特性・メディアタイプをまとめる。 真になるためには結合されたそれぞれの特性が真を返す必要がある。 |
@media (min-width: 30em) and (orientation: landscape) { ... } |
| not | メディアクエリを否定する。 クエリが偽を返せば真を返す。 使用する場合は、メディアタイプも指定しなければならない。 |
@media not all and (monochrome) { ... } 上記の解釈は以下 正解: @media not (all and (monochrome)) { ... } 誤り: @media (not all) and (monochrome) { ... } |
| only | クエリ全体が一致した場合にスタイルを適用。 使用する場合は、メディアタイプも指定しなければならない。 メディア特性がついたメディアクエリに対応していない古いブラウザーで、そのスタイルが適用されるのを防ぐ。 最近のブラウザーでは効果がない。 |
@media only screen and (color) { ... } |
| ,(カンマ) | 複数のメディアクエリを一つのメディアクエリに結合する。 リストは論理 or 演算子のように動作する。 |
@media (min-height: 680px), screen and (orientation: portrait) { ... } |
スマートフォン用にはどんな指定がいいか集めてみました。
いろいろやると訳わかんなくなるので、シンプルにスマートフォンの縦用だけをいろんなサイトから集めてみました。
スマートフォンの横からはPCと共通のCSSで頑張って見てもらう感じ。
@media screen and (max-width: 480px) { }
スマートフォンのシェアが増え、かつほとんどが縦画面で見ていると想定するなら、これが落ち着きどころと言える
【2020年4月修正追記】レスポンシブ CSSメディアクエリ(@media)ブレイクポイントまとめ | モバイル・スマホWeb・WordPressのSEO塾.com
スマホ向けは「タブレットじゃなくなったら」の否定法で
@media only screen and (max-width: 767px)
が主流。
レスポンシブウェブデザインのメディアクエリのオススメの書き方 [無料ホームページ作成クラウドサービス まめわざ]
@media screen and (max-width:768px) {
/*スマホ用のcssを記述*/
}
CSSでメディアクエリ(@media)を使ってレスポンシブ(スマホ対応)にする方法 | HikoPro Blog
560px未満をスマホと設定
ポートレートとランドスケイプは用途を分けて考える。←これ重要
※iPhoneSEのランドスケープ(568px)、iPad Pro 11の5:5 Split Viewもタブレット扱いにするために560pxに設定。<省略>
560px未満 @media screen and (max-width: 559px) {...}
960px未満 @media screen and (max-width: 959px) {...}
※「以下」ではなく「未満」にするために、メディアクエリの数字を一つ減らすのがポイントですね。
【新定番】レスポンシブデザインのブレイクポイントの正解はこれだった[2019最新版] - webのあれこれ
スマホ縦 @media screen and (max-width: 480px) 【2020年3月】レスポンシブ CSSブレイクポイント・メディアクエリ(@media) | SEO塾/株式会社アルゴリズム
メディアクエリを使うにはHTMLのheadタグにviewportを指定します。
<head> <meta name="viewport" content="width=device-width, initial-scale=1"> </head>
CentOSでJSFのプロジェクトを作る
- 環境
参考資料
久しぶりにJSF用のプロジェクトを1から作ろうと思い立った。
記憶も記録も美しいまでに消えていた。
以下のサイト様を見ながら記憶と記録を作り直す。
ittoybox.com
EclipseにPayaraを設定する
Payaraを配置する
# 1. 任意のディレクトリへ移動 $ cd /opt # 2. Payaraのzipファイルをダウンロード $ wget https://repo1.maven.org/maven2/fish/payara/distributions/payara/5.194/payara-5.194.zip # 3. zipファイルを解凍する $ unzip payara-5.194.zip # 4. 使い終わったzipファイルを削除する $ rm payara-5.194.zip # 5. .bash_profileで環境変数にPayaraを設定する $ vi ~/.bash_profile $ cat ~/.bash_profile $ export PATH=$PATH:/opt/payara5/bin $ source ~/.bash_profile # 6. 実行できるように権限設定する RUN chmod -R 777 /opt/payara5/glassfish
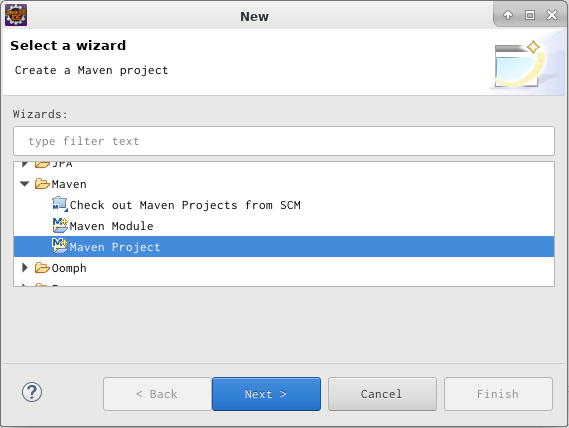
Mavenプロジェクトを作成する
- [Package Explorer]にカーソルを入れて「Ctrl + N」で新規作成ダイアログを表示する。
- [Maven] > [Maven Project] > [Next]ボタン
- [Create a simple project(skip archetype selection)]チェックボックスをONにする > [Next]
- 以下を設定して[Finish]ボタンでプロジェクトを作成する
- GroupId : プロジェクトのルートパッケージ名
- ArtifactId : プロジェクト名

- この時点でエラーがあっても見なかったことにする
コンパイラを設定する
- [Package Explorer]でプロジェクトを選択 > 「Alt + Enter」でプロパティダイアログを表示する
- [Java Compiler] > [Use compliance from execution environment 'JavaSE-1.5 on the 'Java Build Path']チェックボックスをOFFにする
- [Compiler compliance level]で「11」を選択 > [Apply]ボタンで適用する
- 以下のメッセージダイアログが表示されるので[Yes]でビルドを行う

ざっくり訳 : コンパイラ変えたから今ビルドしとく?

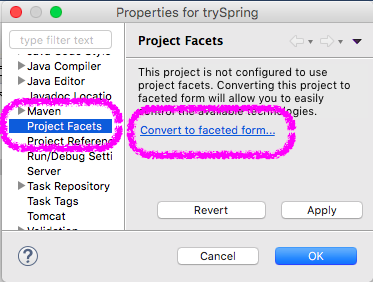
JSFを設定する
- [Project Facet] > [Convert to Faceted...]リンクを押下して一覧を表示する
- [Java]をONにして[Version]を「11」にする
- [JavaServer Faces]をONにして[Version]を「2.3」にする
- [Dynamic Web Module]をONにして[Version]を「4.0」にする
- [Runtimes]タブ > 表示されたPayaraをONにする
- 下の方に出てくる[Further configuration required...]リンクを押下して[Modify Faceted Project]画面を表示する
- [Content directory : ]を設定する(今回はデフォルトのまま)
- [Generate web.xml....... : ]チェックボックスをONにする > [Next]ボタン
- 特に変更はしないで[OK]ボタンでダイアログを閉じる
- [Aply and Close]ボタンでプロパティダイアログを閉じる
- プロジェクトにエラーが有った場合は、エラーが消える(はず)


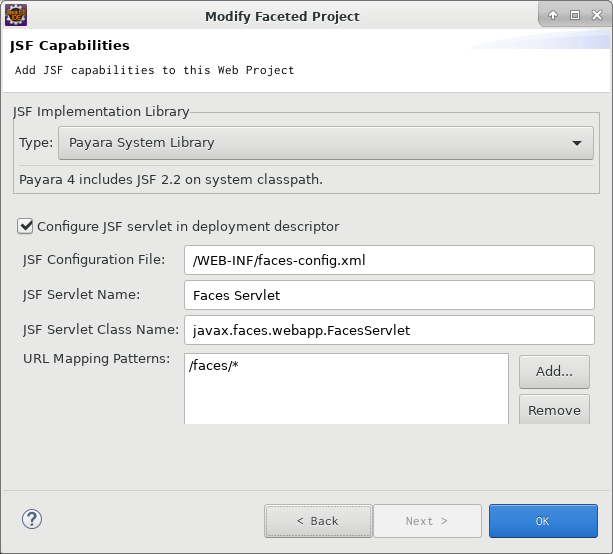
pom.xmlにJSFのライブラリを定義する
- Maven Repository: org.glassfish » javax.facesから任意のバージョンのMaven用定義をコピーする
- [JavaServer Faces]を「2.3」にしたので今回は「2.3.9」を使う
- Eclipseでpom.xmlを開いて定義を貼り付ける
- Maven Repository: org.primefaces » primefacesから任意のバージョンのMaven用定義をコピーする
- 今回は作業時点で最新の「8.0」を使う
- JSFでラジオボタンなどを使うのに便利
- 参考 : Primefacesの紹介
- [Package Explorer]でプロジェクトを選択 > 「Alt + F5」でダイアログを表示 > [OK]ボタンでMavenを更新する
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> ...省略... <dependencies> <dependency> <groupId>org.glassfish</groupId> <artifactId>javax.faces</artifactId> <version>2.3.9</version> </dependency> <!-- https://mvnrepository.com/artifact/org.primefaces/primefaces --> <dependency> <groupId>org.primefaces</groupId> <artifactId>primefaces</artifactId> <version>8.0</version> </dependency> </dependencies> </project>
ServletのバージョンをDynamic Web Moduleに合わせる
- src/main/webapp/WEB-INF/web.xmlを開く
- web-appの記載をDynamic Web Moduleに合わせる
- 参考 : web.xmlのバージョン別DTD・XSDの宣言方法 | KATSUMI KOKUZAWA'S BLOG
- バージョン4.0の場合は以下の記載になる
- [Package Explorer]でプロジェクトを選択 > 「Alt + F5」でダイアログを表示 > [OK]ボタンでMavenを更新する
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <!-- 省略 -->
動かしてみる
ページを作成する
- [webapp]を選択して「Ctrl + N」で新規ダイアログを開く
- [Web] > [HTML File] > [Next]ボタンで進む > [File name:]に「index.xhtml」を入力し[Next]ボタン
- [Templates:] > [New Facelet Composition Page](新規Facelet構成ページ) > [Finish]ボタンで新規ページを作成する
- 以下のコードをindex.xhtmlに記載する

<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:ui="http://xmlns.jcp.org/jsf/facelets" xmlns:h="http://xmlns.jcp.org/jsf/html" xmlns:f="http://xmlns.jcp.org/jsf/core" xmlns:p="http://primefaces.org/ui"> <head> <title>MavenでJSFのプロジェクトをEclipseで作ってみた。</title> </head> <body> JSFのプロジェクト </body> </html>
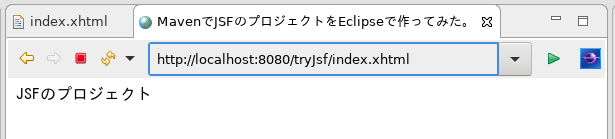
Payaraを起動する
- [Package Explorer]でプロジェクトを選択して右クリック
- [Run As] > [Run On Server] > ダイアログでPayaraを選択して起動する
- http://localhost:8080/tryJsf/index.xhtmlにアクセスしてページが表示されたら動作確認完了

WordPressでGoogleのCustom Search APIを使ってみる
- 1. プロジェクトを作成してCustom Search APIを設定する
- 2. 検索エンジンを作成する
- 3. WordPressで検索処理を作る
- 4. ブログの投稿にショートコードを埋め込む
- 5. 結果を表示する
- もうちょっと使ってみた
1. プロジェクトを作成してCustom Search APIを設定する
- (ない場合)Google アカウントの作成でアカウントを作成する
- (ない場合)Google Cloud Platformでプロジェクトを作成する
- 画面上部でプロジェクトを選択する
- APIとサービスを有効化リンクで[APIライブラリ]画面を表示する
- 「Custom Search API」を検索して選択、[有効化]ボタンで有効にする
- プロジェクトを作成していないと有効化できないらしい
- 参考 : PHP、GoogleのCustom Search APIを使ってみる(1):事前準備1、APIキーを取得する|マコトのおもちゃ箱 ~ぼへぼへ自営業者の技術メモ~
- [ナビゲーションメニュー] > [APIとサービス] > [認証情報] > 画面上部の[認証情報作成] > [APIキー]でAPIキーを作成する
- APIキーをメモっておく
- ポップアップの[キーを制限]リンクから[API キーの制限と名前変更]画面を表示して制限情報を設定して[保存]ボタンで保存する


2. 検索エンジンを作成する
- Programmable Search Engine by Googleを表示して[Get started]ボタンで[Programmable Search]画面を表示する
- [新しい検索エンジン]で画面を表示して検索エンジンを作成する
- [検索するサイト] : 「*.sample.com」(後で削除する)
- [言語] : 「日本語」
- [検索エンジンの名前] : 好きな名前
- 参考 : Laravel上でGoogle Custom Search APIを使ってみた - Qiita
- [コントロールパネル]ボタンで画面を表示する
- 必要に合わせて検索エンジンを設定する
- 参考 : PHP、GoogleのCustom Search APIを使ってみる(2):事前準備2、検索エンジンの設定をする|マコトのおもちゃ箱 ~ぼへぼへ自営業者の技術メモ~
- Web全体を検索できるようにする設定
- [検索するサイト] > 登録したサイトを選択 > [削除]ボタンで削除する
- [ウェブ全体を検索]を「オン」にする
- [基本]タブ > [検索エンジン ID]から検索エンジンIDをメモっておく


3. WordPressで検索処理を作る
PHPで検索処理を作る
functions.php : ショートコードを設定する
<?php // ...省略... /** Custom Search APIでGoogle検索した結果を引用符形式で表示する. */ function google_block_quote() { ob_start(); get_template_part('output-google-block-quote'); return ob_get_clean(); } add_shortcode('search_google', 'google_block_quote');
output-google-block-quote.php : 検索結果を表示する
<?php require_once('search-google.php'); $items = search_google(); ?> <h1>今日のGoogle検索</h1> <?php if (count($items) === 0) : ?> <p>検索したけど結果なし</p> <?php else : ?> <?php foreach ($items as $key => $item) : ?> <blockquote class="wp-block-quote"> <a href="<?php echo $item['link']; ?>"><?php echo $item['title']; ?></a> <p><?php echo $item['snippet']; ?></p> </blockquote> <br> <?php endforeach; ?> <?php endif; ?>
output-google-block-quote.php : 検索をする
- 参考
<?php /** * GoogleのCustom Search APIでの検索結果を取得する. * @return array 検索結果. */ function search_google(): array { $reqest_url = create_reqest_url(); $retJson = file_get_contents($reqest_url, true); $ret = json_decode($retJson, true); return $ret['items']; } /** * Custom Search APIへのリクエスト内容含めたURLを作成する. * @return string リクエスト内容含めたURL. */ function create_reqest_url(): string { $paramAry = array( // 検索する文字列 'q' => 'ponsuke tarou', // メモっておいたAPIキー 'key' => {APIキー}, // メモっておいた検索エンジンID 'cx' => {検索エンジンID}, // 検索結果をjson形式で取得する 'alt' => 'json', // 取得開始順位(1~10位までの検索結果を取得する) 'start' => 1 ); $param = http_build_query($paramAry); return 'https://www.googleapis.com/customsearch/v1?'. $param; } ?>
4. ブログの投稿にショートコードを埋め込む

5. 結果を表示する

もうちょっと使ってみた
初めて聞いた、AWS Elastic Beanstalkって何?
- 初めて聞いた、AWS Elastic Beanstalk
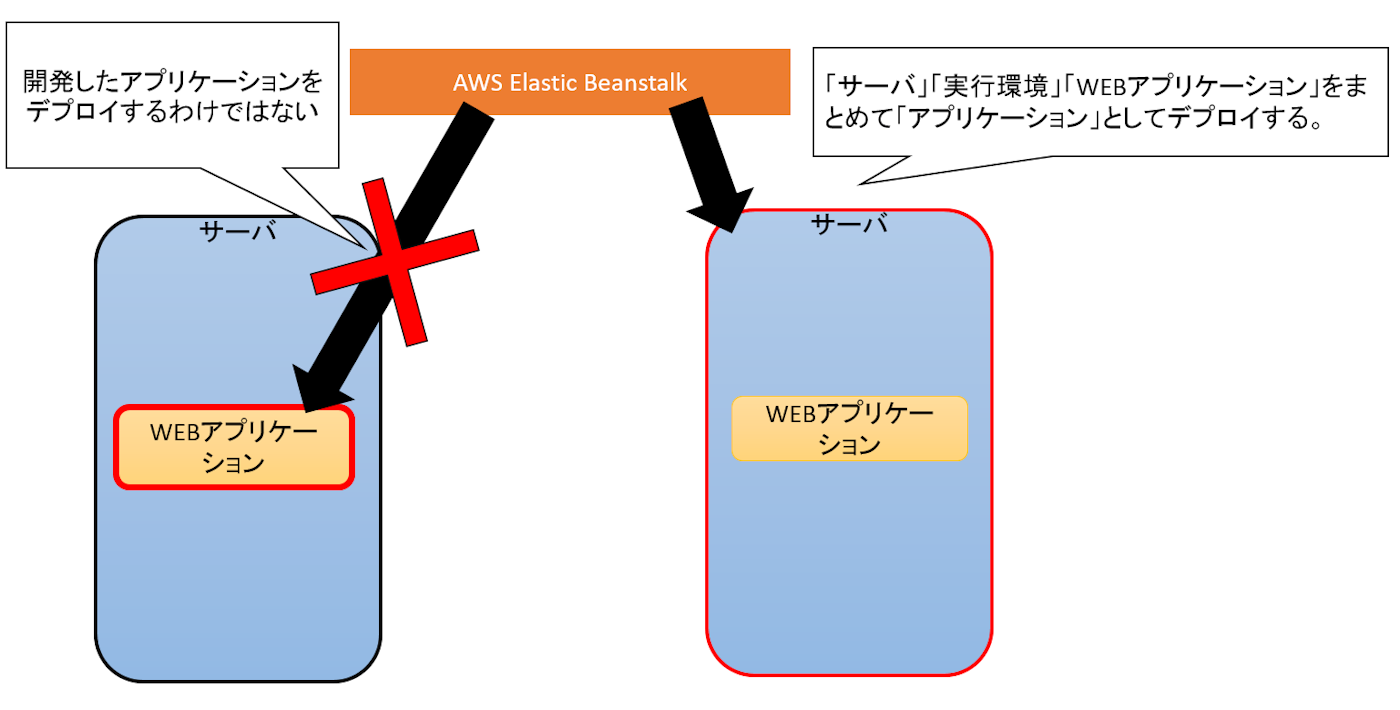
- AWS Elastic Beanstalkは、ウェブアプリケーションやサービスをサーバーでデプロイおよびスケーリングするためのサービスです。
- よくわかんないな・・・
AWS Elastic Beanstalkは、ウェブアプリケーションやサービスをサーバーでデプロイおよびスケーリングするためのサービスです。
AWS Elastic Beanstalk は、Java、.NET、PHP、Node.js、Python、Ruby、Go および Docker を使用して開発されたウェブアプリケーションやサービスを、Apache、Nginx、Passenger、IIS など使い慣れたサーバーでデプロイおよびスケーリングするための、使いやすいサービスです。
AWS Elastic Beanstalk(ウェブアプリの実行と管理)| AWS
Elastic Beanstalk自体は、無料で使えます。
Elastic Beanstalk には追加料金はかかりません。アプリケーションを格納および実行するために必要な AWS のリソースに対してのみお支払いいただきます。
AWS Elastic Beanstalk(ウェブアプリの実行と管理)| AWS
Dockerプラットフォームは、3種類あります。
単一コンテナの Docker
1つのインスタンスにコンテナは1つしか作れない・・・のか?
単一コンテナプラットフォームは、インスタンスごとに 1 つのコンテナを実行する必要がある場合にのみ使用します。
Docker コンテナからの Elastic Beanstalk アプリケーションのデプロイ - AWS Elastic Beanstalk
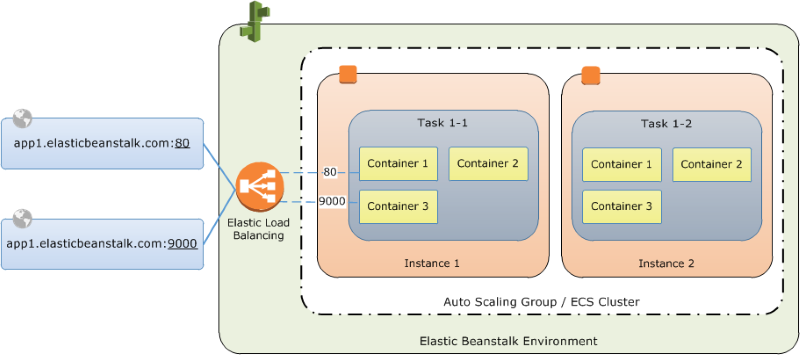
マルチコンテナの Docker
Docker を最大限に活用するため、Elastic Beanstalk では、Amazon EC2 インスタンスが複数の Docker コンテナを並行して実行できる環境を作成することができます。
複数コンテナの Docker 環境 - AWS Elastic Beanstalk
事前設定済み Docker コンテナ
自分が使いたいのと同じ設定の環境がある場合に使うものらしい。
docs.aws.amazon.com
よくわかんないな・・・
AWSのEC2を自動停止するLambdaを作る記録
実行権限を作成します。
- 「IAMのポリシーを作成する」を参考にポリシーを作成します。
- [JSON]タブで設定するポリシーは以下になります。
- 「IAMのロールを作成する」を参考にロールを作成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"ec2:DescribeInstances",
"ec2:StopInstances",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
自動停止の対象と停止時間を設定できるようにするためにEC2インスタンスにAutoStopタグを追加します。
「自動停止の対象と停止時間を設定できるようにするためにRDSにAutoStopタグを追加します。」を参考にEC2インスタンスにAutoStopタグを追加します。
Lambda関数を作成します。
- AWSのコンソールにある[Lambda] > [関数の作成]ボタンで画面を開きます。
- 必要な項目を入力後に[関数の作成]ボタンで関数を作成します。
- オプション : [一から作成]
- 関数名 : 任意の関数名
- ランタイム : Python3.8
- 実行ロール : 既存のロールを使用する
- 作成したロールを選択します。
- 「Lambda関数を実行するトリガーを作成します。」を参考にトリガーを作成します。
関数を実装します。
- [関数コード] > [lambda_function.py]に以下のコードを張り付けて[保存]ボタンで保存します。
- 定数の[REGION_NAME]には停止対象のEC2インスタンスがあるリージョンを指定してください。
- 「関数を動かしてみます。」を参考にエラーが無くなるまで関数を動かして修正を繰り返します。
# -*- coding: utf-8 -*- from __future__ import print_function import sys import json import boto3 from datetime import datetime, timedelta, timezone, date import re # 停止対象のインスタンスがあるリージョンを設定する REGION_NAME = 'ap-northeast-1' DATETIME_FORMAT = '%Y-%m-%dT%H:%M:%SZ' print("Loading function") def get_instance_list(ec2): """ 起動中かつ[AutoStop]タグが設定されたインスタンスを取得する処理. Parameters ---------- ec2 """ instances = ec2.describe_instances( Filters=[ {"Name": "instance-state-name", "Values": ["running"]}, {'Name': 'tag-key', 'Values': ['AutoStop']} ] )['Reservations'] new_instances = [] for instance in instances: new_instances.append(instance['Instances'][0]) return new_instances def get_auto_stop_tag(instance): """ AutoStopタグに設定された時間文字列を取得する. """ result = '' val = '' tag_list = instance['Tags'] tag = next(iter(filter(lambda tag: tag['Key'] == 'AutoStop' and (tag['Value'] is not None and len(tag['Value']) != 0), tag_list)), None) if tag: val = tag["Value"] if not val: print('タグに時間が指定されていません。') elif not re.fullmatch('\d{1,2}:\d{1,2}', val): print('タグに設定されている文字列が時間(hh:mm)ではありません。' + val) else: print('タグに設定された時間は、' + val + 'です。') result = val return result def get_utc_time(jst_time_string): """ HH:MM形式のJST時間文字列をUTC時間にして取得する. """ # 時間文字列を{時間, 分}の配列にする jst_time = jst_time_string.split(':'); today = datetime.now() # 設定時刻が8:59以前である場合、UTC変換時に前日にならないよう日付を1日進めておく if int(jst_time[0]) < 9: today = today + timedelta(day=1) jst_time = datetime(today.year, today.month, today.day, int(jst_time[0]), int(jst_time[1])) utc_time = jst_time + timedelta(hours=-9) return utc_time def is_stop(event_time, auto_stop_time): """ インスタンスを停止するかを判定する """ # 設定時間の5分前 from_time = auto_stop_time + timedelta(minutes=-5) # 設定時間の5分後 to_time = auto_stop_time + timedelta(minutes=5) print("イベント時間(" + event_time.strftime(DATETIME_FORMAT) + ")が、" + \ from_time.strftime(DATETIME_FORMAT) + "から" + to_time.strftime(DATETIME_FORMAT) + "の間であればインスタンスを停止します。") # AutoStopタグに指定された時刻の前後5分以内であればインスタンス停止 is_stop = from_time <= event_time and event_time <= to_time return is_stop def lambda_handler(event, context): print("Received event: " + json.dumps(event, indent=2)) ec2 = boto3.client('ec2', REGION_NAME) instances = get_instance_list(ec2) if len(instances) == 0: print('処理対象のインスタンスはありません。') return 0 # インスタンス終了処理 for instance in instances: print(instance['InstanceId'] + 'は起動中です。') # [AutoStop]タグに設定された時間文字列を取得する tag_time_string = get_auto_stop_tag(instance) if tag_time_string: # [AutoStop]タグに設定された時間文字列をUTC時間にする auto_stop_time = get_utc_time(tag_time_string) print('タグに設定された時間(UTC)は、' + auto_stop_time.strftime(DATETIME_FORMAT)) # 引数のイベント時間を取得 event_time = datetime.strptime(event["time"], DATETIME_FORMAT) if is_stop(event_time, auto_stop_time): ec2.stop_instances(InstanceIds=[instance['InstanceId']]) print(instance['InstanceId'] + "を停止しました。") return 0
使用した関数のドキュメント
- describe_instances : 辞書形式でインスタンスを取得する
- stop_instances : 指定したインスタンスを停止する
失敗したこと
An error occurred (UnauthorizedOperation) when calling the DescribeInstances operation: You are not authorized to perform this operation.
- 原因 : describe_instances関数を実行する権限がなかった。
- 対応 : ポリシーの[Action]に「ec2:DescribeInstances」を追加しました。
Response:
{
"errorMessage": "An error occurred (UnauthorizedOperation) when calling the DescribeInstances operation: You are not authorized to perform this operation.",
"errorType": "ClientError",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 34, in lambda_handler\n instance_list = get_instance_list()\n",
" File \"/var/task/lambda_function.py\", line 19, in get_instance_list\n instances = ec2.describe_instances(\n",
ネットワークにいる機器を監視するSNMPプロトコル
- 前回の勉強内容
- 勉強のきっかけになった問題
- SNMPは、TCP/IPネットワークに接続されている機器の情報を収集して監視や制御を行うためのプロトコルです。
- SNMPは、SNMPマネージャとSNMPエージェントの間で使用されます。
- SNMPv1、SNMPv2、SNMPv3の3つのバージョンがあります。
- SNMPマネージャとSNMPエージェントは、MIBをやり取りします。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
ネットワーク管理プロトコルであるSNMPv3で使われるPDUのうち、事象の発生をエージェントが自発的にマネージャに知らせるために使用するものはどれか。ここで、エージェントとはエージェント相当のエンティティ、マネージャとはマネージャ相当のエンティティを指す。
- SetRequest-PDU
- Response-PDU
- SNMPv2-Trap-PDU
- GetRequest-PDU
SNMPは、TCP/IPネットワークに接続されている機器の情報を収集して監視や制御を行うためのプロトコルです。
- 英語 : Simple Network Management Protocol
SNMPは、SNMPマネージャとSNMPエージェントの間で使用されます。
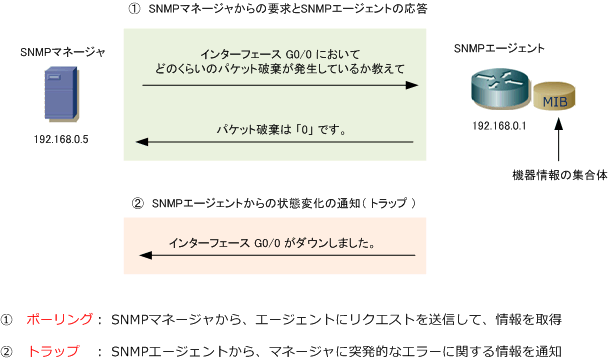
【図解】SNMPの仕組み~利用ポート,監視方法(マネージャのMIBポーリング/trap受信),tcp/udp,writeの実装例〜│SEの道標


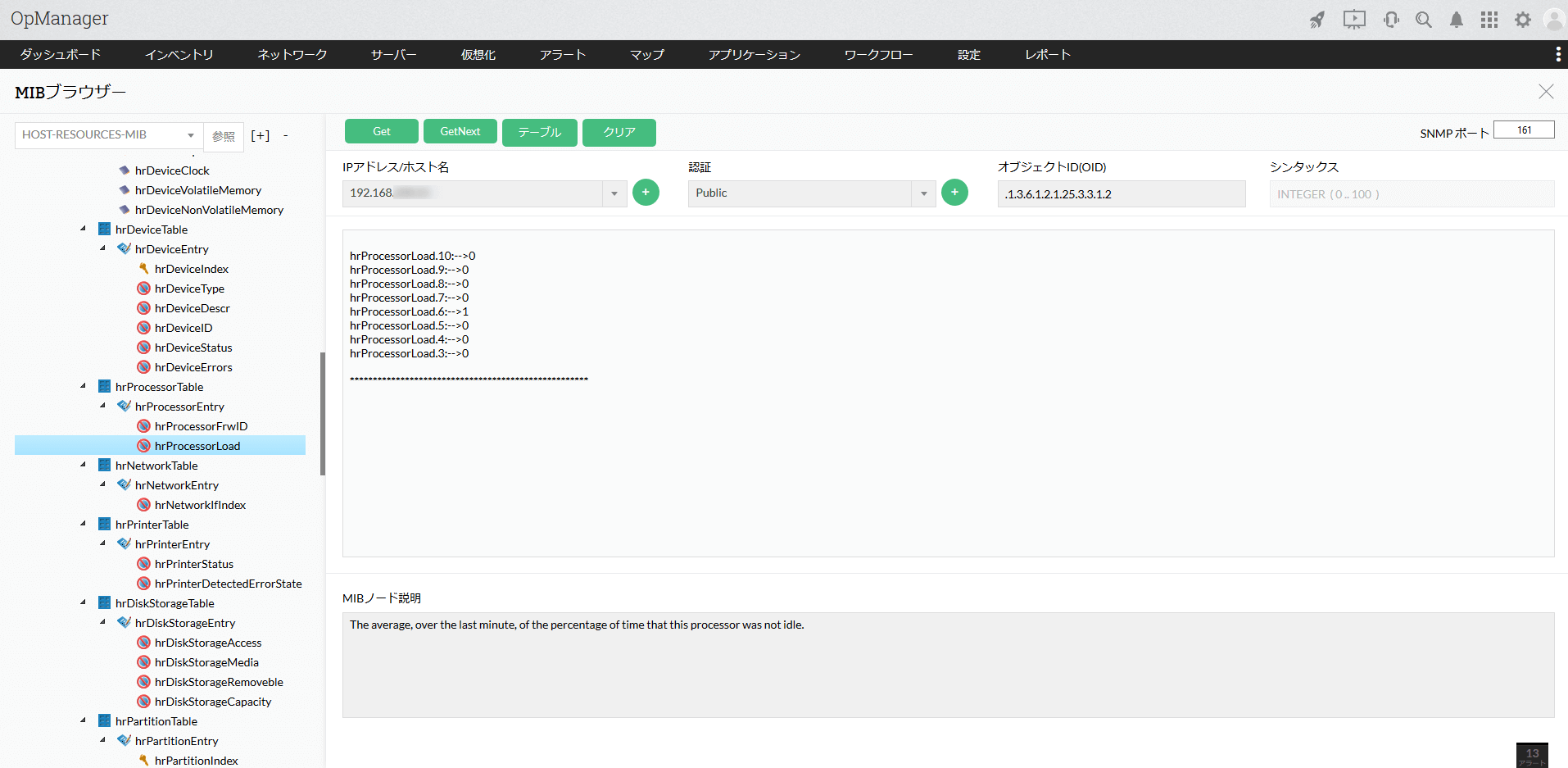





SNMPv1、SNMPv2、SNMPv3の3つのバージョンがあります。

SNMPv1とSNMPv2は、セキュリティが弱いのであまり使われていません。
以下の記事で取り上げているSNMPリフレクター攻撃では、SNMPv2に対応し、コミュニティ名(SNMPでのパスワード的なもの)が初期値の「public」に設定されている機器をターゲットにしていたそうです。
www.itmedia.co.jp
SNMPv3は、セキュリティが強化されてPDUの暗号化ができるのが特徴です。
SNMPv1とSNMPv2では、コミュニティ名による認証をしていました。
PDUは、制御情報をくっつけたデータの送受信単位のことです。
- 英語 : Protocol Data Unit
- 読み方 : ピーディーユー
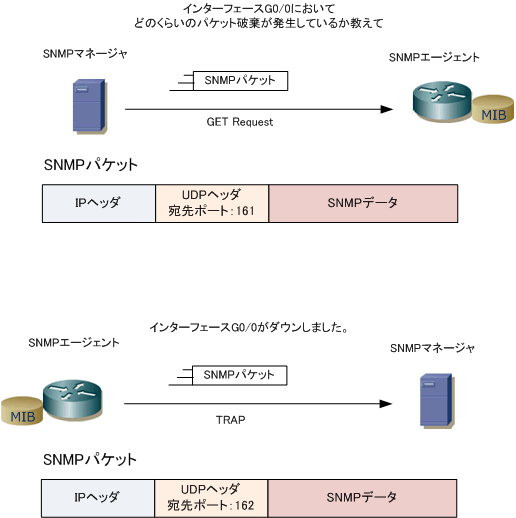
転送フレームでのSNMPメッセージ
GetRequest/GetNextRequest/SetRequest/GetResponseのPDU構造
TrapのPDU構造
どのようにしてネットワークを管理するのか?:監視を自動化するSNMP(2) - @IT
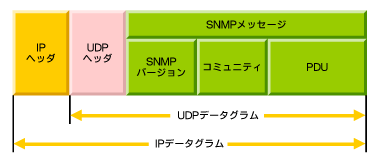
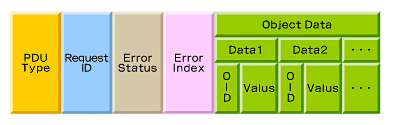
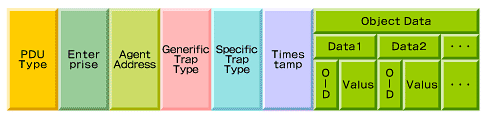

SNMPのPDUには種類があります。
| 名前 | 細かい名前 | UDPタイプ | 説明 |
|---|---|---|---|
| ポーリング | - | - | SNMPマネージャがSNMPエージェントにリクエストを送って情報を収集する |
| ポーリング | GET REQUEST | 0 | 一部の管理情報を取得する |
| ポーリング | GETNEXT REQUEST | 1 | 次に連続する管理情報を取得する |
| ポーリング | GET RESPONSE | 2 | SNMPマネージャからの要求に対するSNMPエージェントの返答 |
| ポーリング | SET REQUEST | 3 | 管理するサブシステムに対して変更を加える |
| トラップ | - | 4 | SNMPエージェントがSNMPマネージャに障害の情報を送る |
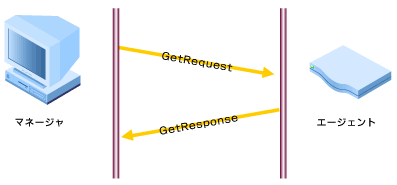
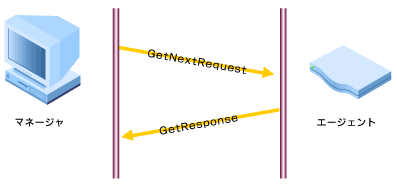
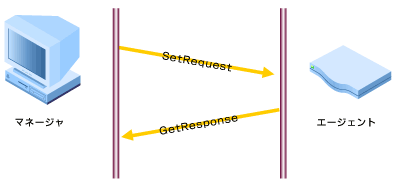

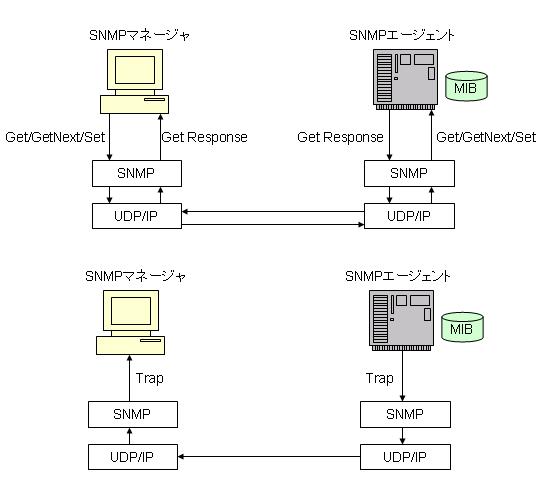

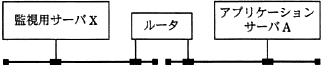
事象の発生をエージェントが自発的にマネージャに知らせるために使用するのがトラップです。
図で示したネットワーク構成において,アプリケーションサーバA上のDBMSのデーモンが異常終了したという事象とその理由を,監視用サーバXで検知するのに有効な手段はどれか。
答. アプリケーションサーバAから監視用サーバXへのSNMPトラップ
応用情報技術者平成24年春期 午前問35
SNMPマネージャとSNMPエージェントは、MIBをやり取りします。

MIBは、機器の設定や状態などの情報集合体のことです。
- 英語 : Management Information Base
- 読み方 : みぶ
MIBは、ASN.1という記法に従って定義されています。
- 英語 : Abstract Syntax Notation One
- 日本語 : 抽象構文記法1
ASN.1(Abstract Syntax Notation One = 抽象構文記法1)は、情報の構造定義の言語です。 通信プロトコルのフォーマットを規定するための言語で、 SNMPのMIBの記述、証明書:デジタル署名、LDAP,、Kerberos、TCなど多くのプロトコルで使用されています。
http://www5d.biglobe.ne.jp/stssk/asn1/index.html
SNMPエージェントは、MIBの内容で機器の状態を判断します。
サーバやネットワーク機器のMIB(Management Information Base)情報を分析し,中間者攻撃を遮断する。
応用情報技術者平成29年秋期 午前問38

次回の勉強内容
勉強中・・・
LANセグメントを分ける仮想LAN、VLANのお話
- 前回の勉強内容
- 勉強のきっかけになった問題
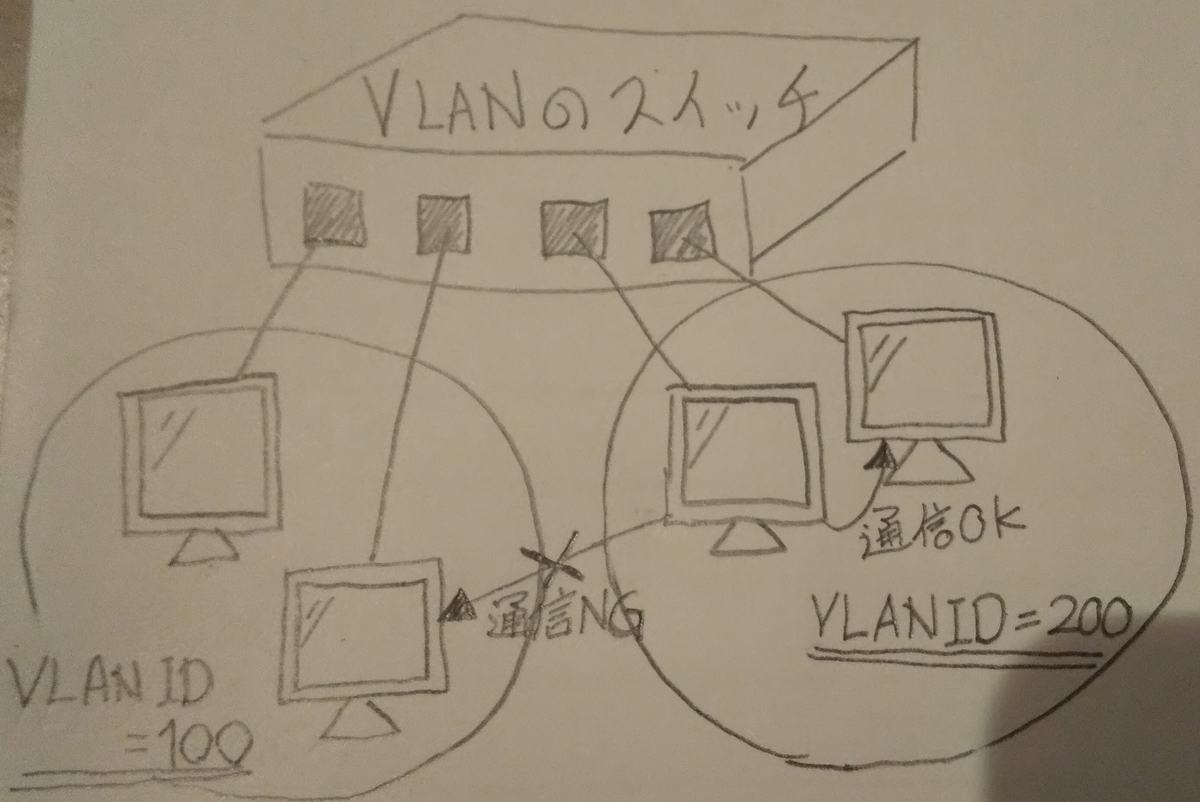
- VLANは、1つの物理的スイッチで複数のスイッチがあるみたいにLANセグメントを分けることができる技術です。
- VLANは、LANセグメントの分割方法によって方式があります。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
VLAN機能をもった1台のレイヤ3スイッチに複数のPCを接続している。スイッチのポートをグループ化して複数のセグメントに分けると、スイッチのポートをセグメントを分けない場合に比べて、どのようなセキュリティ上の効果が得られるか。
VLANは、1つの物理的スイッチで複数のスイッチがあるみたいにLANセグメントを分けることができる技術です。
- 正式名称 : Virtual Local Area Network(Virtual LAN)
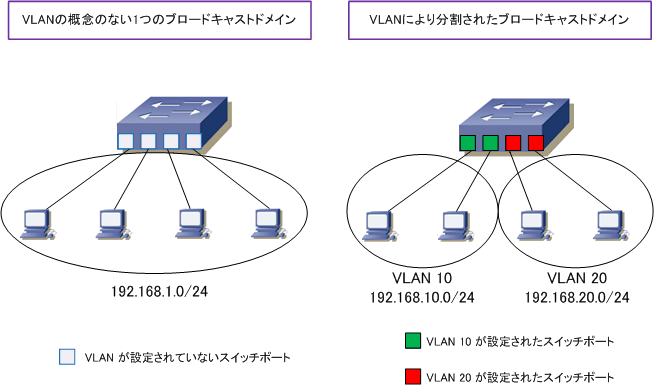
VLANではない場合、1つの物理スイッチには1つのLANセグメントがあります。
VLANにすると、まるで複数のスイッチがあるように複数のLANセグメントに分割することができます。
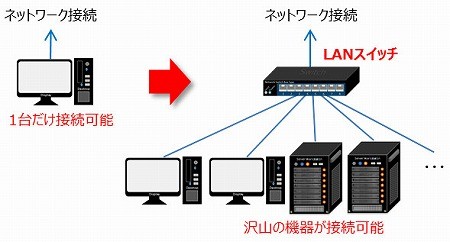
LANスイッチは、複数の機器をネットワークと接続できるようにする機器です。
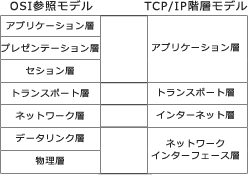
| OSI参照モデル | 機器 | 説明 |
|---|---|---|
| ネットワーク層 | L3スイッチ | ネットワークの中継機器の一つで、 ネットワーク層とリンク層の両方の制御情報に基づいてデータの転送先の決定を行います。 |
| データリンク層 | L2スイッチ | MACアドレスを含んだ情報を使って 適切なポートにイーサネットフレームを転送します。 |

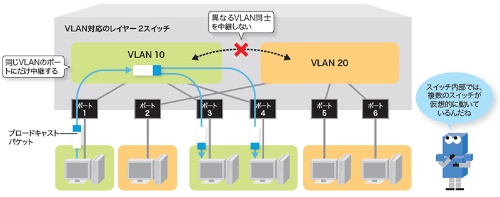
スイッチ内に作られた仮想スイッチのポートを物理的なポートに割り当てることでLANセグメントを分割します。
VLAN対応スイッチでは、仮想的に作られたスイッチ、いわゆる仮想スイッチがスイッチ内部で動いている。スイッチの物理ポートを仮想スイッチのポートに割り当てることで、ネットワークの分割を実現している。
ポートVLANとタグVLANの違いとは? | 日経クロステック(xTECH)
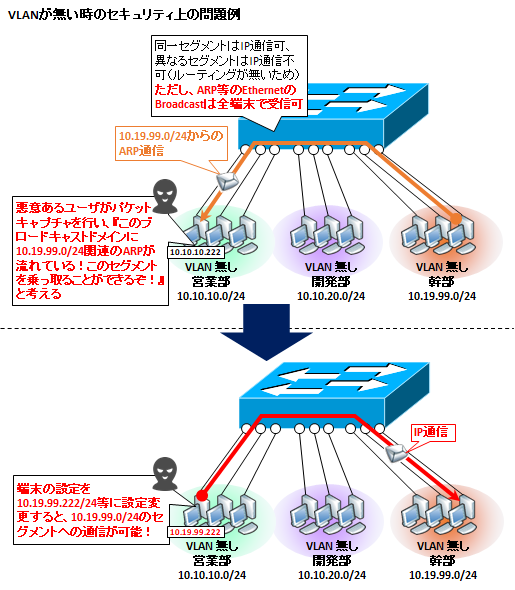
ブロードキャストドメインを分割できるので、他のセグメントへのARPを防止します。
ARPは、IPアドレスからMACアドレスを取得するために使われるプロトコルです。
ponsuke-tarou.hatenablog.com
スイッチが、PCからのブロードキャストパケットの到達範囲を制限するので、アドレス情報の不要な流出のリスクを低減できます。

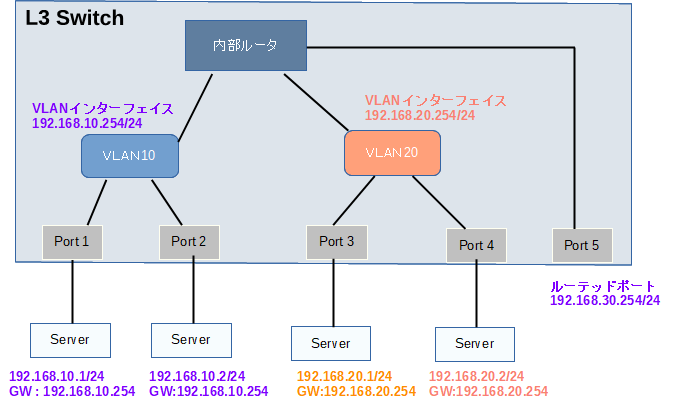
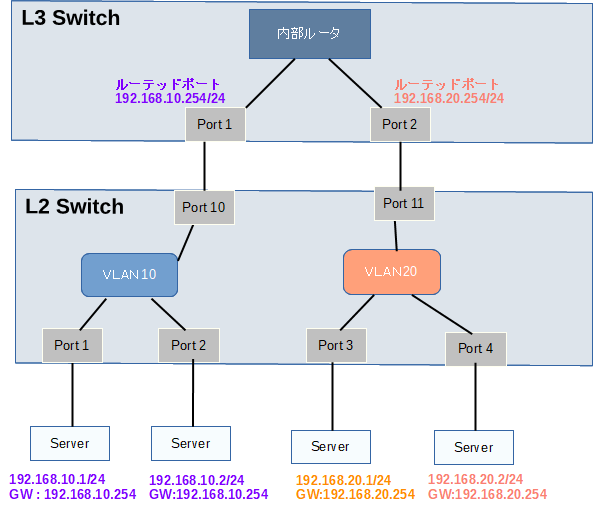
L3スイッチの内部ルーターを使うことで分割したLANセグメント同士を接続することができます。
L3スイッチは、L2スイッチの内部にルーターの機能を組込んでルーターによるVLAN間ルーティングをするネットワーク機器です。
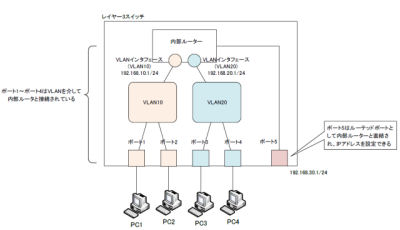
LANセグメントごとにIPアドレスを割り当てて、LANセグメント同士を接続します。
各VLANを識別するために割り振られる番号をVLAN IDといいます。
| VLAN ID | 用途 |
|---|---|
| 0 | VLANにも属していないフレームであることを表す特殊なID |
| 4095 | システム用 |
VLANは、LANセグメントの分割方法によって方式があります。
| 名前 | 概要 |
|---|---|
| デフォルトVLAN(VLAN1) | L2スイッチの初期状態で、1だけが設定されているVLANです。 VLAN1だけなのでLANセグメントは分割されず1つだけです。 |
| プライベートVLAN | 同一VLAN内でのアクセス制御が可能なVLANです。 |
| ダイナミックVLAN | スイッチに接続する機器のMACアドレスやユーザー情報によって自動で割り当てるVLANを決めます。 |
| ポートベースVLAN | スイッチにの差込口(ポート)でLANセグメントを分割します。 |
| タグVLAN | フレームにタグをつけてVLANを見分けます。 |
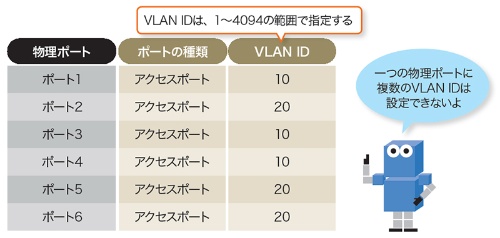
ポートベースVLANは、複数のポートを論理的なグループにまとめグループ内だけの通信を可能にします。
- 別名 : ポートVLAN、スタティックVLAN
ポートベースVLAN
スイッチの接続ポート単位でグルーピング
ソフトウェア開発技術者平成18年秋期 午前問59
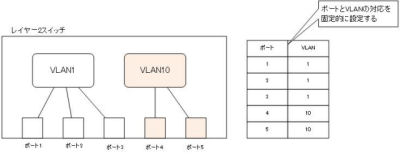
物理的なポートごとにLANセグメントを分割するので、1つのポートにつけられるVLAN IDは1つです。
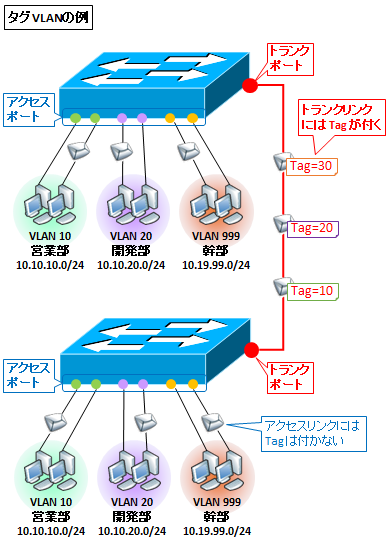
タグVLANは、イーサネットフレームにタグ情報を挿入してフレーム単位でLANセグメントを分割します。
- 英語 : tag VLAN
- 別名 : タギングVLAN
イーサネットフレームのタグで判別するので、1つのポートに複数のVLAN IDをつけられます。
タグVLAN (Tag VLAN) とは、複数のVLANを1本のLAN 接続だけで複数スイッチ間で共有できる技術です。IEEE802.1qという規格で規定されており、VLAN IDは1~4094が使えます。
【図解】タグVLANとネイティブVLAN (PVID)の違い,native vlanを変更する理由,不一致による影響 | SEの道標
イーサネットフレームは、イーサネットでの通信で使用するデータフォーマットのことです。
ponsuke-tarou.hatenablog.com
タグのフォーマットは、IEEE802.1Q(通称 : ドット1キュー)で標準化されています。
トランクプロトコルのまとめ ~IEEE802.1QとISL~ | VLAN(Virtual LAN)の仕組み | ネットワークのおべんきょしませんか?
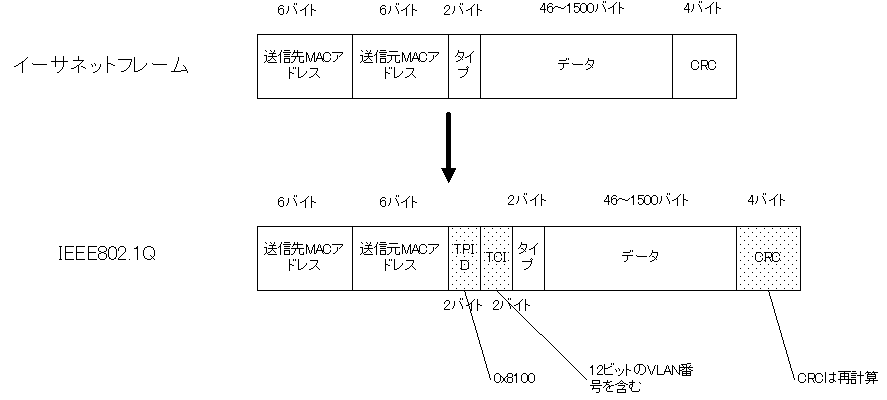
EEE802.1Qでは送信元MACアドレスとタイプフィールドの間にタグと呼ばれる4バイトのフィールドを挿入します。
VLAN - アクセスポートとトランクポート
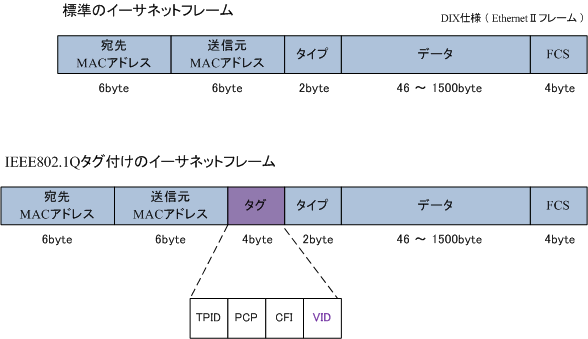
複数のVLANに所属しているポートをトランクポートといいます。
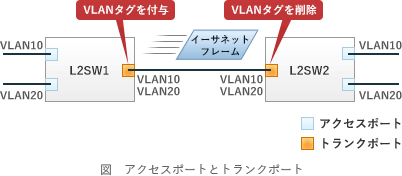
トランクポートは複数のVLANに所属するポートです。主にスイッチ同士を接続する際に使用するポートです。
VLAN - アクセスポートとトランクポート
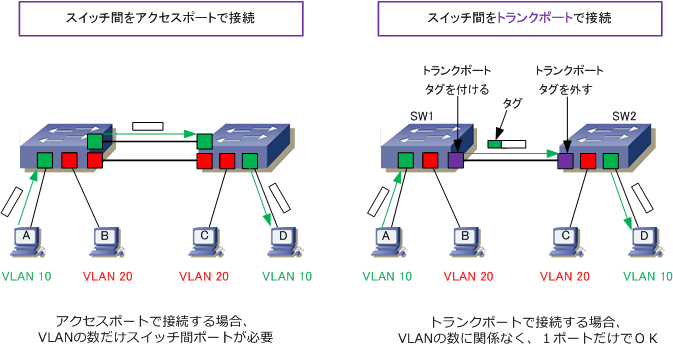
タグVLANで使う物理ポートをトランクポート、トランクポート同士をつなぐリンクを「トランクリンク」と呼ぶ。トランクポートには通常、パソコンなどの端末を接続せず、スイッチのトランクポート同士をつなぐために使う。
ポートVLANとタグVLANの違いとは? | 日経クロステック(xTECH)
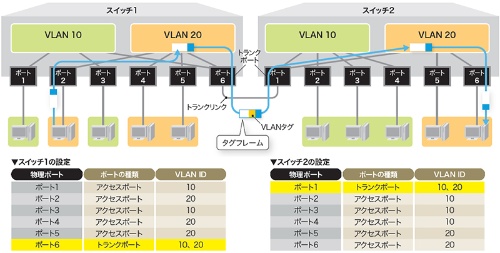

次回の勉強内容
RDSでOracleを作ってみる
- RDSでMySQLをつくってみました。
- RDSでOracleを作成してみます。
- EC2インスタンスから接続できるようにセキュリティグループを設定します。
- RDSへSQL*Plusで接続してみます。
- 自動停止するように自動停止時間をAutoStopタグに設定します。
- 失敗したこと
RDSでMySQLをつくってみました。
Oracleでもやりたいことができたので作ってみます。
ponsuke-tarou.hatenablog.com
EC2インスタンスから使えるRDSを作成します。
RDS作成予定のVPC内にある以前作成したEC2インスタンスから接続します。
ponsuke-tarou.hatenablog.com

RDSでOracleを作成してみます。
- AWS マネジメントコンソールで[RDS]を選択して、RDSの画面を表示します。
- [データベースの作成]ボタンで[データベースの作成]画面を表示します。
- 以下を設定して[データベースの作成]ボタン
- 画面上部に表示される[認証情報の詳細を表示]ボタンでパスワードを確認してどっかに記録しておきます。

パスワードを表示できるのはこのときだけです。
EC2インスタンスから接続できるようにセキュリティグループを設定します。
今回はRDSとEC2が同じVPC内にある構成なので、RDSのセキュリティグループに
- EC2のプライベートIP
- EC2のセキュリティグループID(sg-xxxx)
のどちらかをOracle用ポート(1521)に許可するように設定します。
MySQLを作成したときは、プライベートIPを設定したので
今回は、セキュリティグループIDを設定してみます。
セキュリティグループにEC2インスタンスのセキュリティグループIDを設定します。
EC2インスタンスのセキュリティグループIDを確認します。

RDSへSQL*Plusで接続してみます。
EC2インスタンスにSQLPlusをインストールします。
(停止していたら)RDSを起動します。
- データベースの一覧で作成したRDSを選択します。
- [アクション] > [開始]で起動します(少々時間がかかります)。
- 一覧の[ステータス]が「利用可能」になったら起動しています。
エンドポイントを確認します。
- データベース一覧から作成したDB 識別子のリンクから詳細画面を開きます。
- [接続とセキュリティ]タブ > [エンドポイント]に表示されている「{DB識別子}.xxxxx.{リージョン}.rds.amazonaws.com」がエンドポイントで接続情報となります。
Oracleにログインできました。
$ sqlplus64 admin/password@oracle-12.hoge.us-east-2.rds.amazonaws.com:1521/pondb SQL*Plus: Release 12.2.0.1.0 Production on 火 3月 10 11:45:48 2020 Copyright (c) 1982, 2016, Oracle. All rights reserved. 最終正常ログイン時間: 火 3月 10 2020 11:17:11 +00:00 Oracle Database 12c Standard Edition Release 12.2.0.1.0 - 64bit Production に接続されました。 SQL>
ユーザーを作成して好きに使っていきます。
自動停止するように自動停止時間をAutoStopタグに設定します。
MySQLのRDSを作ったときに設定したRDS自動停止用のLambdaで自動停止できるようにAutoStopタグを設定します。
ponsuke-tarou.hatenablog.com
- データベース一覧から作成したDB 識別子のリンクから詳細画面を開きます。
- [タグ]タブ > [追加]ボタンで[タグの追加] ウィンドウを表示します。
- [タグキー]に「AutoStop」と[値]に「自動停止したい時間」を入力して[追加]ボタンでタグを追加します。
失敗したこと
DBName must be less than 8 characters long.

- 事象 : [データベースの作成]画面の[データベースの作成]ボタンでエラーになった。
- 原因 : [最初のデータベース名]に指定したデータベース名の文字数が8文字以上だから。
- 対応 : 8文字未満のデータベース名を指定する。

EC2インスタンスのDockerコンテナにあるRedmineとGitHubを連携してみた記録
- GitHubと連携するプラグインをRedmineに追加します。
- GitHubのリポジトリにDeploy keysを登録してパスワードなしでクローンできるようにします。
- GitHub上のソースをクローンします。
- Redmineを設定します。
- リポジトリを自動更新する
- 失敗したこと
- GitHubと連携するプラグインをRedmineから削除する方法
- 環境
GitHubと連携するプラグインをRedmineに追加します。
プラグインを配置します。
# 1. DockerホストにログインしてDockerを動かせるユーザーに切り替えます。 $ sudo su - {Docker用ユーザー} [sudo] ponsuke のパスワード: 最終ログイン: 2019/09/04 (水) 18:53:50 JST日時 pts/0 # 2. Redmineコンテナが起動していることを確認します。 $ cd docker/host/ $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e943461bd3ad redmine:4.0.4 "/docker-entrypoint.…" 7 months ago Up 6 days 0.0.0.0:80->3000/tcp redmine_no_container # 3. DockerホストからRedmineコンテナのプラグイン用ディレクトリににプラグインをクローンします。 $ docker exec redmine_no_container git clone https://github.com/koppen/redmine_github_hook.git /path/to/redmine/plugins/redmine_github_hook Cloning into '/path/to/redmine/plugins/redmine_github_hook'... # 4. Redmineコンテナにログインします。 $ docker exec -it redmine_no_container bash # 5. プラグイン用ディレクトリに移動してクローン出来たことを確認します。 $ cd /path/to/redmine/plugins/redmine_github_hook/ $ ls -la | grep github -rw-r--r-- 1 root root 876 Feb 28 08:57 redmine_github_hook.gemspec # 6. Redmineコンテナからログアウトします。 $ exit # 7. Redmineコンテナを再起動します。 $ docker restart redmine_no_container redmine_no_container

GitHubのリポジトリにDeploy keysを登録してパスワードなしでクローンできるようにします。
コンテナで秘密鍵と公開鍵を作成します。
鍵を作成する際にパスフレーズを設定するとリポジトリをクローンだけでなくフェッチするときにも毎回パスフレーズの入力が必要になってしまうため、今回パスフレーズは設定しません。
※. パスフレーズの設定および解除は自己責任で実施してください。
# 1. DockerホストにログインしてDockerを動かせるユーザーに切り替えます。 $ sudo su - {Docker用ユーザー} [sudo] ponsuke のパスワード: 最終ログイン: 2020/02/28 (金) 17:22:13 JST日時 pts/0 # 2. Redmineコンテナにログインします。 $ cd docker/host/ $ docker exec -it redmine_no_container bash # 3. RSA鍵のペアを作成します。 # ssh-keygenコマンドはデフォルトで「ユーザー名@ホスト名」をコメントにします。なのでGitHubのユーザのメールアドレスをコメントとして-Cオプションで指定します。 $ ssh-keygen -t rsa -C ponsuke@mail.com Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): <<<< Enter Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): <<<< Enter Enter same passphrase again: <<<< Enter ...省略... # 4. 公開鍵を表示してコピーします。 $ cat /root/.ssh/id_rsa.pub ssh-rsa AAAAB3NzaC1yc2EAAAA... #

GitHub上のソースをクローンします。
# 1. リポジトリのクローン先用にディレクトリを作成します。 $ mkdir git $ ls -la | grep git drwxrwxr-x 2 redmine redmine 38 Jun 10 2019 .github -rw-rw-r-- 1 redmine redmine 761 Jun 10 2019 .gitignore drwxr-xr-x 2 root root 6 Mar 5 23:55 git # 2. 作成したディレクトリに移動します。 $ cd git/ # 3. ベアリポジトリをクローンします。 $ git clone --bare git@github.com:ponta/hoge.git Cloning into bare repository 'hoge.git'... Warning: Permanently added the RSA host key for IP address '12.345.67.89' to the list of known hosts. Enter passphrase for key '/root/.ssh/id_rsa': remote: Enumerating objects: 311, done. remote: Counting objects: 100% (311/311), done. remote: Compressing objects: 100% (191/191), done. remote: Total 19981 (delta 110), reused 232 (delta 42), pack-reused 19670 Receiving objects: 100% (19981/19981), 11.54 MiB | 7.12 MiB/s, done. Resolving deltas: 100% (12399/12399), done. $
Redmineを設定します。
- Redmineにログインします。
- 連携するプロジェクトを選択します。
リポジトリを設定します。
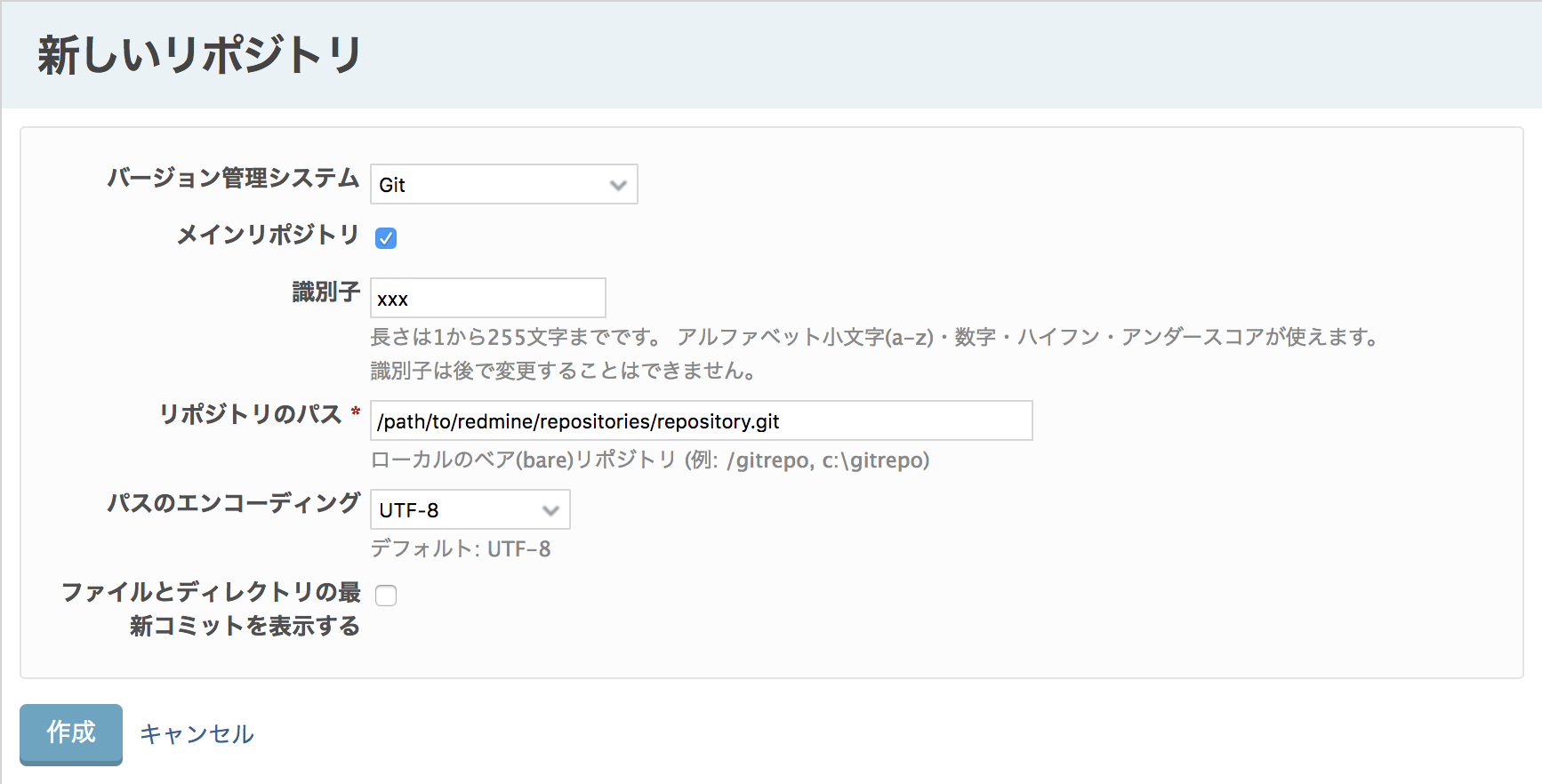


Redmine上にクローンしたベアリポジトリを更新します。
# 1. DockerホストにログインしてDockerを動かせるユーザーに切り替えます。 $ sudo su - {Docker用ユーザー} [sudo] ponsuke のパスワード: 最終ログイン: 2019/09/04 (水) 18:53:50 JST日時 pts/0 # 2. Redmineコンテナにログインします。 $ docker exec -it redmine_no_container bash # 3. リポジトリのクローン先に移動します。 $ cd git/hoge.git # 4. ベアリポジトリを更新します。 $ git fetch origin 'refs/heads/*:refs/heads/*'
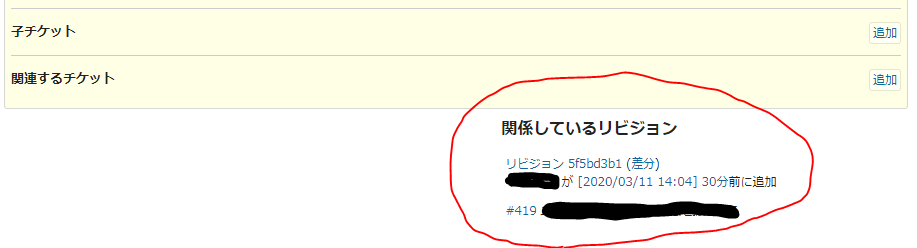
チケットに関連付くコミットがあるとチケットに表示されます。
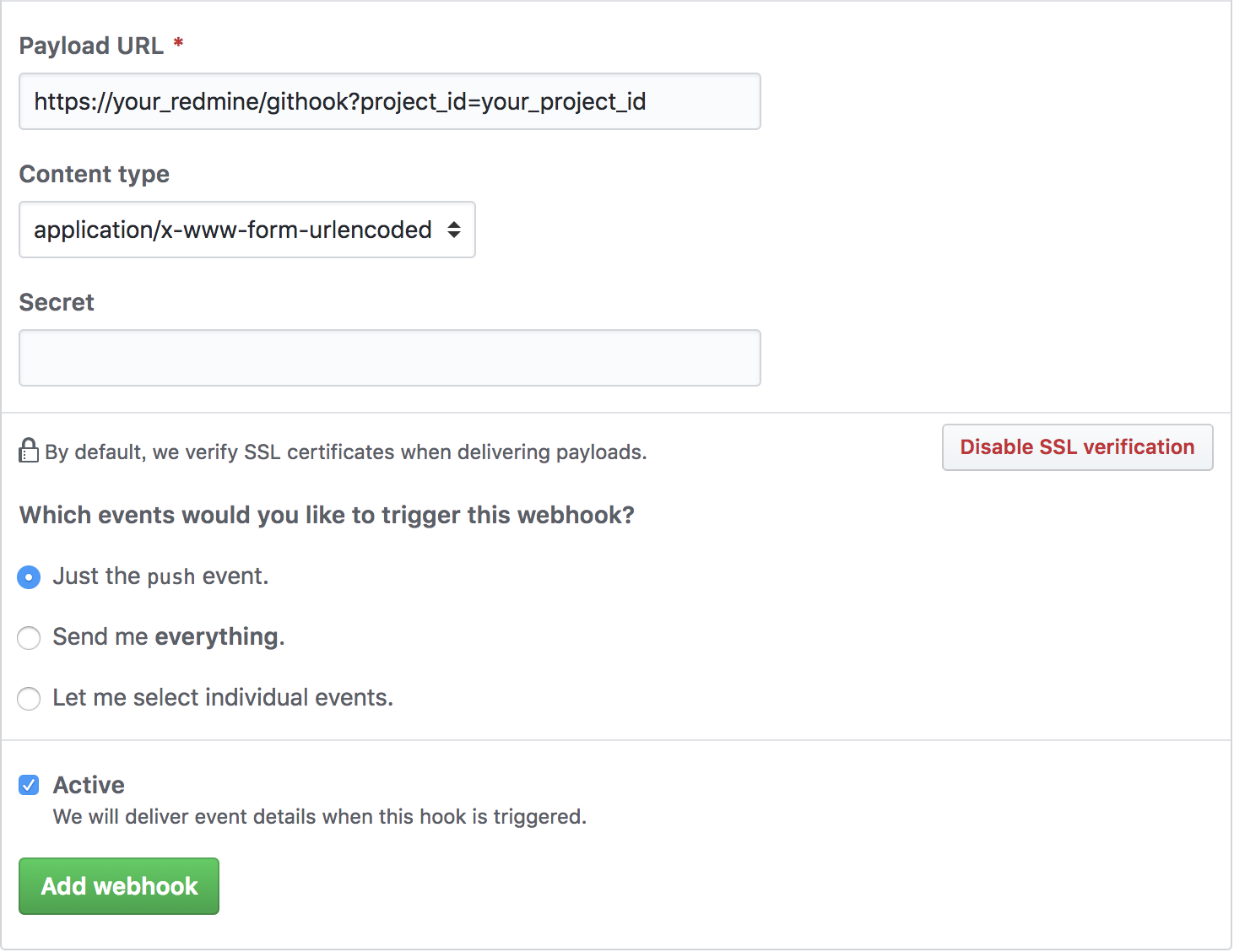
リポジトリを自動更新する
方法1つめ : GitHubにWebhookの設定を行います
方法2つめ : cronにリポジトリをfetchするシェルを登録する
- 参考
失敗したこと
認証用の鍵にパスフレーズを設定して毎回入力が必要になってしまった。
GitHubの認証用の鍵を作成した際にパスフレーズを設定しました。
その結果、フェッチのたびにパスフレーズの入力が必要となってしまいました。
そうすると自動でフェッチさせるのに困ります。なのでパスフレーズを解除します。
※. パスフレーズを解除するのは自己責任で実施してください。
対応 : (失敗)パスフレーズを解除できなかった。
コンテナにsudoコマンドがなくてうまくできませんでした。
$ cd /root/.ssh/ # バックアップします $ cp id_rsa id_rsa.org $ ls -la | grep id_rsa -rw------- 1 root root 1876 Mar 5 23:28 id_rsa -rw------- 1 root root 1876 Mar 15 23:39 id_rsa.org -rw-r--r-- 1 root root 408 Mar 5 23:28 id_rsa.pub # パスフレーズを解除しますが、パスフレーズを入力するはずが・・・エラーに・・・ $ openssl rsa -in id_rsa -out id_rsa unable to load Private Key 14068536:error:0909006C:PEM routines:get_name:no start line:../crypto/pem/pem_lib.c:745:Expecting: ANY PRIVATE KEY # パスフレーズをコマンドと合わせて入力してもエラーに・・・ $ openssl rsa -in id_rsa -passin pass:othelve2020 -out id_rsa unable to load Private Key 14068576:error:0909006C:PEM routines:get_name:no start line:../crypto/pem/pem_lib.c:745:Expecting: ANY PRIVATE KEY # コンテナには必要最低限のコマンドしかないためsudoすらなかった・・・(そもそもログインユーザーがrootなので意味ないかも) $ sudo openssl rsa -in id_rsa -out id_rsa bash: sudo: command not found
対応 : 認証鍵を作り直します。
# 認証鍵をパスフレーズなしで再作成します。 $ ssh-keygen -t rsa -C ponsuke@mail.com Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): <<<< Enter Enter passphrase (empty for no passphrase): <<<< Enter Enter same passphrase again: <<<< Enter ...省略... # 公開鍵を表示してコピーして再登録します。 $ cat id_rsa.pub ssh-rsa AAAAAAA...省略...
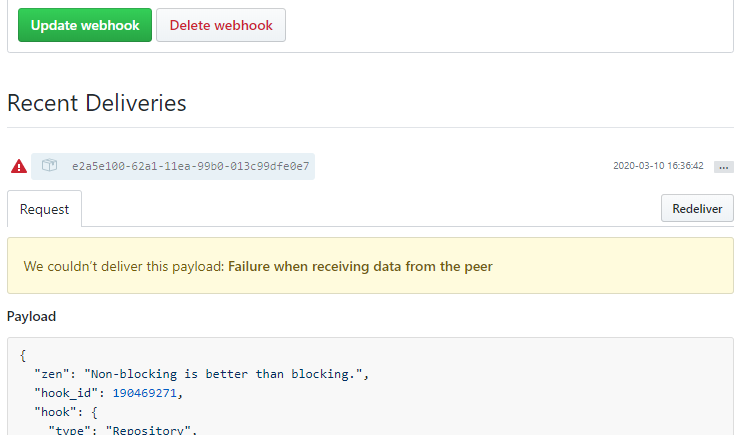
(未解決)We couldn’t deliver this payload: Failure when receiving data from the peer
GitHubと連携するプラグインをRedmineから削除する方法
# 1. DockerホストにログインしてDockerを動かせるユーザーに切り替えます。 [ponsuke@host ~]$ sudo su - {Docker用ユーザー} # 2. Redmineコンテナにログインします。 [{Docker用ユーザー}@host ~]$ docker exec -it redmine_no_container /bin/bash root@redmine_no_container:redmine# ls -l plugins/ #...省略... drwxr-xr-x 8 root root 229 Feb 28 2020 redmine_github_hook # << 削除するプラグイン #...省略... # 3. プラグインをアンインストールします。 root@redmine_no_container:redmine# bundle exec rake redmine:plugins:migrate NAME=redmine_github_hook VERSION=0 RAILS_ENV=production W, [2022-03-21T23:54:03.645901 #6913] WARN -- : Creating scope :system. Overwriting existing method Enumeration.system. # 4. プラグインのディレクトリを削除します。 root@redmine_no_container:redmine# rm -rf plugins/redmine_github_hook # 5. クーロンを削除します。 root@redmine_no_container:redmine# cat /etc/cron.d/git-cron */5 * * * * root redmine/git/git-fetch.sh >> /var/log/cron.log 2>&1 root@redmine_no_container:redmine# rm /etc/cron.d/git-cron # 6. クーロンに登録されていたシェルを削除します。 root@redmine_no_container:redmine# rm git/git-fetch.sh # 7. Redmineに連携していたリポジトリをクローンしたディレクトリを削除します。 root@redmine_no_container:redmine# rm -rf git/ncd-tavi-src-01.git/ # 8. Redmineコンテナからログアウトします。 root@redmine_no_container:redmine# exit exit # 9. コンテナを再起動します。 [{Docker用ユーザー}@host ~]$ docker restart redmine_no_container redmine_no_container
UbuntuにSQL*Plusをインストールする方法
- 以前、Windows10にSQL*Plusをインストールしました。
- rpmをダウンロードします。
- Alienコマンドでrpmパッケージをdebパッケージに変換します。
- SQL*Plusをインストールします。
- SQL*Plusを起動してみます。
- 失敗したこと
以前、Windows10にSQL*Plusをインストールしました。
ponsuke-tarou.hatenablog.com
RDSのOracleにEC2のUbuntuからSQL*Plusを使って接続したいと思います。
なので今回は、EC2のUbuntuにSQL*Plusをインストールしたいと思います。
rpmをダウンロードします。
インスタンスタイプが小さく動きが悪いのでダウンロードだけリモートデスクトップ接続で行い、あとはSSH接続してコマンドで実施します。
- リモートデスクトップ用ユーザーでUbuntuにリモートデスクトップ接続してブラウザを起動します。
- Oracleのサイトからからパッケージをダウンロードします。
- 32bit用 : Instant Client for Linux x86 (32-bit)
- 64bit用 : Instant Client for Linux x86-64 (64-bit) | Oracle 日本
- ダウンロードするにはOracleアカウント(無料)での認証が必要です。
- ダウンロードするファイル(xxxは32bitか64bitかによって違います)
- ダウンロード先 : リモートデスクトップ用ユーザーのDownloadsディレクトリ
Alienコマンドでrpmパッケージをdebパッケージに変換します。
Alienをインストールします。
Ubuntuは、Debian GNU/Linuxをベースとしたオペレーティングシステムです。
Debianでは、debパッケージでソフトウエアをインストールします。
Alienは、rpmをdebパッケージに変換してくれるプログラムです。
# 1. SSHでUbuntuに接続します。 $ ssh -i .ssh/秘密鍵.pem ubuntu@xx.xx.xx.xx Welcome to Ubuntu 18.04.4 LTS (GNU/Linux 4.15.0-1060-aws x86_64) * Documentation: https://help.ubuntu.com # ...省略... Last login: Fri Mar 6 12:27:00 2020 from 153.242.66.11 # 2. aptでAlienを検索します。 $ apt search alien Sorting... Done Full Text Search... Done alien/bionic 8.95 all # <<<<< これをインストールします。 convert and install rpm and other packages alien-arena/bionic 7.66+dfsg-4 amd64 Standalone 3D first person online deathmatch shooter # ...省略... # 3. Alienをインストールします。 $ sudo apt -y install alien Reading package lists... Done Building dependency tree Reading state information... Done # ...省略... Processing triggers for man-db (2.8.3-2ubuntu0.1) ... # 4. インストールされたことの確認にバージョンを確認します。 $ alien --version alien version 8.95
rpmパッケージをdebパッケージに変換します。
# 1. rpmのダウンロード先であるリモートデスクトップのユーザーのDownloadsディレクトリに移動します。 $ cd /home/ponsuke/Downloads/ $ ls -la | grep rpm -rw-rw-r-- 1 ponsuke ponsuke 26731248 Mar 6 21:42 oracle-instantclient12.2-basiclite-12.2.0.1.0-1.x86_64.rpm -rw-rw-r-- 1 ponsuke ponsuke 708104 Mar 6 21:44 oracle-instantclient12.2-sqlplus-12.2.0.1.0-1.x86_64.rpm # 2. rpmパッケージをdebパッケージに変換します。 $ sudo alien -c oracle-instantclient12.2-basiclite-12.2.0.1.0-1.x86_64.rpm oracle-instantclient12.2-basiclite_12.2.0.1.0-2_amd64.deb generated # -cオプション : パッケージのインストール時・アンインストール時に実行されるスクリプトも変換する $ sudo alien -c oracle-instantclient12.2-sqlplus-12.2.0.1.0-1.x86_64.rpm oracle-instantclient12.2-sqlplus_12.2.0.1.0-2_amd64.deb generated
SQL*Plusをインストールします。
dpkgコマンドでインストールします。
「dpkg」とはdebianのパッケージである「deb」ファイルを取り扱うコマンドである。名前の由来は「Debian Package」の略とされている。
Debianのパッケージ管理システムは他のディストリビューションに比べて最も高度な部類だ。
dpkg単体でもパッケージのインストールやアンインストールは一応に可能だが、実際にはパッケージの操作及び統合管理は「apt」系のコマンド「apt-get」や「aptitude」などで行なわれる。これにより依存関係の解決が行われ、必要なパッケージが自動的に導入される。
debファイルを扱うdpkgコマンドの使い方を簡単解説
# 1. dpkgコマンドでインストールします。 $ sudo dpkg -i oracle-instantclient12.2-basiclite_12.2.0.1.0-2_amd64.deb oracle-instantclient12.2-sqlplus_12.2.0.1.0-2_amd64.deb Selecting previously unselected package oracle-instantclient12.2-basiclite. (Reading database ... 157738 files and directories currently installed.) Preparing to unpack oracle-instantclient12.2-basiclite_12.2.0.1.0-2_amd64.deb ... Unpacking oracle-instantclient12.2-basiclite (12.2.0.1.0-2) ... Selecting previously unselected package oracle-instantclient12.2-sqlplus. Preparing to unpack oracle-instantclient12.2-sqlplus_12.2.0.1.0-2_amd64.deb ... Unpacking oracle-instantclient12.2-sqlplus (12.2.0.1.0-2) ... Setting up oracle-instantclient12.2-basiclite (12.2.0.1.0-2) ... Setting up oracle-instantclient12.2-sqlplus (12.2.0.1.0-2) ... Processing triggers for libc-bin (2.27-3ubuntu1) ... # 2. イントールされたことを確認します。 $ which sqlplus64 /usr/bin/sqlplus64
SQL*Plus用の環境変数を.profileに設定します。
- 参考
# 1. ログインユーザーのホームディレクトリに戻ります。 $ cd ~ $ ls -la | grep profile -rw-r--r-- 1 ubuntu ubuntu 807 Apr 4 2018 .profile # 2. インストール先を確認します。 $ find /usr/lib/oracle/12.2/client64/ -type d /usr/lib/oracle/12.2/client64/ /usr/lib/oracle/12.2/client64/lib /usr/lib/oracle/12.2/client64/bin # 3. SQL*Plus用の環境変数を.profileに設定します。 $ vi .profile # ↓ここから追記するところ # SQL*Plusのインストール場所を指定する環境変数。 export ORACLE_HOME=/usr/lib/oracle/12.2/client64 # UNIXおよびLinux上のライブラリの検索に使用するパスを指定する環境変数。 export LD_LIBRARY_PATH=$ORACLE_HOME/lib:$LD_LIBRARY_PATH # グローバリゼーション機能を指定する環境変数。 export NLS_LANG=Japanese_Japan.UTF8 export PATH=$ORACLE_HOME/bin:$PATH # ↑ここまで追記するところ # 4. 環境変数を反映します。 $ source .profile # 5. 環境変数を確認します。 $ printenv | grep -i oracle LD_LIBRARY_PATH=/usr/lib/oracle/12.2/client64/lib: ORACLE_HOME=/usr/lib/oracle/12.2/client64 PATH=/usr/lib/oracle/12.2/client64/bin:...省略...
SQL*Plusを起動してみます。
# 起動しました。 $ sqlplus64 SQL*Plus: Release 12.2.0.1.0 Production on 月 3月 9 14:17:17 2020 Copyright (c) 1982, 2016, Oracle. All rights reserved. ユーザー名を入力してください:

Ubuntuにmysqlコマンドをインストールする
RDSに接続するために使いたいのでMySQLサーバーはインストールしません。
RDSにつくったMySQLに接続するのでmysqlコマンドがほしいのです。
ponsuke-tarou.hatenablog.com
aptコマンドを使ってインストールします。
Ubuntuでは、パッケージ管理にyumではなくaptを使用するようなのでaptを使ってインストールします。
linuxfan.info
リポジトリ一覧を更新します。
注記
入手可能な最新バージョンを確実にダウンロードするために、インストールの前に apt-get インデックスファイルを更新してください。
MySQL :: MySQL 5.6 リファレンスマニュアル :: 2.5.7 ネイティブソフトウェアリポジトリから MySQL を Linux にインストールする
$ sudo apt update Hit:1 http://us-east-2.ec2.archive.ubuntu.com/ubuntu bionic InRelease Hit:2 http://us-east-2.ec2.archive.ubuntu.com/ubuntu bionic-updates InRelease Hit:3 http://us-east-2.ec2.archive.ubuntu.com/ubuntu bionic-backports InRelease Hit:4 http://security.ubuntu.com/ubuntu bionic-security InRelease Reading package lists... Done Building dependency tree Reading state information... Done 29 packages can be upgraded. Run 'apt list --upgradable' to see them.
mysql-clientのパッケージを検索します。
$ apt search mysql-client Sorting... Done Full Text Search... Done default-mysql-client/bionic 1.0.4 all MySQL database client binaries (metapackage) default-mysql-client-core/bionic 1.0.4 all MySQL database core client binaries (metapackage) mysql-client/bionic-updates,bionic-security 5.7.29-0ubuntu0.18.04.1 all MySQL database client (metapackage depending on the latest version) mysql-client-5.7/bionic-updates,bionic-security 5.7.29-0ubuntu0.18.04.1 amd64 MySQL database client binaries mysql-client-core-5.7/bionic-updates,bionic-security 5.7.29-0ubuntu0.18.04.1 amd64 MySQL database core client binaries
mysql-client-coreをインストールします。
mysqlコマンドがほしいだけなのでコンパクトな「mysql-client-core-5.7」をインストールします。
参考 : mysql-clientとmysql-client-coreの違いは何ですか? - 初心者向けチュートリアル
$ sudo apt install mysql-client-core-5.7 Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: libaio1 The following NEW packages will be installed: libaio1 mysql-client-core-5.7 0 upgraded, 2 newly installed, 0 to remove and 29 not upgraded. Need to get 6648 kB of archives. After this operation, 30.5 MB of additional disk space will be used. Do you want to continue? [Y/n] y Get:1 http://us-east-2.ec2.archive.ubuntu.com/ubuntu bionic-updates/main amd64 libaio1 amd64 0.3.110-5ubuntu0.1 [6476 B] Get:2 http://us-east-2.ec2.archive.ubuntu.com/ubuntu bionic-updates/main amd64 mysql-client-core-5.7 amd64 5.7.29-0ubuntu0.18.04.1 [6642 kB] Fetched 6648 kB in 0s (46.6 MB/s) Selecting previously unselected package libaio1:amd64. (Reading database ... 85356 files and directories currently installed.) Preparing to unpack .../libaio1_0.3.110-5ubuntu0.1_amd64.deb ... Unpacking libaio1:amd64 (0.3.110-5ubuntu0.1) ... Selecting previously unselected package mysql-client-core-5.7. Preparing to unpack .../mysql-client-core-5.7_5.7.29-0ubuntu0.18.04.1_amd64.deb ... Unpacking mysql-client-core-5.7 (5.7.29-0ubuntu0.18.04.1) ... Setting up libaio1:amd64 (0.3.110-5ubuntu0.1) ... Setting up mysql-client-core-5.7 (5.7.29-0ubuntu0.18.04.1) ... Processing triggers for man-db (2.8.3-2ubuntu0.1) ... Processing triggers for libc-bin (2.27-3ubuntu1) ... # mysqlコマンドがインストールできたことを確認するためにバージョンを確認します。 $ mysql --version mysql Ver 14.14 Distrib 5.7.29, for Linux (x86_64) using EditLine wrapper
RDSのMySqlに接続してみます。

RDSのセキュリティグループを設定します。
今回はRDSとEC2が同じVPC内にある構成なので、RDSのセキュリティグループに
- EC2のプライベートIP
- EC2のセキュリティグループID(sg-xxxx)
のどちらかをMySQL用ポート(3306)に許可するように設定します。
mysqlコマンドでログインします。
$ mysql -h mysql-57.xxx.{リージョン}.rds.amazonaws.com -P 3306 -u admin -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 12 Server version: 5.7.28-log Source distribution Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
失敗したこと
E: Could not open lock file /var/lib/apt/lists/lock - open (13: Permission denied)
- 事象 : apt updateしたら怒られた
- 原因 : 実行権限がないから
- 対応 : rootに切り替えるかsudoで実行する
# 失敗 $ apt update Reading package lists... Done E: Could not open lock file /var/lib/apt/lists/lock - open (13: Permission denied) E: Unable to lock directory /var/lib/apt/lists/ W: Problem unlinking the file /var/cache/apt/pkgcache.bin - RemoveCaches (13: Permission denied) W: Problem unlinking the file /var/cache/apt/srcpkgcache.bin - RemoveCaches (13: Permission denied) # 対応後 $ sudo apt update Hit:1 http://us-east-2.ec2.archive.ubuntu.com/ubuntu bionic InRelease Hit:2 http://us-east-2.ec2.archive.ubuntu.com/ubuntu bionic-updates InRelease Hit:3 http://us-east-2.ec2.archive.ubuntu.com/ubuntu bionic-backports InRelease Hit:4 http://security.ubuntu.com/ubuntu bionic-security InRelease Reading package lists... Done Building dependency tree Reading state information... Done 29 packages can be upgraded. Run 'apt list --upgradable' to see them.
ERROR 2003 (HY000): Can't connect to MySQL server on
- 事象 : mysqlコマンドでRDSにログインできない。
- 原因 : RDSにEC2からの接続が許可されていないから
- 対応 : RDSのセキュリティグループを設定する
$ mysql -h mysql-57.xxx.{リージョン}.rds.amazonaws.com -P 3306 -u admin -p Enter password: ERROR 2003 (HY000): Can't connect to MySQL server on 'mysql-57.xxx.{リージョン}.rds.amazonaws.com' (110)

RDSでMySQLを作ってみる
RDSというものを知りました。
パソコンから直接使えるRDSを作成します。
VPC内のEC2インスタンスではなく、VPC外部からインターネットを経由して接続できるようにします。
一番簡単そうな以下の方法にチャレンジします(今回はお勉強用なので選びましたがお仕事用にはセキュリティが緩いです)。
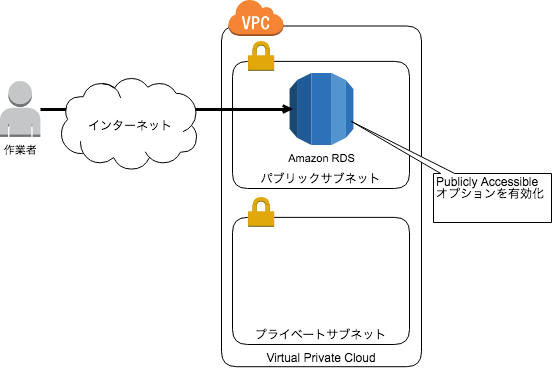
Publicly Accessible オプションを有効化して接続する
RDSをパブリックサブネットに配置し、Publicly Accessibleを有効にする方法です。 パブリックサブネットとは、インターネットゲートウェイへのルーティングが可能なサブネットです。 Publicly Accessibleを有効にすると、RDSのエンドポイントがパブリックIPアドレスに解決されます。 セキュリティグループでクライアントの拠点のIPアドレスだけ許可すれば、拠点からのみ接続できます。本番データを扱う場合などは、SSLを利用した暗号化を検討します。
手元の作業端末からAmazon RDSに接続する方法 | DevelopersIO
RDSでMySQLを作成してみます。
- AWS マネジメントコンソールで[RDS]を選択して、RDSの画面を表示します。
- [データベースの作成]ボタンで[データベースの作成]画面を表示します。
- 以下を設定して[データベースの作成]ボタン
- データベース作成方法を選択 : 標準作成
- エンジンのオプション
- テンプレート : 無料利用枠(お勉強用なので小さいサイズにしました)
- 設定
- 接続
- パブリックアクセス : あり
- この設定によりVPC外部から接続できるようになります。設定は自己責任でしてください。
- パブリックアクセス : あり
- データベース認証 : パスワードと IAM データベース認証
- 「パスワードと IAM データベース認証」を設定するとコマンドラインでIAM 認証を使用してDB インスタンスに接続できるようになります。
- 参考 : コマンドラインから IAM 認証を使用して、DB インスタンスに接続する: AWS CLI および mysql クライアント - Amazon Relational Database Service
- 追加設定
- 最初のデータベース名 : myDatabase(好きな名前でOK、指定なしにして作成しなくてもOK)
- ログのエクスポート : 全てにチェックON
- 削除保護の有効化 : ON
- 上記以外の設定値は規定値のまま
- 画面上部に表示される[認証情報の詳細を表示]ボタンでパスワードを確認してどっかに記録しておきます。

このパスワードを表示できるのはこのときだけです。
セキュリティグループに自分のパブリックIPアドレスを設定します。
- アクセス情報【使用中のIPアドレス確認】で自分のパブリックIPアドレスを確認します。
- データベースの一覧にある作成したRDSのDB識別子リンクで詳細画面を表示します。
- [接続とセキュリティ]にある[VPC セキュリティグループ]のリンクでセキュリティグループの画面を表示します。
- [インバウンド]タブの[編集]ボタンでダイアログを表示します。
- [ルールの追加]ボタンで行を追加して以下を設定します。
- [保存]ボタンで保存してダイアログを閉じます。

RDSへmysqlコマンドで接続してみます。
(停止していたら)RDSを起動します。
- データベースの一覧で作成したRDSを選択します。
- [アクション] > [開始]で起動します(少々時間がかかります)。
- 一覧の[ステータス]が「利用可能」になったら起動しています。
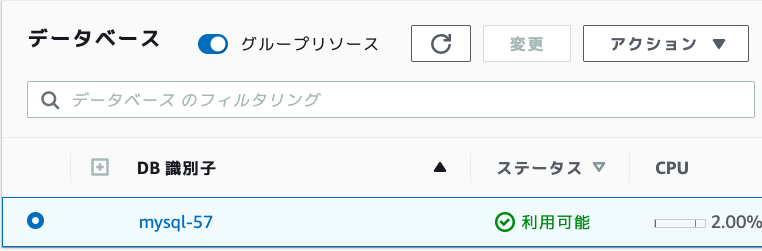
エンドポイントを確認します。
- データベース一覧から作成したDB 識別子のリンクから詳細画面を開きます。
- [接続とセキュリティ]タブ > [エンドポイント]に表示されている「{DB識別子}.xxxxx.{リージョン}.rds.amazonaws.com」がエンドポイントで接続情報となります。
MySQLにログインします。
| mysqlのオプション | 意味 |
|---|---|
| -h | MySQL サーバーに接続するホスト |
| -P | 接続に使用する TCP/IP ポート番号 |
| -p | サーバーに接続する際に使用するパスワードを聞く |
| -u | サーバーへの接続時に使用する MySQL ユーザー名 |
$ mysql -h mysql-80.xxx.{リージョン}.rds.amazonaws.com -P 3306 -u admin -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 21 Server version: 8.0.28 Source distribution Copyright (c) 2000, 2022, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | myDatabase | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.20 sec) mysql>
うまく接続できない場合は、RDSの[パブリックアクセシビリティ]またはセキュリティグループの設定が誤っています。
参考 : ERROR 2003 (HY000): Can't connect to MySQL server on - Qiita
自動停止するようにLambdaを設定します。
RDSは、停止していても7日で自動起動します。
そのまま使わずに放置しているとお金がかかります。
なので自動停止するようにします。
自動停止時間をAutoStopタグに設定します。
- データベース一覧から作成したDB 識別子のリンクから詳細画面を開きます。
- [タグ]タブ > [追加]ボタンで[タグの追加] ウィンドウを表示します。
- [タグキー]に「AutoStop」と[値]に「自動停止したい時間」を入力して[追加]ボタンでタグを追加します。


AWSのEC2インスタンスを祝日を除いた平日に自動起動するLambdaを作る記録
- EC2インスタンスを決まった時間に自動起動したいです。
- S3にバケットを作ります。
- 取得実リストを取得するLambda関数を作成します。
- EC2インスタンスを自動起動するLambda関数を作成します。
- 失敗したこと
EC2インスタンスを決まった時間に自動起動したいです。
起動しっぱなしでいいインスタンスですが、たまにうっかり誰かが停止しちゃったりします。
なので、始業時間になって停止していたら自動で起動してほしいです。
AutoStartタグに設定した時間になったら起動したいです。
起動したい時間は、時と共に変わるかもしれませんし、インスタンスによっても変わります。
なので、インスタンスに「AutoStart」というタグとその値に起動したい時間を設定します。
祝日は自動起動しないでほしいです。
平日(月~金曜日)にLambdaの実行を設定しても、祝日は意識してもらえません。
祝日は、使わないので節約のためにも起動しなくていいんです。
先人の知恵をパクッて使います。
S3にバケットを作ります。
祝日判定をするために使用するGoogleカレンダーの祝日リストを入れるためのバケットです。
祝日判定を行うにあたって、祝日のリストが必要になります。
今回はGoogleカレンダーで取得できる祝日リストを利用したいと思います。
下記URLから自由にダウンロードでき、現在から前後1年間を含む3年間分の祝日データが取得可能となっております。
https://www.google.com/calendar/ical/ja.japanese%23holiday%40group.v.calendar.google.com/public/basic.ics
Lambdaで祝日判定 | AWSやシステム・アプリ開発の最新情報|クロスパワーブログ


取得実リストを取得するLambda関数を作成します。
- AWSのコンソールにある[Lambda] > [関数の作成]ボタンで画面を開きます。
- 必要な項目を入力後に[関数の作成]ボタンで関数を作成します。
- オプション : [一から作成]
- 関数名 : get_google_holiday_list(任意の関数名でOK)
- ランタイム : Python3.8
- 実行ロール : 既存のロールを使用する
- 既存のロール : [lambda_basic_execution]を選択します。
- [関数の作成]ボタンで関数を作成します。
Lambda関数を実行するトリガーを作成します。
- [Designer]にある[トリガーを追加]ボタンでトリガーの設定画面を開きます。
- プルダウンから[CloudWatch Events]を選択します。
- 各入力欄を記載します。
- ルール : [新規ルールの作成]
- ルール名(必須) : get_google_holiday_list(任意の関数名でOK)
- ルールタイプ : [スケジュール式]
- スケジュール式 : cron(0 8 1 * ? *)(毎月1日の午前 8:00)
- [追加]ボタンでトリガーを追加する
関数を実装します。
import boto3 import urllib.request import re import os s3 = boto3.resource('s3') # Googleカレンダーの祝日リストを入れるためのバケット bucket = s3.Bucket('google-holiday-list') def write_holiday_list(list, file): for num in range(len(list)): pattern = r"DTSTART;VALUE=DATE:" # DTSTART;VALUE=DATE:yyyyMMddの行の正規表現 repattern = re.compile(pattern) target_line = list[num-1].decode('utf-8') match = repattern.search(target_line) if match is None: pass else: print('出力対象行:' + target_line) # 出力対象行(\r\n含む)の後ろから10文字目から8文字を出力する file.write(target_line[-10:-2] + '\n') return 0 def lambda_handler(event, context): # 祝日リストの取得元URL url = 'https://www.google.com/calendar/ical/ja.japanese%23holiday%40group.v.calendar.google.com/public/basic.ics' try: response = urllib.request.urlopen(url) list = response.readlines() except Exception as e: print('祝日リストの取得に失敗しました。') return 1 # 書き込みでファイルを開く f = open('/tmp/holiday.txt','w') write_holiday_list(list, f) f.close() data = open('/tmp/holiday.txt', 'rb') result = bucket.put_object(Key='holiday.txt', Body=data) data.close() os.remove('/tmp/holiday.txt')
使った関数の情報
- open : [Python入門]ファイル操作の基本 (1/3):Python入門 - @IT
- re : re --- 正規表現操作 — Python 3.8.2rc1 ドキュメント
- os : 【これでバッチリ!】Pythonのosモジュール使い方まとめ | 侍エンジニア塾ブログ(Samurai Blog) - プログラミング入門者向けサイト
- put_object() : S3 — Boto 3 Docs 1.12.0 documentation
- urllib.request : urllib.request --- URL を開くための拡張可能なライブラリ — Python 3.8.2rc1 ドキュメント
- スライスを使ってリストの指定した範囲の要素が含まれる新しいリストを取得する | Python入門
EC2インスタンスを自動起動するLambda関数を作成します。
- AWSのコンソールにある[Lambda] > [関数の作成]ボタンで画面を開きます。
- 必要な項目を入力後に[関数の作成]ボタンで関数を作成します。
- オプション : [一から作成]
- 関数名 : start_instances_by_tag_value(任意の関数名でOK)
- ランタイム : Python3.8
- 実行ロール : 既存のロールを使用する
- 既存のロール : [lambda_basic_execution]を選択します。
- [関数の作成]ボタンで関数を作成します。

Lambda関数を実行するトリガーを作成します。
- [Designer]にある[トリガーを追加]ボタンでトリガーの設定画面を開きます。
- プルダウンから[CloudWatch Events]を選択します。
- 各入力欄を記載します。
- ルール : [新規ルールの作成]
- ルール名(必須) : start_instances_by_tag_value(任意の関数名でOK)
- ルールタイプ : [スケジュール式]
- スケジュール式 : cron(0/10 8-11 ? * MON-FRI *) (平日AM8:00-11:00で10分毎)
- [追加]ボタンでトリガーを追加する


関数を実装します。
# -*- coding: utf-8 -*- from __future__ import print_function import sys import json from datetime import datetime, timedelta, timezone, date import boto3 import os DATETIME_FORMAT = '%Y-%m-%dT%H:%M:%SZ' JST = timezone(timedelta(hours=+9)) REGION_NAME = 'ap-northeast-1' TAG_NAME = 'AutoStart' TMP_HOLIDAY_FILE = '/tmp/holiday.txt' # CALENDAR_URL = "https://calendar.google.com/calendar/ical/ja.japanese%23holiday%40group.v.calendar.google.com/public/basic.ics" # NTP_URL = "http://ntp-b1.nict.go.jp/cgi-bin/json" print("Loading function") s3 = boto3.resource('s3') ec2 = boto3.client('ec2', REGION_NAME) def get_holiday_list(): """ S3バケットから祝日リストを取得する """ # Googleカレンダーの祝日リストを入れてあるバケット bucket = s3.Bucket('google-holiday-list') holiday_obj = bucket.Object('holiday.txt') with open(TMP_HOLIDAY_FILE, 'wb') as data: holiday_obj.download_fileobj(data) f = open(TMP_HOLIDAY_FILE) holiday_list = f.readlines() f.close() os.remove(TMP_HOLIDAY_FILE) return holiday_list def is_holiday(): """ 土日祝日判定処理 """ is_holiday = False day = date.today() today = day.strftime('%Y%m%d') week = day.weekday() holiday_list = get_holiday_list() check = today + '\n' in holiday_list if check == True: print('今日は祝日です。') is_holiday = True elif week == 5 or week == 6: print('今日は週末です。') is_holiday = True elif check == False: print('今日は平日です。') else: print('土日祝日判定に失敗しました') return is_holiday def get_tag(instance): """ TAG_NAMEのタグを配列で取得する. """ tag_list = instance['Tags'] tag = next(iter(filter(lambda tag: tag['Key'] == TAG_NAME and (tag['Value'] is not None and tag['Value'] != ''), tag_list)), None) return tag def get_tag_value_time(tag): """ タグに設定された時間を取得する. """ val = tag["Value"] if val == '': print('タグに時間が指定されていません。' + tag) return '' time = val.split(':') now = datetime.now(JST) tag_time = datetime(now.year, now.month, now.day, int(time[0]), int(time[1]), 0, 0, JST) return tag_time def is_start_instance(event, tag_time): utc_event_time = datetime.strptime(event["time"], DATETIME_FORMAT) print('実行時間(UTC)は、' + utc_event_time.strftime(DATETIME_FORMAT)) jst_event_time = utc_event_time.astimezone(JST) print('実行時間(JST)は、' + jst_event_time.strftime(DATETIME_FORMAT)) # AutoStopタグに指定された時刻の前後5分以内であればインスタンス起動する start_time_from = tag_time + timedelta(minutes=-5) start_time_to = tag_time + timedelta(minutes=5) print('実行時間(' + jst_event_time.strftime(DATETIME_FORMAT) + ')が、' + \ start_time_from.strftime(DATETIME_FORMAT) + 'から' + start_time_to.strftime(DATETIME_FORMAT) + 'だったら起動します。') return (start_time_from <= jst_event_time) and (jst_event_time <= start_time_to) def start_instance(event, instance): """ インスタンス起動処理 """ auto_start_tag = get_tag(instance) tag_time = get_tag_value_time(auto_start_tag) if tag_time == '': return print(instance['InstanceId'] + 'のタグに指定された時間(JST)は、' + tag_time.strftime(DATETIME_FORMAT)) if is_start_instance(event, tag_time): ec2.start_instances(InstanceIds=[instance['InstanceId']]) print(instance['InstanceId'] + 'を起動しました。') def lambda_handler(event, context): print("Received event: " + json.dumps(event, indent=2)) if is_holiday(): # 土日祝日なら処理終了 print('土日祝日は起動しません。') return # (停止している)かつ([AutoStart]タグのついている)インスタンス情報を取得する instances = ec2.describe_instances( Filters=[ {'Name': 'instance-state-name', 'Values': ['stopped']}, {'Name': 'tag-key', 'Values': [TAG_NAME]} ] )['Reservations'][0]['Instances'] if len(instances) > 0: # インスタンスを順番に処理していく for instance in instances: start_instance(event, instance)
使った関数の情報
- describe_instances : インスタンスの情報を辞書形式で取得する。
- download_fileobj() : Downloading Files — Boto 3 Docs 1.12.1 documentation
失敗したこと
'ec2.ServiceResource' object has no attribute 'describe_instances'
- 原因 : 使うオブジェクトを間違ってしまった。
- describe_instances()は、boto3.client('ec2')で取得したオブジェクトに含まれる関数なのに誤ってboto3.resource('ec2')で取得したオブジェクトで実行してしまった。
- 人のコードをコピペして使っているとこういうことが起こります。
ec2 = boto3.resource('ec2') #<<<< boto3.client('ec2')が正解 instances = ec2.describe_instances()
- 対応 : boto3.client('ec2')で取得したオブジェクトを使う
can't compare offset-naive and offset-aware datetimes
- 原因 : 異なるタイムゾーンのdatetimeオブジェクトを比較しているから
- 経緯 :
def get_tag_value_time(tag): ...省略... # 1. タイムゾーンを指定していなかった tag_time = datetime(now.year, now.month, now.day, int(time[0]), int(time[1])) print('タグに指定された時間(JST)は、' + tag_time.strftime(DATETIME_FORMAT)) return tag_time def is_start_instance(event, tag_time): ...省略... # 2. 実行時間はタイムゾーンをJSTにした jst_event_time = utc_event_time.astimezone(timezone(timedelta(hours=+9))) print('実行時間(JST)は、' + jst_event_time.strftime(DATETIME_FORMAT)) # AutoStopタグに指定された時刻の前後5分以内であればインスタンス起動する # 3. タイムゾーンはNoneになっていた start_time_from = tag_time + timedelta(minutes=-5) start_time_to = tag_time + timedelta(minutes=5) print('処理時間(' + jst_event_time.strftime(DATETIME_FORMAT) + ')が、' + \ start_time_from.strftime(DATETIME_FORMAT) + 'から' + start_time_to.strftime(DATETIME_FORMAT) + 'だったら起動します。') # 4. タイムゾーンがJSTとNoneのdatetimeオブジェクトを比較してエラーになった return (start_time_from <= jst_event_time) and (jst_event_time <= start_time_to) def start_instance(event, instance): ...省略... tag_time = get_tag_value_time(auto_start_tag) if is_start_instance(event, tag_time): ...省略...
- 調べた方法 : 各datetimeオブジェクトについてutcoffset()でタイムゾーンを確認した
print(tag_time.utcoffset()) # None print(jst_event_time.utcoffset()) # 9:00:00 print(start_time_from.utcoffset()) # None print(start_time_to.utcoffset()) # None
- 対応 : タグから取得した時間でdatetimeオブジェクトを作るときにタイムゾーンを指定する
JST = timezone(timedelta(hours=+9)) ...省略... def get_tag_value_time(tag): ...省略... tag_time = datetime(now.year, now.month, now.day, int(time[0]), int(time[1]), 0, 0, JST) print('タグに指定された時間(JST)は、' + tag_time.strftime(DATETIME_FORMAT)) return tag_time
Unable to import module 'lambda_function': No module named 'urllib2'
- 原因 : Python 3から urllib2 モジュールがなくなったから
import urllib2
...省略...
response = urllib2.urlopen(url)
注釈 urllib2 モジュールは、Python 3 で urllib.request, urllib.error に分割されました。 2to3 ツールが自動的にソースコードのimportを修正します。
20.6. urllib2 --- URL を開くための拡張可能なライブラリ — Python 2.7.17 ドキュメント
- 対応 : urllib.requestを使う
import urllib.request
...省略...
response = urllib.request.urlopen(url)
cannot use a string pattern on a bytes-like object
- 原因 : byte型とstr型を比較するから
- type関数で型を調べるとbyte型とstr型でした。
pattern = r"DTSTART;VALUE=DATE:" # DTSTART;VALUE=DATE:yyyyMMddの行の正規表現 repattern = re.compile(pattern) print(type(pattern)) # >>>>>>>>>>>>>>>>>>> <class 'str'> print(type(list[num-1])) #>>>>>>>>>>>>>>>>> <class 'bytes'> print(list[num-1]) #>>>>>>>>>>>>>>>>>>>>> b'END:VCALENDAR\r\n' match = repattern.search(list[num-1])
- 対応 : byte型をstr型に変換してから比較する
pattern = r"DTSTART;VALUE=DATE:" # DTSTART;VALUE=DATE:yyyyMMddの行の正規表現 repattern = re.compile(pattern) match = repattern.search(list[num-1].decode('utf-8')) #<<< 変換してから比較する
GMTとUTCとJSTとUNIX時間とPythonの狭間を泳ぐ
- 時間の種類が覚えられません。
- GMTは、ロンドン郊外にあるグリニッジ天文台での時間です。
- UTCは、GMTをちょっぴり調整した世界の標準時間です。
- JSTは、UTCより9時間進んでる日本での時間です。
- UNIX時間は、OSなどで使われるUTCでの1970-01-01 00:00:00からの経過秒数です。
- いろんな時間があるからPythonで変換もしてみました。
時間の種類が覚えられません。
GMTとUTCとJST・・・どれがなにか覚えられないので記録しておきます。
| 時間の種類 | 概要 | 現在時間 | UTCへ変換 | JSTへ変換 | UNIX時間 へ変換 |
|---|---|---|---|---|---|
| GMT | グリニッジ天文台 での時間 |
- | - | - | - |
| UTC | GMTをちょっぴり 調整した時間 |
datetime. datetime.now (timezone.utc) |
- | utc_time. astimezone (timezone(timedelta (hours=+9))) |
utc_time. timestamp() |
| JST | 日本の時間 | datetime. datetime.now() |
jst_time.astimezone (timezone.utc) |
- | jst_time. timestamp() |
| UNIX 時間 |
コンピュータ用の時間 | int(time.time()) | datetime.fromtimestamp (unix_time, timezone.utc) |
datetime. fromtimestamp (unix_time) |
- |

UTCは、GMTをちょっぴり調整した世界の標準時間です。
- 日本語 : 協定世界時
- 英語 : Universal Time, Coordinated(調整された)
地球の自転速度の変動でちょっとずつ時間がずれるのでうるう秒で調整しています。
Pythonで現在時間のUTCを取得してみました。
>>> from datetime import datetime, timezone, timedelta # datetime.utcnow()よりdatetime.now(timezone.utc)を使うようにしたほうが良いそうです。 >>> utc_time = datetime.utcnow() >>> print(utc_time) 2020-02-13 13:01:52.177821 >>> utc_time = datetime.now(timezone.utc) >>> print(utc_time) 2020-02-13 13:02:08.306656+00:00
classmethod datetime.utcnow()
tzinfo が None である現在の UTC の日付および時刻を返します。このメソッドは now() と似ていますが、 naive な datetime オブジェクトとして現在の UTC 日付および時刻を返します。 aware な現在の UTC datetime は datetime.now(timezone.utc) を呼び出すことで取得できます。
警告 naive な datetime オブジェクトは多くの datetime メソッドでローカルな時間として扱われるため、 aware な datetime を使って UTC の時刻を表すのが好ましいです。 そのため、 UTC での現在の時刻を表すオブジェクトの作成では datetime.now(timezone.utc) を呼び出す方法が推奨されます。
datetime --- 基本的な日付型および時間型 — Python 3.8.2rc1 ドキュメント
JSTは、UTCより9時間進んでる日本での時間です。
- 日本語 : 日本標準時
- 英語 : Japan Standard Time
Pythonで現在時間のJSTを取得してみました。
>>> from datetime import datetime, timezone, timedelta >>> jst_time = datetime.now() >>> print(jst_time) 2020-02-13 22:01:39.673451
classmethod datetime.now(tz=None)
現在のローカルな日時を返します。オプションの引数 tz が None であるか指定されていない場合、このメソッドは today() と同様ですが、可能ならば time.time() タイムスタンプを通じて得ることができる、より高い精度で時刻を提供します (例えば、プラットフォームが C 関数 gettimeofday() をサポートする場合には可能なことがあります)。
tz が None でない場合、 tz は tzinfo のサブクラスのインスタンスでなければならず、現在の日付および時刻は tz のタイムゾーンに変換されます。
datetime --- 基本的な日付型および時間型 — Python 3.8.2rc1 ドキュメント
UNIX時間は、OSなどで使われるUTCでの1970-01-01 00:00:00からの経過秒数です。
Pythonで現在時間のUTCを取得してみました。
>>> import time from time >>> unix_time = int(time()) >>> print(unix_time) 1581601932
time.time() → float
エポック からの秒数を浮動小数点数で返します。 エポックの具体的な日付とうるう秒 (leap seconds) の扱いはプラットフォーム依存です。 Windows とほとんどの Unix システムでは、エポックは (UTC で) 1970 年 1 月 1 日 0 時 0 分 0 秒で、うるう秒はエポック秒の時間の勘定には入りません。 これは一般に Unix 時間 と呼ばれています。 与えられたプラットフォームでエポックが何なのかを知るには、 time.gmtime(0) の値を見てください。
time --- 時刻データへのアクセスと変換 — Python 3.8.2rc1 ドキュメント
いろんな時間があるからPythonで変換もしてみました。
UTCからJSTへ変換してみました。
>>> from datetime import datetime, timezone, timedelta >>> utc_time = datetime.now(timezone.utc) # UTCからJSTへ変換してみました。 >>> jst_time = utc_time.astimezone(timezone(timedelta(hours=+9))) >>> print(utc_time) 2020-02-13 14:05:37.511844+00:00 >>> print(jst_time) 2020-02-13 23:05:37.511844+09:00
timedelta オブジェクト
timedelta オブジェクトは経過時間、すなわち二つの日付や時刻間の差を表します。class datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
全ての引数がオプションで、デフォルト値は 0 です。 引数は整数、浮動小数点数でもよく、正でも負でもかまいません。
datetime --- 基本的な日付型および時間型 — Python 3.8.2rc1 ドキュメント
UTCからUNIX時間へ変換してみました。
>>> from datetime import datetime, timezone >>> utc_time = datetime.now(timezone.utc) # UTCからUNIX時間へ変換してみました。 >>> unix_time = utc_time.timestamp() >>> print(utc_time) 2020-02-13 22:10:53.173734+00:00 >>> print(unix_time) 1581631853.173734
datetime.timestamp()
datetime インスタンスに対応する POSIX タイムスタンプを返します。 返り値は time.time() で返される値に近い float です。このメソッドでは naive な datetime インスタンスはローカル時刻とし、プラットフォームの C 関数 mktime() に頼って変換を行います。 datetime は多くのプラットフォームの mktime() より広い範囲の値をサポートしているので、遥か過去の時刻や遥か未来の時刻に対し、このメソッドは OverflowError を送出するかもしれません。
datetime --- 基本的な日付型および時間型 — Python 3.8.2rc1 ドキュメント
JSTからUTCへ変換してみました。
>>> from datetime import datetime, timezone, timedelta >>> jst_time = datetime.now() # JSTからUTCへ変換してみました。 >>> utc_time = jst_time.astimezone(timezone.utc) >>> print(jst_time) 2020-02-13 22:59:58.017838 >>> print(utc_time) 2020-02-13 13:59:58.017838+00:00
datetime.astimezone(tz=None)
tz を新たに tzinfo 属性 として持つ datetime オブジェクトを返します。 日付および時刻データを調整して、返り値が self と同じ UTC 時刻を持ち、 tz におけるローカルな時刻を表すようにします。もし与えられた場合、 tz は tzinfo のサブクラスのインスタンスでなければならず、 インスタンスの utcoffset() および dst() メソッドは None を返してはなりません。もし self が naive ならば、おそらくシステムのタイムゾーンで時間を表現します。
datetime --- 基本的な日付型および時間型 — Python 3.8.2rc1 ドキュメント
JSTからUNIX時間へ変換してみました。
>>> from datetime import datetime, timezone >>> jst_time = datetime.now() # JSTからUNIX時間へ変換してみました。 >>> unix_time = jst_time.timestamp() >>> print(jst_time) 2020-02-14 07:15:27.515381 >>> print(unix_time) 1581632127.515381
UNIX時間からUTCへ変換してみました。
>>> from datetime import datetime, timezone >>> from time import time >>> unix_time = int(time()) # UNIX時間からUTCへ変換してみました。 >>> utc_time = datetime.fromtimestamp(unix_time, timezone.utc) >>> print(unix_time) 1581603619 >>> print(utc_time) 2020-02-13 14:20:19+00:00
class datetime.timezone(offset, name=None)
ローカル時刻と UTC の差分を表す timedelta オブジェクトを offset 引数に指定しなくてはいけません。これは -timedelta(hours=24) から timedelta(hours=24) までの両端を含まない範囲に収まっていなくてはなりません。そうでない場合 ValueError が送出されます。timezone.utc
UTC タイムゾーン timezone(timedelta(0)) です。
datetime --- 基本的な日付型および時間型 — Python 3.8.2rc1 ドキュメント
UNIX時間からJSTへ変換してみました。
>>> from datetime import datetime >>> from time import time >>> unix_time = int(time()) # UNIX時間からJSTへ変換してみました。 >>> jst_time = datetime.fromtimestamp(unix_time) >>> print(unix_time) 1581603238 >>> print(jst_time) 2020-02-13 23:13:58
classmethod datetime.fromtimestamp(timestamp, tz=None)
time.time() が返すような、 POSIX タイムスタンプに対応するローカルな日付と時刻を返します。オプションの引数 tz が None であるか、指定されていない場合、タイムスタンプはプラットフォームのローカルな日付および時刻に変換され、返される datetime オブジェクトは naive なものになります。
datetime --- 基本的な日付型および時間型 — Python 3.8.2rc1 ドキュメント

基本に立ち戻ってUMLのクラス図を学ぶ
- 前回の勉強内容
- 勉強のきっかけになった状況
- クラス図は、クラス同士の関係性を中心とした静的な構図を表します。
- クラスは、「操作」「属性」「ロール名」で構成されます。
- クラス同士の関係は、「汎化」「集約」「関連」などのクラスとクラスを結ぶ矢印的な線で表します。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった状況
同僚と実装方針を話していてクラスの関係図をホワイトボードに書いたら、わかりにくくて正されました。
試験問題ができれば、理解できることになるわけではないですが基本を勉強します。
次のクラス図におけるクラス間の関係の説明のうち,適切なものはどれか。
- "バス","トラック"などのクラスが"自動車"クラスの定義を引き継ぐことを,インスタンスという。
- "バス","トラック"などのクラスの共通部分を抽出し"自動車"クラスとして定義することを,汎化という。
- "バス","トラック"などのクラスは,"自動車"クラスに対するオブジェクトという。
- "バス","トラック"などのそれぞれのクラスの違いを"自動車"クラスとして定義することを,特化という。
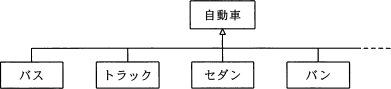
クラス図は、クラス同士の関係性を中心とした静的な構図を表します。
クラスとオブジェクトは、「わく組み」と 「その実体」の関係にあります。
全てのオブジェクトは、必ず何かのクラス定義のもとに生成され、クラスなしではオブジェクトは生成できません。UMLにおいて一般的に、オブジェクトはクラスのインスタンスであると言われるのは、クラスという一定の型に基づいて、実際のオブジェクトが生じるためです。
改訂新版 基礎UML UML 2対応 - インプレスブックス
問題領域やシステムの構造を見るために使われます。
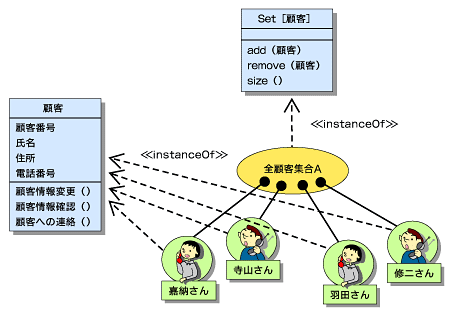
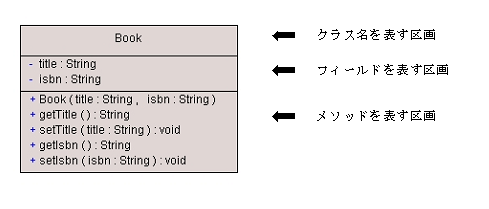
クラスは、「操作」「属性」「ロール名」で構成されます。
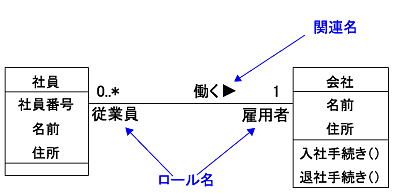
ロール名は、関連におけるそれぞれのオブジェクトの役割(ロール)を示すものです。例えば、社員から見て、会社は雇用者という役割を持っています。一方、会社から見て、社員には従業員という役割があります。
クラス図の詳細化とその目的:初歩のUML(2) - @IT
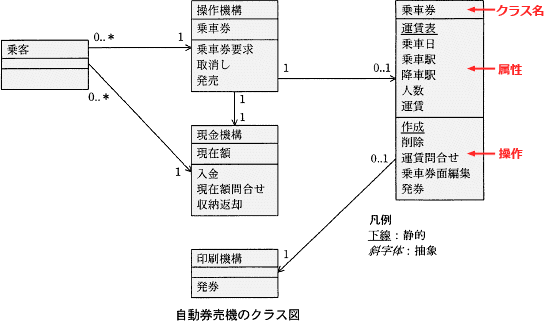
クラス図は、クラスの仕様を決定する重要なモデルです。
クラス同士の関係は、「汎化」「集約」「関連」などのクラスとクラスを結ぶ矢印的な線で表します。
UMLのクラス図が表す内容はどれか。
- クラス間の動的な関係
- クラス同士が,必ず1対1に対応するような相互関係
- クラスを構成するクラス名,インスタンス,メッセージの3要素
- 汎化,集約,関連などのクラス間の関係
関連を持つクラス間のオブジェクトの数の対応関係は、多重度で表します。
一方のクラスのオブジェクトが、もう一方のクラスのいくつのオブジェクトと関係するかなど関連するクラス間の数量的な関係を示します。
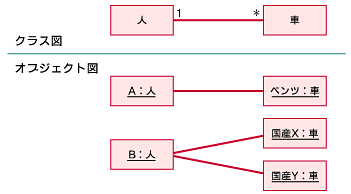
関係性を表す図法があります。

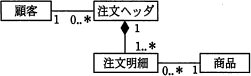
図は"顧客が商品を注文する"を表現したUMLのクラス図である。"顧客が複数の商品をまとめて注文する"を表現したクラス図はどれか。ここで,"注文明細"は一つの注文に含まれる1種類の商品に対応し,"注文ヘッダ"は複数の"注文明細"を束ねた一つの注文に対応する。
答.
平成23年特別問45 UML クラス図|応用情報技術者試験.com


次回の勉強内容
勉強中・・・