AWSのEBSボリュームにタグをつけるLambdaを作った記録
EBSボリュームは管理しないと無駄にお金がかかります。
何気なくEC2を作るとEBSボリュームが作られます(既存のボリュームを使った場合を除く)。
EC2を削除(終了)してもEBSボリュームはデフォルトで削除されません。
結果、気が付いたら使ってないEBSボリュームが残っていることがあります。
aws.amazon.com
EC2インスタンスを削除するときはEBSボリュームも削除します。

それでもアタッチされていないEBSボリュームが残ることはあります。
複数人で長期間使っていればうっかりアタッチされていないEBSボリュームが残ることはあります。
とはいえ、本当にアタッチされていなければ削除していいのか?誰かが何かの目的で残しているのかも?
となった時に何に使われていたがわかる情報があると助かります。
やりたいこと
前提 : EC2にはNameタグをつけておきます。
EC2インスタンスには、Nameというタグをつけてインスタンスを使っているプロジェクトやサーバの情報をValueに入れておきます。
例えば、ponsukeプロジェクトのMySQLデータベースサーバにしているインスタンスなら「ponsuke-MySQL」をNameタグのValueに入れておく、みたいな。
Lambdaを作る記録
Lambdaの実行権限を作成します。
IAMのポリシーを作成します。
- AWSマネジメントコンソールにある[IAM] > サイドメニューの[ポリシー] > [ポリシーの作成]ボタンで作成画面を開きます。

[ポリシーの作成]ボタンで作成画面を開きます。
- [JSON]タブを開いて下にある内容を入力します。

[JSON]タブ
- [ポリシーの確認]ボタンで確認画面へ遷移して[名前(必須)]と[説明(任意)]を入力します。
- [ポリシーの作成]ボタンでポリシーを作成して一覧画面に戻ります。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances",
"ec2:CreateTags",
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
IAMのロールを作成します。
- AWSマネジメントコンソールにある[IAM] > サイドメニューの[ロール] > [ロールの作成]ボタンで作成画面を開きます。

[ロールの作成]ボタンで作成画面を開きます。
- [AWSサービス] > [Lambda]を選択後に[次のステップ: アクセス権限]ボタンで次の画面を開きます。
- [Attach アクセス権限ポリシー]の[ポリシーのフィルタ]で作成したポリシーを検索して選択後に[次のステップ: タグ]ボタンで次の画面を開きます。
- [タグの追加 (オプション)]は任意なので設定せずに[次のステップ: 確認]ボタンで確認画面を開きます。
- [ロール名]を入力して[ロールの作成]ボタンでロールを作成して一覧画面に戻ります。
Lambda関数を作成します。
- AWSのコンソールにある[Lambda] > [関数の作成]ボタンで画面を開きます。

[関数の作成]ボタンで画面を開きます。
- 必要な項目を入力後に[関数の作成]ボタンで関数を作成します。
- オプション : [一から作成]
- 関数名 : attatch_name_tag_for_ebs_volume(任意の関数名でOK)
- ランタイム : Python3.8
- 実行ロール : 既存のロールを使用する
- 既存のロール : 作成したロールを選択します。
Lambda関数を実行するトリガーを作成します。
- [Designer]にある[トリガーを追加]ボタンでトリガーの設定画面を開きます。

[Designer]にある[トリガーを追加]ボタン
- プルダウンから[CloudWatch Events]を選択します。
- 各入力欄を記載します
- ルール : [新規ルールの作成]
- ルール名(必須) : attatch_name_tag_for_ebs_volume(任意の関数名でOK)
- ルールタイプ : [スケジュール式]
- スケジュール式の書き方を参考にLambda関数を実行する予定を入力します。

- [追加]ボタンでトリガーを作成します。

関数の内容を実装します。
- EBSボリュームを取得するdescribe_volumes()の使い方
- EC2インスタンスを取得するdescribe_instances()の使い方
- EBSボリュームにタグをつけるcreate_tags()の使い方
import boto3 ec2 = boto3.client('ec2') print('Loading function') def get_name_tag_value(tags): """ タグリストからNameタグの値を取得する. Parameters ---------- tags 辞書形式のタグリスト """ name_tag_value = '' for tag in tags: if tag['Key'] == 'Name': name_tag_value = tag['Value'] break return name_tag_value def get_volumes_no_name_tag_and_attached(): """ [アタッチされていて][Nameタグが設定されていない]EBSボリュームを取得する. """ volumes = ec2.describe_volumes( Filters=[ { 'Name': 'attachment.status', 'Values': ['attached'] } ] )['Volumes'] volumes_no_name_tag = [] for volume in volumes: if 'Tags' not in volume: # タグが設定されていない場合:Nameタグのないボリュームとする volumes_no_name_tag.append(volume) else: # タグが設定されている場合 name_tag_value = get_name_tag_value(volume['Tags']) if name_tag_value == '': # Nameタグの値を取得できない場合:Nameタグのないボリュームとする volumes_no_name_tag.append(volume) return volumes_no_name_tag def get_ec2_instance_name_tag_value(volume): """ EBSボリュームにアタッチされているEC2インスタンスに設定されているNameタグの値を取得する. Parameters ---------- volume 対象となるEBSボリューム """ # アタッチされているEC2インスタンスのIDを取得する instance_id = volume['Attachments'][0]['InstanceId'] # EC2インスタンスのIDからインスタンスに設定されているタグ群を取得する tags = ec2.describe_instances( Filters=[ { 'Name': 'instance-id', 'Values': [instance_id] } ] )['Reservations'][0]['Instances'][0]['Tags'] # EC2インスタンスについているNameタグの値を取得する name_tag_value = get_name_tag_value(tags) return name_tag_value def set_name_tag_for_volume(volume_id, name_tag_value): """ EBSボリュームにNameタグを設定する. Parameters ---------- volume_id NameタグをつけるEBSボリュームID name_tag_value EC2インスタンスについているNameタグの値 """ response = ec2.create_tags( Resources=[volume_id], Tags=[{'Key': 'Name', 'Value': name_tag_value}] ) return 0 def lambda_handler(event, context): volumes = get_volumes_no_name_tag_and_attached() for volume in volumes: # EBSボリュームのIDを取得する. volume_id = volume['VolumeId'] print(str(volume_id) + 'にはNameタグが付いていません') name_tag_value = get_ec2_instance_name_tag_value(volume) # EC2インスタンスにNameタグが設定されている場合に処理を実行する. if name_tag_value != '': set_name_tag_for_volume(volume_id, name_tag_value) print(str(volume_id) + 'のNameタグに「' + name_tag_value + '」とつけました') return 0
失敗したこと
describe_volumes()の実行権限がIAMロールになかった
[ERROR] ClientError: An error occurred (UnauthorizedOperation) when calling the DescribeVolumes operation: You are not authorized to perform this operation.
- 事象 : describe_volumes()を実行したらエラーになった
- 原因 : describe_volumes()を実行する権限がないから
- エラーの時のIAMロールの権限設定 > 「ec2:DescribeInstances」しかない
...省略...
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances",
"ec2:CreateTags",
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
...省略...
- 対応 : 「ec2:DescribeVolumes」を権限設定に追加する
...省略...
"Effect": "Allow",
"Action": [
"ec2:DescribeVolumes", <<< 追加
"ec2:DescribeInstances",
"ec2:CreateTags",
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
...省略...
describe_volumesの引数の型が不正だった
[ERROR] ParamValidationError: Parameter validation failed: Invalid type for parameter Filters[0].Values, value: Name, type: <class 'str'>, valid types: <class 'list'>, <class 'tuple'>
- 事象 : Filtersに指定したValuesに文字(str)を指定して実行したらエラーになった
# Nameタグが設定されていないEBSボリュームを取得する response = ec2.describe_volumes( Filters=[ { 'Name': 'tag:Name', 'Values': '' } ] )['Volumes']
- 原因 : Valuesにlistかtupleのシーケンス型を使っていないから
- [ドキュメントにもValues (list) と書いてあります。]
- 対応 : Valuesをlistで指定する
{
'Name': 'tag:Name',
'Values': [''] <<<<<<<<<< 修正
}
Oracle Databaseにユーザー(スキーマ)を作った記録
- RDSでOracleを作成したのでユーザーを作成します。
- SQL*PlusでDBにログインします。
- ユーザーに設定する情報を確認します。
- ユーザーを作成します。
- 作成したユーザーでログインしてみます。
- 失敗したこと
- 環境
RDSでOracleを作成したのでユーザーを作成します。
SQL*PlusでDBにログインします。
管理者ユーザーでログインします。
$ sqlplus admin/hoge@oracle-12.fuga.us-east-2.rds.amazonaws.com:1521/PONDB SQL*Plus: Release 12.2.0.1.0 Production on 火 3月 10 13:57:46 2020 Copyright (c) 1982, 2016, Oracle. All rights reserved. 最終正常ログイン時間: 火 3月 10 2020 13:45:58 +00:00 Oracle Database 12c Standard Edition Release 12.2.0.1.0 - 64bit Production に接続されました。 SQL>
表示幅が狭いと見ずらいので広げます。
SQL> show linesize linesize 80 SQL> set linesize 120
ユーザーに設定する情報を確認します。
ユーザーを作成する構文
CREATE USER my_name
IDENTIFIED BY "my_password"
[DEFAULT TABLESPACE my_tablespace]
[TEMPORARY TABLESPACE my_temp_tablespace]
[PROFILE my_profile]
CREATE USER、ユーザーの作成 - オラクル・Oracleをマスターするための基本と仕組み
作りたいユーザー名が既にないことを確認します。
SQL> select distinct username from all_users where username like '%ponsuke%'; レコードが選択されませんでした。
注意 : キャメルケースでユーザー名を指定すると大文字小文字が区別されないのでダサいことになります。
キャメルケースで書くと大文字小文字が区別されず、全部大文字か全部小文字(表示するツールによるらしい)になります。
「_」などで区切るスネークケースがよいです。
ダサいのを誤って作ってしまったので削除しました。
/* 所有していたオブジェクトもろともユーザーを削除する */ SQL> drop user PONSUKETAROU cascade;
使用する表領域を選びます。
「DEFAULT TABLESPACE(ユーザー・オブジェクト を作成するときの使用するデフォルト表領域)」「TEMPORARY TABLESPACE(Oracle が使用する作業用の表領域)」で指定する値を選びます。
現在存在する表領域を検索して選びます。
SQL> select tablespace_name,block_size,initial_extent from dba_tablespaces; TABLESPACE_NAME BLOCK_SIZE INITIAL_EXTENT --------------- ---------- -------------- SYSTEM 8192 65536 SYSAUX 8192 65536 UNDO_T1 8192 65536 TEMP 8192 1048576 USERS 8192 65536 RDSADMIN 8192 65536 6行が選択されました。
ユーザーを作成します。
SQL> create user ponsuke identified by ponsuke default tablespace USERS temporary tablespace TEMP profile DEFAULT; ユーザーが作成されました。 -- 確認します。 SQL> select username from all_users where regexp_like(username, 'ponsuke', 'i'); USERNAME ------------------------------------------------------------------------------------------------------------------------ PONSUKE SQL>
権限を付与します。
権限を付与しないとデータベースに接続すらできません。
SQL> grant create session,create table,create view,create sequence,create trigger,create synonym,unlimited tablespace to ponsuke; 権限付与が成功しました。
作成したユーザーでログインしてみます。
$ sqlplus ponsuke/ponsuke@oracle-12.fuga.us-east-2.rds.amazonaws.com:1521/PONDB SQL*Plus: Release 12.2.0.1.0 Production on 火 3月 10 14:32:13 2020 Copyright (c) 1982, 2016, Oracle. All rights reserved. Oracle Database 12c Standard Edition Release 12.2.0.1.0 - 64bit Production に接続されました。 SQL>

AWSのRDSの証明書を更新した記録
5年ごとに証明書を更新する必要があります。
、RDS DB インスタンスと Aurora DB クラスターの SSL/TLS 証明書は有効期限が切れ、5 年ごとに置き換えられます。現在の証明書は、2020 年 3 月 5 日に期限切れになります。 クライアントとデータベースサーバーの両方で SSL/TLS 証明書を更新しない場合、証明書を検証して SSL/TLS により RDS DB インスタンスまたは Aurora クラスターに接続するデータベースクライアントとアプリケーションは、2020 年 3 月 5 日から接続できなくなります。
Amazon RDS のお客様: 2020 年 2 月 5 日までに SSL/TLS 証明書を更新してください | Amazon Web Services ブログ
実際にやった人の手順を参考に実施します。
今の証明書を確認します。
- コンソール > [RDS] > [データベース] > 対象のRDSのリンクから詳細画面を表示 > [接続とセキュリティ] > [認証機関]
- 認証機関 : rds-ca-2015
- 証明機関の日付 : Mar 6th, 2020
認証機関をrds-ca-2019へ更新します。


確認します。
- コンソール > [RDS] > [データベース] > 対象のRDSのリンクから詳細画面を表示 > [接続とセキュリティ] > [認証機関]
- 認証機関 : rds-ca-2019
- 証明機関の日付 : Aug 23rd, 2024
- DBクライアントツールから接続できることを確認します。
- 開発アプリケーションから接続できることを確認します。
- SQL*PLUSでも接続を確認します。
$ sqlplus {ユーザ名}/{パスワード}@hoge.fuge.ap-northeast-1.rds.amazonaws.com:1521/{サービス名} SQL*Plus: Release 12.2.0.1.0 Production on 木 1月 30 10:25:04 2020 Copyright (c) 1982, 2017, Oracle. All rights reserved. 最終正常ログイン時間: 火 1月 28 2020 10:19:05 +09:00 Oracle Database 12c Standard Edition Release 12.2.0.1.0 - 64bit Production に接続されました。 SQL>
医療情報倫理
- 医療業界に関わるエンジニアへの一歩目
- 個人情報とプライバシー
- 医療情報システムの利用者の責任
- 医療情報システムの担当者の責務
- 医療の情報化と患者の医療参画
- 医学・保健医療の研究倫理とポピュレーション・ヘルス
- 医療情報倫理
- 医療情報担当職の倫理網領
- 医療情報化の担い手として
医療業界に関わるエンジニアへの一歩目
医療業界に関わるお仕事をするエンジニアとして「医療情報技師」という資格の「医療情報システム」という分野を勉強してみます。
まずは、情報を取り扱うものとしての基本となる医療情報倫理です。
個人情報とプライバシー
医療の世界では、氏名や住所だけではなく生体情報という他人が容易には知り得ないような情報を取り扱います。
そんな医療の世界で働く人に向けて、厚生労働省からは医療・介護関係事業者における個人情報の適切な取扱いのためのガイダンスが出ています。
医療の世界に関わる人と言ってもお医者さんから介護士・研究者といろんな立場があるので、ガイダンスには以下のようなことが記載されています。
- 医療・介護関係事業者が行う措置の透明性の確保と対外的明確化
- 責任体制の明確化と患者・利用者窓口の設置等
- 遺族への診療情報の提供の取扱い
- 個人情報が研究に活用される場合の取扱い
- 遺伝情報を診療に活用する場合の取扱い
“医療情報システム向け「Amazon Web Services」利用リファレンス”の公開:APN パートナー各社 | Amazon Web Services ブログ

「個人情報」と「プライバシー」のびみょーーーな違い
「個人情報保護」と「プライバシー保護」は同じ意味に思えます。
しかし、医療情報技師の教科書では「個人情報」と「プライバシー」の違いを説明しています。
「プライバシーに関わる情報」とは、
個人の私生活上の事実に関する情報であり、「本人がその情報を開示しないで欲しいであろうと考えられる情報」である。
これに対し
「個人情報」は、
「特定の個人を識別できる情報」であり、私生活に関する情報か否か、開示しないで欲しいと考えられる情報か否かは問わない。
医療情報第5版医療情報システム編
医療情報システムの利用者の責任
医療に関わるシステムは、限られた人がエルタンできるようなものが多いように思います。
電子カルテや薬剤情報・検査機器を扱うシステムから研究や治験の情報を蓄積するシステムまで、誰でも彼でも閲覧できるものはではありません。
それは、先に紹介した「個人情報」「プライバシー」を取り扱うからです。
不適切な閲覧によるプライバシーの侵害をしないようにします。
システムを閲覧できる権限があるひとには「個人情報」「プライバシー」を守る義務が生じます。
そのために、利用者一人ひとりの意識が重要です。
故意及び重過失をもって、これらの要件に反する行為を行えば刑法上の秘密漏示罪で犯罪として処罰される場合があるが、診療情報等については過失による漏えいや目的外利用
も同様に大きな問題となり得る。
医療情報システムの安全管理に関するガイドライン
プライバシー権利を保証するための情報セキュリティ上の義務があります。
- 自身の認証番号やパスワードを管理し、これを他人に利用させない。
- 電子保存システムの情報の参照や入力に際して、認証番号やパスワードなどによってシステムに自身を認識させる。
- 電子保存システムへの入力に際して、確定操作(入力情報が正しいことを確認する操作)を行って、入力情報に対する責任を明示する。
- 代行入力の場合は、入力権限を持つ者が最終的に確定操作を行い、入力情報に対する責任を明示する。
- 作業終了あるいは離席する際は、必ずログアウト操作を行う。
ちょっとしたセキュリティ意識の弱さから漏洩事件が発生しています。
医療情報システムの担当者の責務
医療システムの責任者・担当者に対する指針として厚生労働省から医療情報システムの安全管理に関するガイドラインが出ています。
医療・介護関係事業者における個人情報の適切な取扱いのためのガイダンスでは、「医療情報システムの導入及びそれに伴う情報の外部保存を行う場合の取扱い」についてはこのガイダンスに従うことが記載されています。
医療の情報化と患者の医療参画
ここ数十年で医療へのコンピュータ導入の目的は、「業務の合理化」>「診療支援」>「患者中心の視点」へと視点の主役が変わってきているそうです。
電子カルテでは、
- 医療者 : 患者へ説明しやすく
- 患者 : カルテへの敷居が低くなる
と、「患者中心の医療」への取り組みにコンピュータ導入が寄与することとなる。
電子カルテを導入するメリット・デメリット | 導入するメリット・デメリット | 電子カルテサービス | SECOM セコム医療システム株式会社
医学・保健医療の研究倫理とポピュレーション・ヘルス
医療システムが導入されていくことで治療へつながる研究や症例の蓄積などへ医療情報の活用が活発になっていきます。
医療情報倫理
医療情報担当職の倫理網領
医療情報化の担い手として
AWSのRDSのバックアップをインスタンスに復元する記録
Amazon RDSはインスタンスの自動バックアップをしてくれます。
Amazon RDS は、DB インスタンスの自動バックアップを作成および保存します。Amazon RDS は、DB インスタンスのストレージボリュームのスナップショットを作成し、個々のデータベースだけではなく、その DB インスタンス全体をバックアップします。
バックアップの使用
自動化バックアップによってDB スナップショットができます。
サイドメニューに[スナップショット]と[Automated backups]の2つがあるので何が違うんだろう?と思いました。

[よくある質問]を読むと「自動化バックアップ機能によってスナップショットができる。」「スナップショットは自動化バックアップ機能を使わなくても作れる。」そうです。
バックアップを復元したければスナップショットを復元すればいいんですね。
Q: 自動化バックアップと DB スナップショットの違いは何ですか?
Amazon RDS は、DB インスタンスのバックアップと復元を行うための 2 つの方法を提供しています。自動バックアップとデータベーススナップショット (DB スナップショット) です。
よくある質問 - Amazon RDS | AWS
スナップショットを復元します。

失敗したこと
The option group hoge is associated with a different VPC than the request.
- 事象 : [DBインスタンスの復元]ボタンを押下したところ以下のメッセージが表示されて復元できない。
The option group hoge is associated with a different VPC than the request. (Service: AmazonRDS; Status Code: 400; Error Code: InvalidParameterCombination; Request ID: 74xxxxx)
- 原因 : [アベイラビリティーゾーン]を選択していないから
- スナップショットの元になったインスタンスの設定になっているのかと思い込んでみていませんでした。
- [オプション・グループ]を設定していると別のVPCに復元するのは大変なことです。
- 参考 : Amazon Web Services (AWS) ドキュメントのオプショングループに関する考慮事項
- スナップショットの元になったインスタンスの設定になっているのかと思い込んでみていませんでした。
- 対応 : [アベイラビリティーゾーン]を選択する
AWSのRDSを自動停止するLambdaを作る記録
- RDSは停止しても7日経つと自動で起動してしまいます。
- このサイトのやり方でRDSを自動停止するLambdaを作る
- 実行権限を作成する
- 自動停止の対象と停止時間を設定できるようにするためにRDSにAutoStopタグを追加します。
- Lambda関数を作成します。
- Lambda関数を実行するトリガーを作成します。
- 失敗したこと
RDSは停止しても7日経つと自動で起動してしまいます。
DB インスタンスは最大 7 日間停止できます。DB インスタンスを手動で起動しないで 7 日間が経過すると、DB インスタンスは自動的に起動します。
一時的に Amazon RDS DB インスタンスを停止する - Amazon Relational Database Service
なので、RDSを監視して自動で停止してほしいです。
案件が動いていない時は停止していてほしいです。ちょいちょい確認して停止するのは面倒くさいです。
そこで、世の中の知識を利用して自動停止できるようにします。
このサイトのやり方でRDSを自動停止するLambdaを作る
実行権限を作成する
Lambdaの実行権限を作成する - ponsuke_tarou’s blog
上記を参考にIAMのポリシーを作成し、ロールを作成します。
ポリシーに設定する内容は以下になります。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "rds:StopDBInstance", "rds:ListTagsForResource" ], "Resource": "arn:aws:rds:*:*:db:*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "logs:CreateLogStream", "rds:DescribeDBInstances", "logs:CreateLogGroup", "logs:PutLogEvents" ], "Resource": "*" } ] }
自動停止の対象と停止時間を設定できるようにするためにRDSにAutoStopタグを追加します。
- AWSマネジメントコンソールにある[RDS] > サイドメニューの[データベース] > 対象となるRDSを選択して詳細画面を開きます。
- [タグ]タブ > [追加]ボタンで[タグの追加] ウィンドウを表示します。
- [タグキー]に「AutoStop」と[値]に「自動停止したい時間」を入力します。
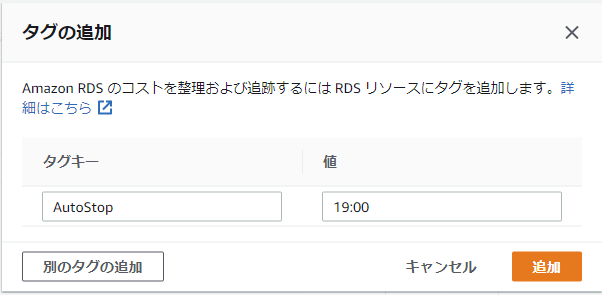
タグの追加ウィンドウ
- [追加]を選択します。
追加後
Lambda関数を作成します。
- AWSのコンソールにある[Lambda] > [関数の作成]ボタンで画面を開きます。
- 必要な項目を入力後に[関数の作成]ボタンで関数を作成します。
- オプション : [一から作成]
- 関数名 : 任意の関数名
- ランタイム : Python3.8
- 実行ロール : 既存のロールを使用する
- 作成したロールを選択します。
関数を実装します。
[関数コード] > [lambda_function.py]に以下のコードを張り付けて[保存]ボタンで保存します。
# -*- coding: utf-8 -*- from __future__ import print_function import sys import json import boto3 import datetime REGION_NAME = "ap-northeast-1" print("Loading function") rds = boto3.client('rds') def get_auto_stop_tag(instance_arn): instance_tags = rds.list_tags_for_resource(ResourceName=instance_arn) tag_list = instance_tags['TagList'] tag = next(iter(filter(lambda tag: tag['Key'] == 'AutoStop' and (tag['Value'] is not None and tag['Value'] != ''), tag_list)), None) return tag def get_auto_stop_time(auto_stop_tag): today = datetime.datetime.now() param_day = today.day auto_stop_val = auto_stop_tag["Value"].split(":") # 設定時刻が8:59以前である場合、GMT変換時に前日にならないよう日付を1日進めておく if int(auto_stop_val[0]) < 9: param_day = param_day + 1 # タグに指定されたGMTでの時間 tag_time = datetime.datetime(today.year, today.month, param_day, int(auto_stop_val[0]), int(auto_stop_val[1])) gmt_time = tag_time + datetime.timedelta(hours=-9) return gmt_time def lambda_handler(event, context): print("Received event: " + json.dumps(event, indent=2)) # インスタンスを取得 instances = rds.describe_db_instances() if len(instances['DBInstances']) > 0: # インスタンスを順番に処理していく for instance in instances['DBInstances']: if instance['DBInstanceStatus'] == 'available': instance_arn = instance['DBInstanceArn'] print(instance_arn + 'は、稼働中です。') tag = get_auto_stop_tag(instance_arn) print('取得したAutoStopタグ:' + str(tag)) if tag: # AutoStopタグが指定されているインスタンスを処理する reference_time = get_auto_stop_time(tag) print('AutoStopタグに指定された時間(GMT)は、' + reference_time.strftime('%Y-%m-%dT%H:%M:%SZ') + 'です。') event_time = datetime.datetime.strptime(event["time"], '%Y-%m-%dT%H:%M:%SZ') reference_time_from = reference_time + datetime.timedelta(minutes=-5) reference_time_to = reference_time + datetime.timedelta(minutes=5) print('処理時間(' + event_time.strftime('%Y-%m-%dT%H:%M:%SZ') + ')が、' + \ reference_time_from.strftime('%Y-%m-%dT%H:%M:%SZ') + 'から' + reference_time_to.strftime('%Y-%m-%dT%H:%M:%SZ') + 'だったら停止します。') # AutoStopタグに指定された時刻の前後5分以内であればインスタンス停止する if reference_time_from <= event_time and event_time <= reference_time_to: rds.stop_db_instance(DBInstanceIdentifier=instance['DBInstanceIdentifier']) print(instance_arn + 'を停止しました。')
実装の参考サイト
AWS Lambda+Python3で複数のRDSを起動停止 | LINKBAL Blog
Lambdaの関数を利用してRDSを長期間停止する - Qiita
DescribeDBInstances - Amazon Relational Database Service
DB instance status - Amazon Relational Database Service
AWS Lambda Pythonをローカル環境で実行 | DevelopersIO
関数を動かしてみます。
- [テスト]ボタンで[テストイベントの設定]ダイアログを表示します。
- [新しいテストイベントの作成]を選択します。
- [イベントテンプレート]で「Hello World」を選択します。
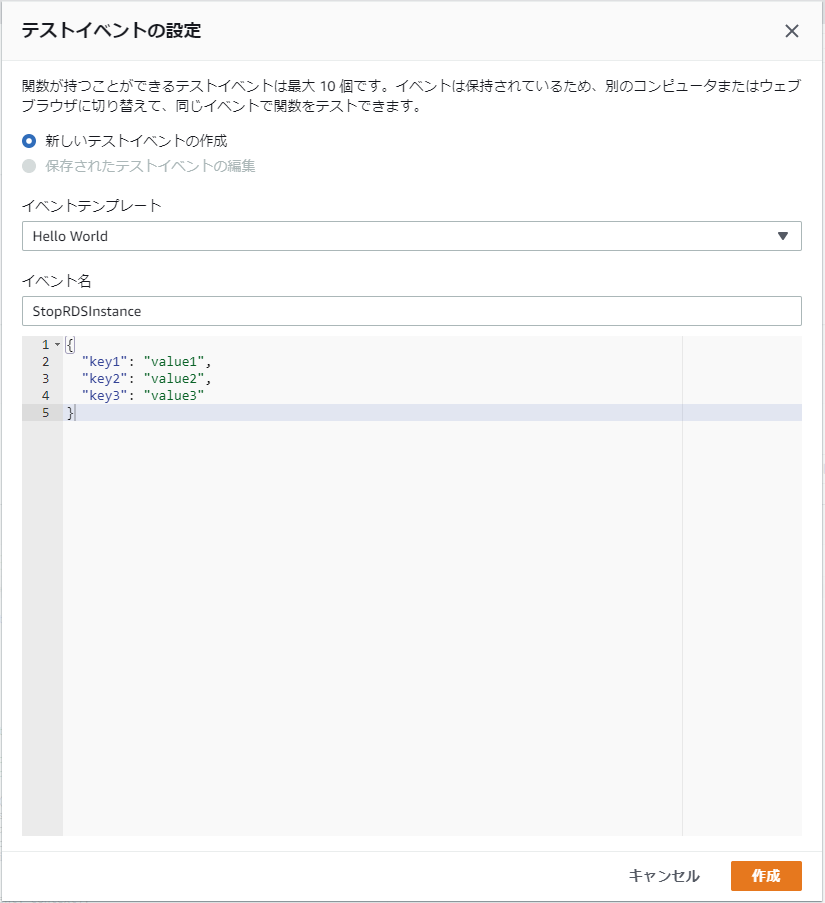
テストイベントの設定
- 引数の欄に「{"time": "2019-12-04T10:02:00Z"}」を入力します(時間はAutoStopタグに指定した時間の近い時間)。
- [イベント名]に任意の名前を設定して[作成]ボタンで保存します。

保存後の状態
- [テスト]ボタンで関数を実行します。
- 実行結果とログを確認して、「成功」になるまでソースや設定の見直しをします。

実行結果
Lambda関数を実行するトリガーを作成します。
CloudWatch EventsをトリガーとしてLambda関数を実行できるようにするためにイベントを登録します。
CloudWatch Eventsにイベントを登録します。
- AWSのコンソールにある[Lambda] > 作成したLambda関数を選択して詳細画面を開きます。
- [Designer]にある[トリガーを追加]ボタンでトリガーの設定画面を開きます。
トリガーを追加ボタン
- プルダウンからCloudWatch Eventsを選択します。
- [ルール]で「新規ルールの作成」を選択し、[ルール名(必須)][ルールの説明(任意)]を入力します。
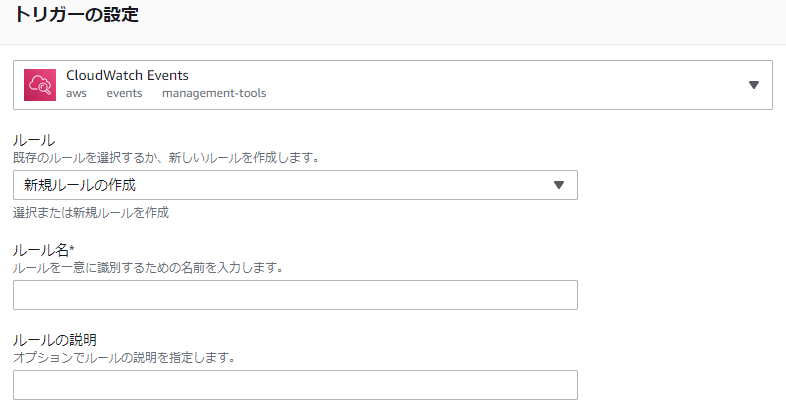
トリガーの設定画面
- [ルールタイプ]で「スケジュール式」を選択し、[スケジュール式]に以下のサイトを参考にスケジュールを設定します。
失敗したこと
CloudWatch Eventsの[スケジュール式]の書き方を間違えた
Cron式で時間に「10-24」と指定したところエラーになりました。24時はだめなんですね。
Parameter ScheduleExpression is not valid. (Service: AmazonCloudWatchEvents; Status Code: 400; Error Code: ValidationException; Request ID: c.....)
Lambda関数でCloudWatch Logsに書き込むための権限がなかった。
Lambda関数を実行するCloudWatch Eventsを登録してからLambda関数の[モニタリング]タブを見てみるとメッセージが表示されていました。
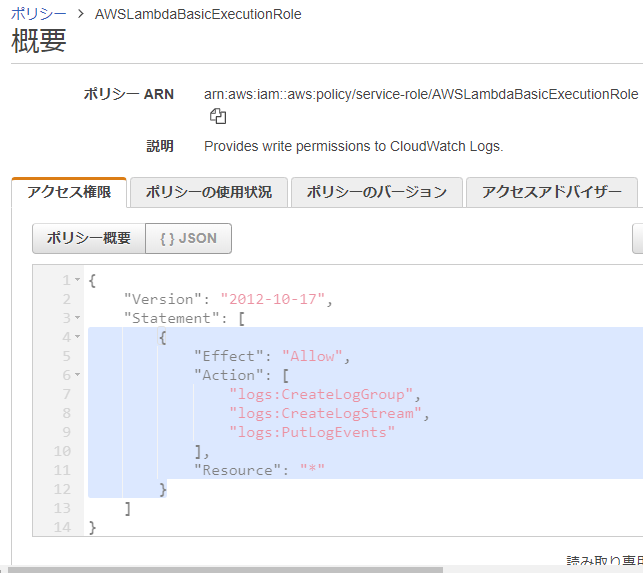
メッセージにある[AWSLambdaBasicExecutionRole]の権限を追加します。
アクセス権限が見つかりません お使いの関数には、Amazon CloudWatch Logs に書き込むためのアクセス許可がありません。ログを閲覧するには、その実行ロールに AWSLambdaBasicExecutionRole の管理ポリシーを追加します。IAM コンソールを開きます。
- AWSマネジメントコンソールにある[IAM] > サイドメニューの[ポリシー] > [AWSLambdaBasicExecutionRole]を検索して詳細画面を表示します。
- [アクセス権] > [JSON]で権限の詳細を表示します。
- [Statement]に記載されている内容以下をコピーします。
- サイドメニューの[ポリシー] > Lambda関数に設定したポリシーを検索して詳細画面を表示します。
- [アクセス権] > [JSON] > [ポリシーの編集]ボタンで編集画面を表示します。
- コピーした内容を[Action]に追記します。
- [ポリシーの確認]ボタン > [変更の保存]ボタンで保存します。
describe_db_instancesを実行する権限がなかった。
Lambda関数を実行したらエラーになりました。ポリシーの[Action]に「rds:DescribeDBInstances」を追加しました。
{
"errorMessage": "An error occurred (AccessDenied) when calling the DescribeDBInstances operation: User: arn:aws:sts::8xxxxxxxxxxx:assumed-role/{ロール名}/{Lambda関数名} is not authorized to perform: rds:DescribeDBInstances",
"errorType": "ClientError",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 27, in lambda_handler\n instances = rds.describe_db_instances(Filters=[{\"Name\": \"DBInstanceStatus\", \"Values\": [\"available\"]}])\n",
" File \"/var/runtime/botocore/client.py\", line 357, in _api_call\n return self._make_api_call(operation_name, kwargs)\n",
" File \"/var/runtime/botocore/client.py\", line 661, in _make_api_call\n raise error_class(parsed_response, operation_name)\n"
]
}
「rds:DescribeDBInstances」はリソースを限定できなかった。
以下のように単純に「rds:DescribeDBInstances」を追加したところ同じエラーになりました。
一部のRDSの情報の閲覧だけできるポリシーは作れなかった話 - Qiitaを読んでリソースを限定できないことを知りました。
...省略...
"Action": [
"rds:StopDBInstance",
"rds:DescribeDBInstances"
],
"Resource": "arn:aws:rds:*:*:db:*"
...省略...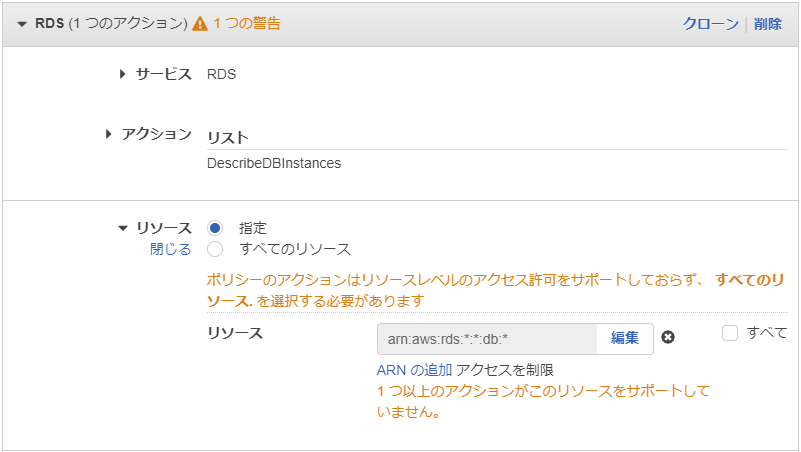
DMZは内部ネットワークを守るための領域です。
- 前回の勉強内容
- 勉強のきっかけになった問題
- DMZは、外部ネットワークと内部ネットワークの間にあるネットワーク上の領域です。
- DMZは、ファイアウォールやルータに隔離された領域です。
- DMZを設置していてもファイアウォールやDMZに設置した機器の正しい対策が行われていなければ、内部ネットワークは危険にさらされます。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
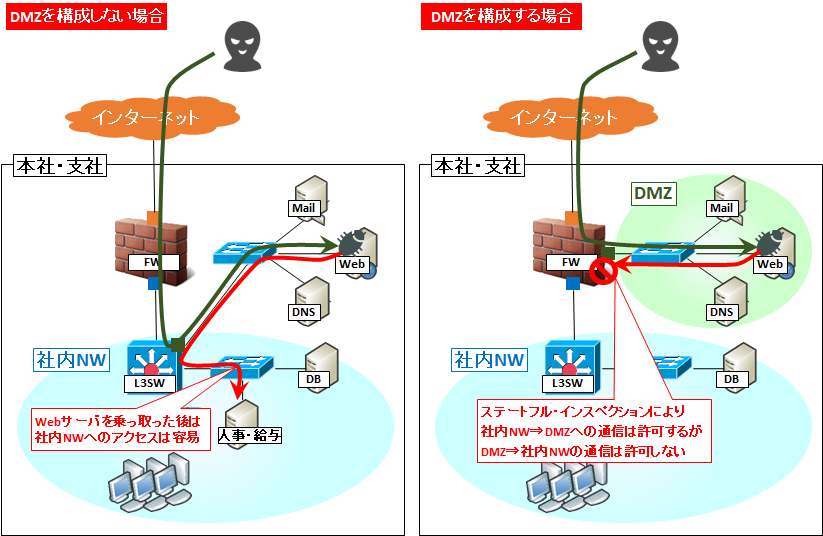
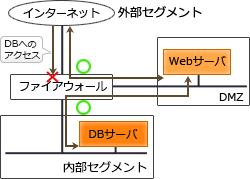
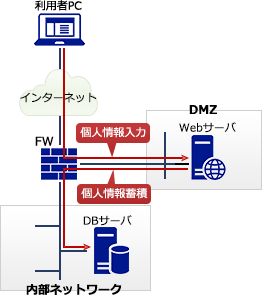
DMZ上に公開しているWebサーバで入力データを受け付け,内部ネットワークのDBサーバにそのデータを蓄積するシステムがある。インターネットからDMZを経由してなされるDBサーバへの不正侵入対策の一つとして,DMZと内部ネットワークとの間にファイアウォールを設置するとき,最も有効な設定はどれか。
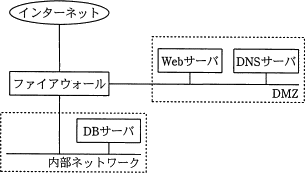

DMZは、外部ネットワークと内部ネットワークの間にあるネットワーク上の領域です。
- 英語: DeMilitarized(離れる + 軍用化する) Zone
- 日本語: 非武装地帯
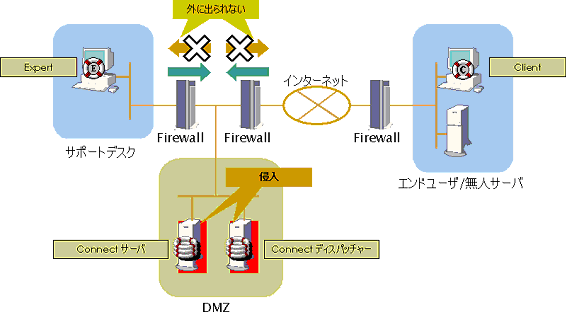
Webサーバなど外部に公開するサーバなどが設置されます。
ステートフル・インスペクションは、出入りするパケットの通信状態を把握して外部から送信されたパケットのアクセスを動的に制御するファイアウォールです。
DMZは、ファイアウォールやルータに隔離された領域です。
パケットフィルタリング型ファイアウォールを設置すると、パケットのヘッダ情報でアクセス制御を行うことができます。
内部ネットワークのDBサーバの受信ポート番号を固定し、WebサーバからDBサーバの受信ポート番号への通信だけをファイアウォールで通します。
「勉強のきっかけになった問題」にある設問の構成では、Webサーバから内部ネットワークへの通信はDBサーバに限れば良いので、DBサーバのポートを固定してファイアウォールへ設定します。これにより、不要な通信を通さずに済みます。
(参考)情報セキュリティスペシャリスト平成22年秋期 午前Ⅱ 問6


DMZを設置していてもファイアウォールやDMZに設置した機器の正しい対策が行われていなければ、内部ネットワークは危険にさらされます。
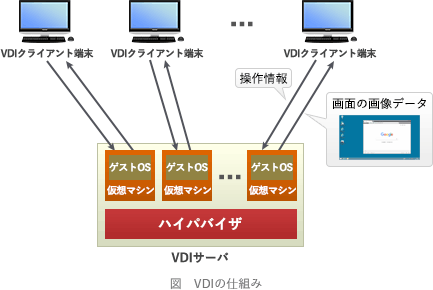
内部ネットワークのPCからインターネット上のWebサイトを参照するときにDMZ上に用意したVDI(Virtual Desktop Infrastructure)サーバ上のWebブラウザを利用すると,未知のマルウェアがPCにダウンロードされて,PCが感染することを防ぐというセキュリティ上の効果が期待できる。この効果を生み出すVDIサーバの動作の特徴はどれか。
答. Webサイトからの受信データを処理してVDIサーバで生成したデスクトップ画面の画像データだけをPCに送信する。
平成30年春期問41 VDIシステムの導入|応用情報技術者試験.com
公開サーバと同じマシンに公開する必要のないサーバを一緒に入れると公開する必要のないサーバは危険にさらされます。
企業のDMZ上で1台のDNSサーバを,インターネット公開用と,社内のPC及びサーバからの名前解決の問合せに対応する社内用とで共用している。このDNSサーバが,DNSキャッシュポイズニングの被害を受けた結果,直接引き起こされ得る現象はどれか。
答. 社内の利用者が,インターネット上の特定のWebサーバにアクセスしようとすると,本来とは異なるWebサーバに誘導される。
平成28年春期問36 DNSキャッシュポイズニング|応用情報技術者試験.com
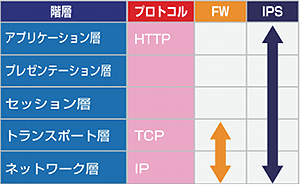
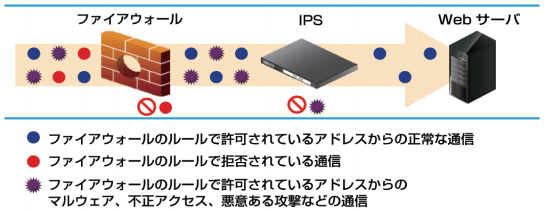
ファイアウォールでは、「不正なアクセスによる攻撃」「Webアプリケーションの脆弱性を利用した攻撃」は防げません。

IDSとIPSを利用することで、ネットワークを監視して危険の連絡・遮断ができます。
WAFは、Webアプリケーションへの攻撃を監視し阻止します。

次回の勉強内容
WAFは、Webアプリケーションへの攻撃を監視し阻止します。
- 前回の勉強内容
- 勉強のきっかけになった問題
- パケットフィルタリング型ファイアウォールは、ネットワーク層の情報でアクセス制御を行うファイアウォールです。
- アプリケーションゲートウェイ型ファイアウォールは、アプリケーション層のチェックしてアクセス制御を行うファイアウォールです。
- IDSとIPSは、ネットワークを監視して危険をお知らせしてくれます。
- WAFは、Webアプリケーションへの攻撃を監視し阻止します。
- WAFを設置する場合、設置場所には「ネットワーク」と「ウェブサーバ」の 2 つがあります。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
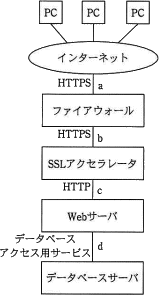
図のような構成と通信サービスのシステムにおいて,Webアプリケーションの脆弱性対策としてネットワークのパケットをキャプチャしてWAFによる検査を行うとき,WAFの設置場所として最も適切な箇所はどこか。ここで,WAFには通信を暗号化したり復号したりする機能はないものとする。
情報セキュリティスペシャリスト平成25年春期 午前Ⅱ 問4
IDSとIPSは、ネットワークを監視して危険をお知らせしてくれます。
WAFは、Webアプリケーションへの攻撃を監視し阻止します。
- 正式名称 : Web Application Firewall
- 読み方 : わふ
通過するパケットのIPアドレスやポート番号だけでなくペイロード部(データ部分)をチェックすることで、Webアプリケーションに対する攻撃を検知し、遮断することが可能なファイアウォールです。
平成29年秋期問45 WAFの説明はどれか|応用情報技術者試験.com
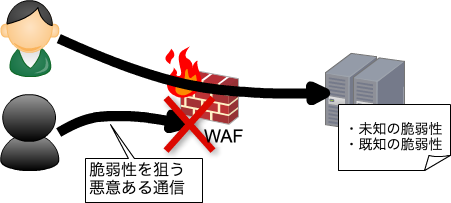
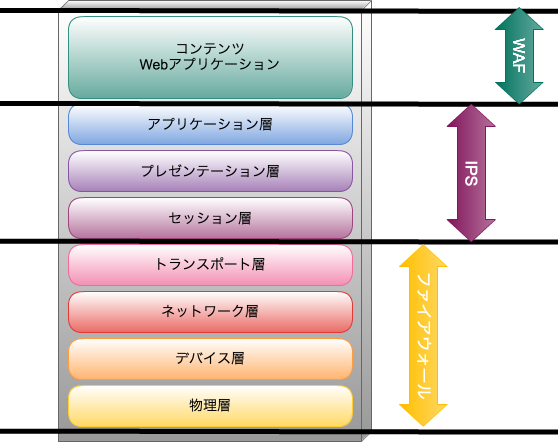
Webサーバ及びアプリケーションに起因する脆(ぜい)弱性への攻撃を遮断します。
Webアプリケーションの防御に特化したファイアウォールで、パケットのヘッダ部に含まれるIPアドレスやポート番号だけでなくペイロード部(データ部分)をチェックし、攻撃の兆候の有無を検証します。
予想問題vol.5問29 WAFを利用する目的はどれか|情報セキュリティマネジメント試験.com

特徴的なパターンが含まれるかなどWebアプリケーションへの通信内容を検査して、不正な操作を遮断します。
検出パターンには、「ウェブアプリケーションの脆弱性を悪用する攻撃に含まれる可能性の高い文字列」や「ウェブアプリケーション仕様で定義されているパラメータの型、値」といったものを定義します。
安全なウェブサイトの作り方:IPA 独立行政法人 情報処理推進機構

Webサイトに対するアクセス内容を監視し、攻撃とみなされるパターンを検知したときに当該アクセスを遮断します。
チェックされる内容には「URLパラメタ」や「クッキーの内容」などのHTTPヘッダ情報や、「POSTデータの内容」などのメッセージボディ部などがあります。
基本情報技術者平成28年秋期 午前問42
クライアントとWebサーバの間においてクライアントからWebサーバに送信されたデータを検査して、SQLインジェクションなどの攻撃を遮断するためのものです。
パケットのヘッダ部に含まれるIPアドレスやポート番号だけでなくペイロード部(データ部分)をチェックし、攻撃の兆候の有無を検証します。これによりWebアプリケーションに対する攻撃を検知し、遮断することが可能です。
平成28年春期問43 Web Application Firewall|基本情報技術者試験.com
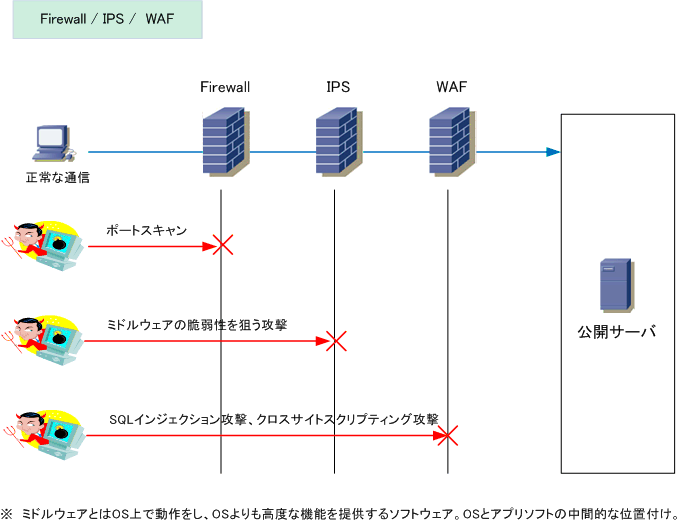
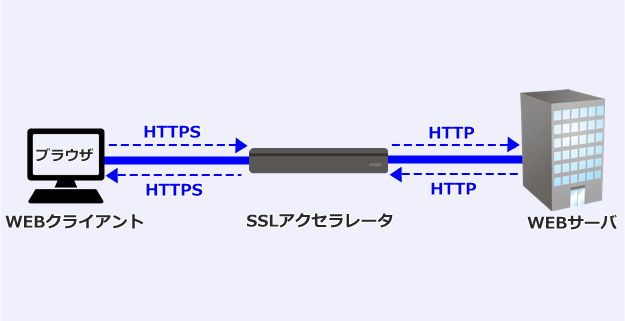
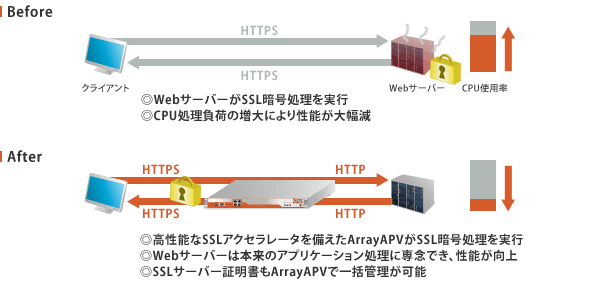
WAFを設置する場合、設置場所には「ネットワーク」と「ウェブサーバ」の 2 つがあります。
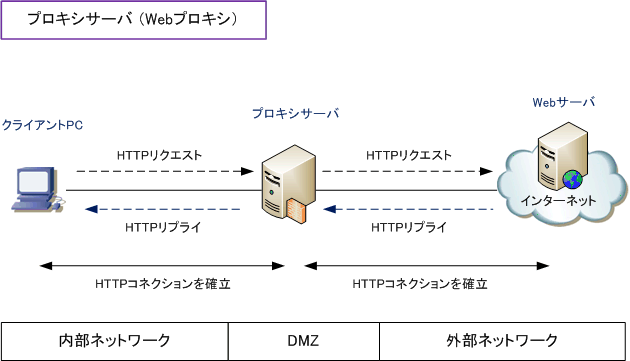
ネットワークに設置するWAFは、利用者とウェブサイト間の HTTP・HTTPS通信を通信経路上に介在することで検査します。
主な特徴は以下の通りです。





次回の勉強内容
勉強中・・・
ネットワークを監視して危険をお知らせしてくれるIDSとIPS
- 前回の勉強内容
- 勉強のきっかけになった問題
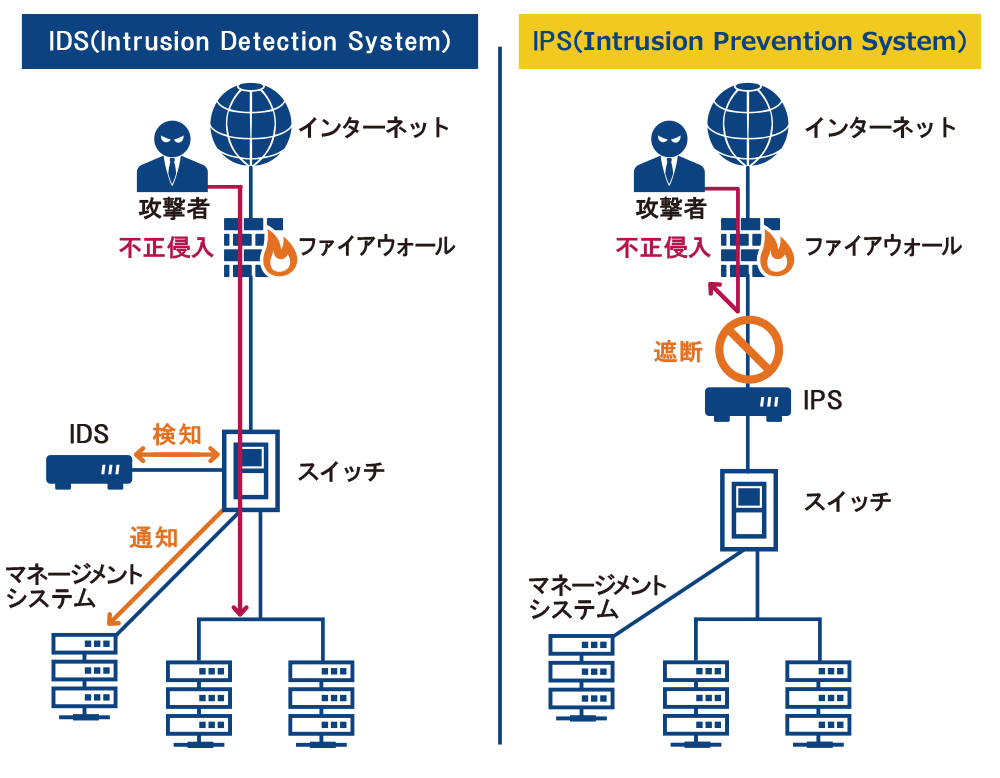
- IDSは、サーバやネットワークを監視しセキュリティポリシを侵害するような挙動を検知した場合に管理者へ通知します。
- IPSは、サーバやネットワークへの侵入を防ぐために不正な通信を検知して遮断する装置です。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
IDS(Intrusion Detection System)の特徴のうち,適切なものはどれか。
IDSは、サーバやネットワークを監視しセキュリティポリシを侵害するような挙動を検知した場合に管理者へ通知します。
- 英語: Intrusion(侵入) Detection(検出) System
- 日本語: 侵入検知システム
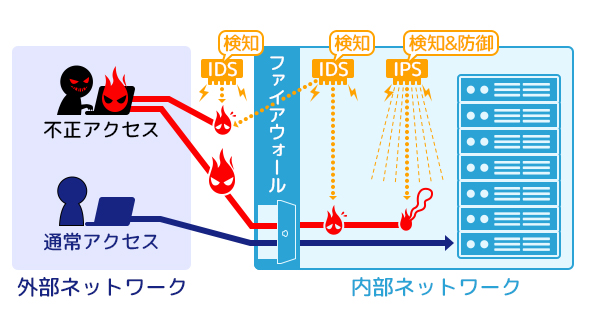
設置場所は「ネットワーク型」「ホスト型」の2種類あります。
ネットワーク型は、監視対象のネットワーク上に設置してネットワークの通信を監視します。
- 略称: NIDS
- 英語: Network-Based IDS
NIDSに通信内容を復号する機能がなければ、SSLを利用したアプリケーションを介して行われる攻撃を検知できません。

ホスト型は、監視対象サーバーに設置して通信の結果生成された受信データやログを監視します。
- 略称: HIDS
- 英語: Host-Based IDS
ホスト型IDSでは,シグネチャとのパターンマッチングを失敗させるためのパケットが挿入された攻撃でも検知できる。
平成18年春期問73 IDSの特徴のうち適切なもの|応用情報技術者試験.com



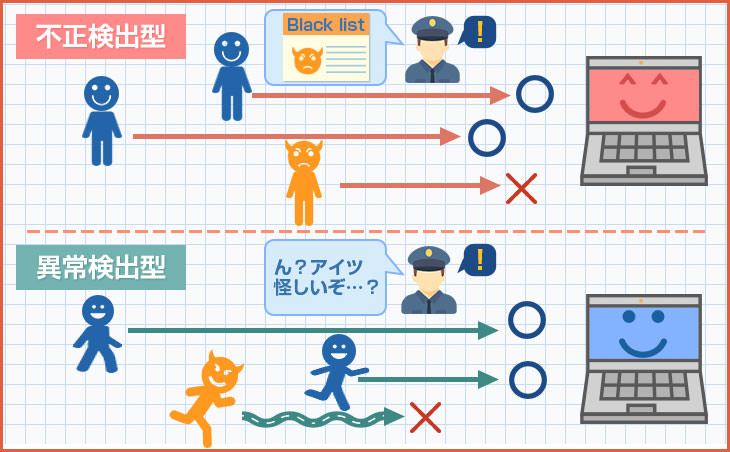
IPSは、サーバやネットワークへの侵入を防ぐために不正な通信を検知して遮断する装置です。
- 英語: Intrusion Prevention System
- 日本語: 侵入防御システム
IDSとの大きな違いは、不正なアクセスを管理者へ通知するだけではなく遮断してくれるところです。


次回の勉強内容
アプリケーションゲートウェイ型ファイアウォールは、アプリケーション層でパケットのデータまでをチェックしてアクセス制御を行うファイアウォールです。
- 前回の勉強内容
- 勉強のきっかけになった問題
- アプリケーションゲートウェイ型ファイアウォールは、アプリケーション層でパケットのデータまでをチェックしてアクセス制御を行うファイアウォールです。
- アプリケーションゲートウェイ型ファイアウォールは、インターネットと内部のネットワークを切り離します。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
ファイアウォールの方式に関する記述のうち,適切なものはどれか。
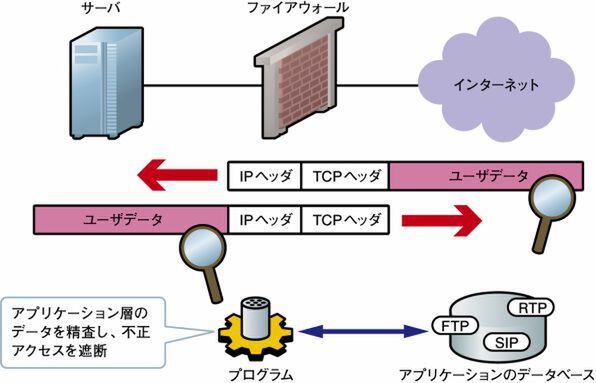
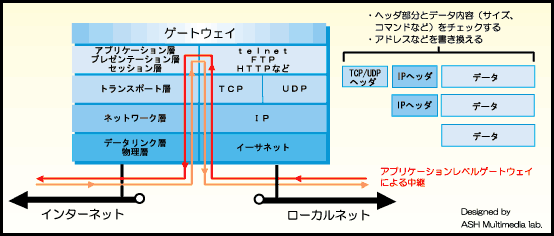
アプリケーションゲートウェイ型ファイアウォールは、アプリケーション層でパケットのデータまでをチェックしてアクセス制御を行うファイアウォールです。
| ファイアウォール | セキュリティ | 通信 |
|---|---|---|
| パケットフィルタリング型 | バッファオーバーフロー攻撃*1やコンピュータウィルスが含まれる電子メールなどは防げない | 早い |
| アプリケーションゲートウェイ型 | バッファオーバーフロー攻撃やコンピュータウィルスが含まれる電子メールなどは防げるが、なりすましは防げない | データまでチェックするので遅い |
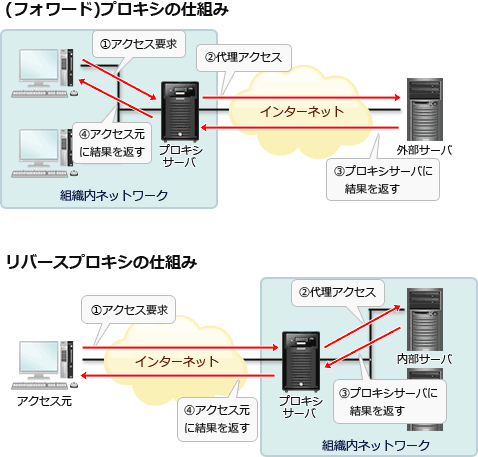
アプリケーションゲートウェイ型ファイアウォールは、インターネットと内部のネットワークを切り離します。

インターネットからのパケットをアプリケーションゲートウェイが代理で受け取ります。




次回の勉強内容
パケットフィルタリング型ファイアウォールは、ネットワーク層でパケットのヘッダ情報でアクセス制御を行うファイアウォールです。
- 前回の勉強内容
- 勉強のきっかけになった問題
- パケットフィルタリング型ファイアウォールは、ネットワーク層でパケットのヘッダ情報でアクセス制御を行うファイアウォールです。
- パケットフィルタリング型ファイアウォールには、種類があります。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
ファイアウォールにおけるダイナミックパケットフィルタリングの特徴はどれか。
パケットフィルタリング型ファイアウォールは、ネットワーク層でパケットのヘッダ情報でアクセス制御を行うファイアウォールです。
パケットのヘッダ情報内のIPアドレス及びポート番号を基準にパケット通過の可否を決定します。
フィルタリングルールを用いて、本来必要なサービスに影響を及ぼすことなく外部に公開していないサービスへのアクセスを防げます。
社内ネットワークとインターネットの接続点にパケットフィルタリング型ファイアウォールを設置して,社内ネットワーク上のPCからインターネット上のWebサーバ(ポート番号80) にアクセスできるようにするとき,フィルタリングで許可するルールの適切な組合せはどれか。
平成23年特別問44 パケットフィルタリング|基本情報技術者試験.com

パケットフィルタリング型ファイアウォールには、種類があります。
Part2 フィルタリング---ファイアウォールの基本機能,フィルタリングの違いを理解する | 日経クロステック(xTECH)

スタティックパケットフィルタリングは、行きと戻りのヘッダ情報をフィルタリングテーブルに登録してアクセスを制御するファイアウォールです。

社内ネットワークとインターネットの接続点に,ステートフルインスペクション機能をもたない,静的なパケットフィルタリング型のファイアウォールを設置している。このネットワーク構成において,社内のPCからインターネット上のSMTPサーバに電子メールを送信できるようにするとき,ファイアウォールで通過を許可するTCPパケットのポート番号の組合せはどれか。ここで,SMTP通信には,デフォルトのポート番号を使うものとする。
(引用元)平成30年春期問44 パケットフィルタリングルール|基本情報技術者試験.com

ダイナミックパケットフィルタリングは、通信のやり取りを判断して動的にフィルタリングテーブルが更新するファイアウォールです。
- 英語: dynamic(動的な) packet filtering
戻りのパケットに関しては,過去に通過したリクエストパケットに対応したものだけを通過させることができます。
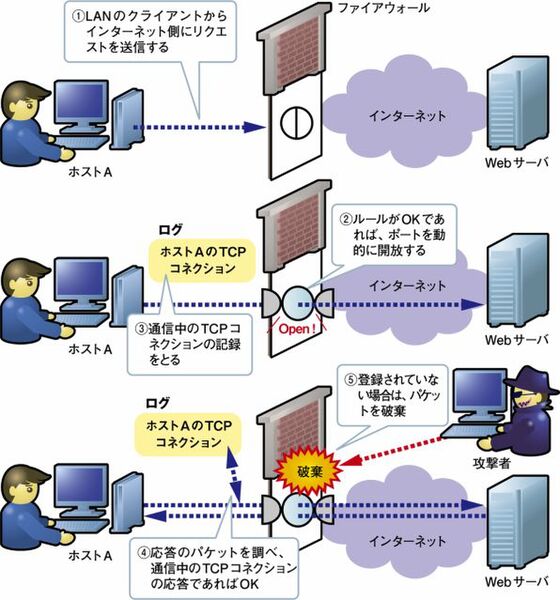
ステートフルパケットインスペクションは、出入りするパケットの通信状態を把握して外部から送信されたパケットのアクセスを動的に制御するファイアウォールです。
- 英語: Stateful(処理状態を把握す) Packet Inspection(検査)
- 略称: SPI
- 別名: ステートフルインスペクション、ステートファイアウォール
ダイナミックパケットフィルタリングの1つです。
パケットフィルタリングを拡張した方式であり,過去に通過したパケットから通信セッションを認識し,受け付けたパケットを通信セッションの状態に照らし合わせて通過させるか遮断させるかを判断します。
このファイアウォールはコンテキストの中でパケットを判断します。 コンテキストとは、文脈という意味で、この場合はプログラムが処理内容を置かれた状態や状況、 与えられた条件から判断するという意味です。
覚えておくべき4種のファイアウォール
個々のセッションごとに過去の通信を保持しているため「順序の矛盾した攻撃パケットを遮断することができる」ことや、常に最小限の許可ルールが追加されるため「アクセス制御リストの設定不備を突く攻撃を受けにくい」という優れた点があり、多くのファイアウォール製品に採用されています。
情報セキュリティスペシャリスト平成27年秋期 午前Ⅱ 問3

次回の勉強内容
TPMは、耐タンパ性に優れたセキュリティチップです。
前回の勉強内容
勉強のきっかけになった問題
PCに内蔵されるセキュリティチップ(TPM:Trusted Platform Module)がもつ機能はどれか。
ア. TPM間での共通鍵の交換
イ. 鍵ペアの生成
ウ. ディジタル証明書の発行
エ. ネットワーク経由の乱数発信
情報セキュリティスペシャリスト平成26年春期 午前Ⅱ 問5
TPMは、鍵ペアの生成を行います。
- 正式名称: Trusted(信用されている) Platform Module

TCGで定義されたセキュリティの仕様に準拠したセキュリティチップです。
- 正式名称: Trusted Computing Group
PCなどの機器に搭載され、鍵生成やハッシュ演算及び暗号処理を行うセキュリティチップです。

TPMによって提供される機能には以下のようなものがあります。
- OSやアプリケーションの改ざん検知
- 端末認証
- ストレージ全体の暗号化
TPMは、耐タンパ性に優れています。
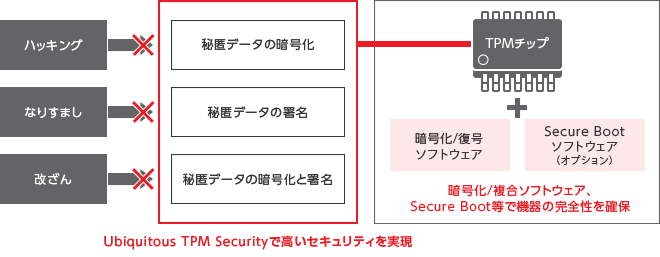
耐タンパ性は、外部から内部データに対して行われる改ざん・解読・取出しなどの行為に対する耐性度合いです。
- 英語 : tamper(許可なくいじる) resistance(抵抗する力)
マイクロプロセッサの耐タンパ性を向上させる手法として,適切なものはどれか。
答. チップ内部を物理的に解析しようとすると,内部回路が破壊されるようにする。
平成30年秋期問22 マイクロプロセッサの耐タンパ性|応用情報技術者試験.com
ICカードの耐タンパ性を高める対策はどれか。
答. 信号の読み出し用プローブの取付けを検出するとICチップ内の保存情報を消去する回路を設けて,ICチップ内の情報を容易に解析できないようにする。
平成29年秋期問44 耐タンパ性を高める対策はどれか|応用情報技術者試験.com
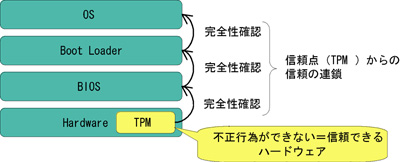
HDDやメインのCPUとセキュリティ関連機能をもったTPMが物理的に分かれることで耐タンパ性が高まります。
LSIは、ICの大きいのです。
- 正式名称: Large-scale Integrated(統合された) Circuit(回路)
- 日本語: 大規模集積回路
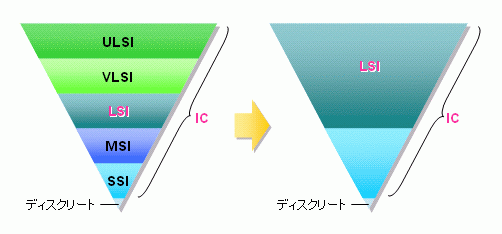


従来はボード上で実現していたシステムを一つのチップ上で実現したLSIのことをSoCといいます。
- 正式名称: System on a Chip
SoC(System on a Chip)の説明として,適切なものはどれか。
答. 必要とされるすべての機能(システム)を同一プロセスで集積した半導体チップ
平成28年春期問24 SoC(System on a Chip)の説明|応用情報技術者試験.com

次回の勉強内容
イーサネットにおけるコリジョンドメインとブロードキャストドメイン
- 前回の勉強内容
- 勉強のきっかけになった問題
- イーサネットは、コンピュータネットワークにおける有線LANの規格です。
- CSMA/CDは、イーサネットでの接続方式の一つです。
- コリジョンが発生する範囲をコリジョンドメインといいます。
- イーサネットで使用されるアドレスには種類があります。
- TCP/IPネットワークにおいてARPというプロトコルを使うことでIPアドレスからMACアドレスを得ることができます。
- ブロードキャストできるネットワークの範囲をブロードキャストドメインといいます。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
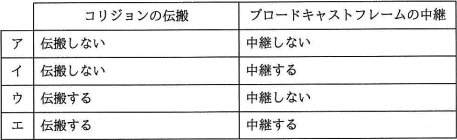
ルータで接続された二つのセグメント間でのコリジョンの伝搬とブロードキャストフレームの中継について,適切な組合せはどれか。
イーサネットは、コンピュータネットワークにおける有線LANの規格です。
CSMA/CDは、イーサネットでの接続方式の一つです。
- 正式名称 : Carrier Sense Multiple Access with Collision(衝突) Detection(発見)
- 日本語 : 搬送波感知多重アクセス/衝突検出方式
各ノードは伝送媒体が使用中かどうかを調べ、使用中でなければ送信を行い、衝突を検出したらランダムな時間経過後に再度送信を行います。
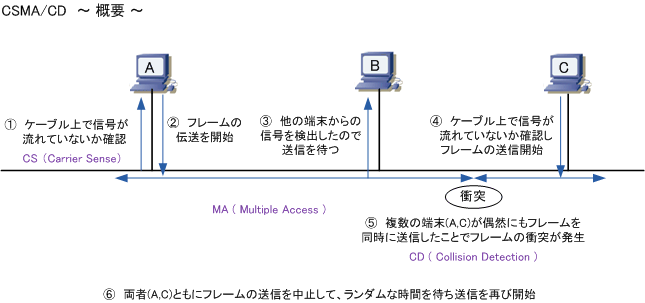
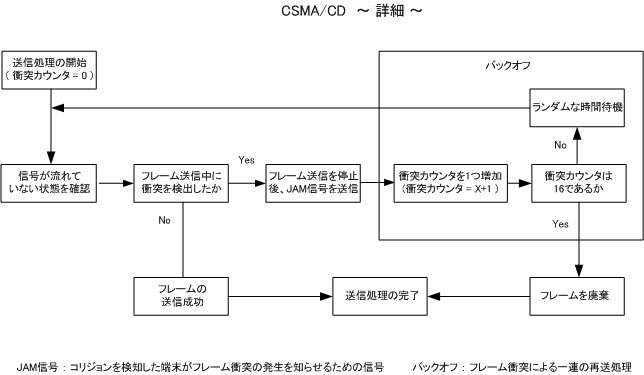
それぞれのステーション*1がキャリア検知を行うとともに、送信データの衝突が起きた場合は再送します。
- 伝送路上に他のノードからフレームが送出されていないかを確認する
- 複数のクライアントは同じ回線を共用し、他者が通信をしていなければ自分の通信を開始する
- 複数の通信が同時に行われた場合は衝突を検出し、送信を中止してランダム時間待ってから再び送信をする
衝突発生時の再送動作によって、衝突の頻度が増すとスループット*2が下がります。
CSMA/CDは、伝送路上の通信量が増加するにつれて衝突の発生も増加し、さらに再送が増え通信量が増えてしまうという欠点があります。一般にCSMA/CD方式では、伝送路の使用率が30%を超えると急激に送信遅延時間が長くなってしまい実用的ではなくなると言われています。
平成24年秋期問30 CSMA/CD方式に関する記述|応用情報技術者試験.com
同時にフレームを送信している端末の間でフレームが衝突することをコリジョンとも言います。
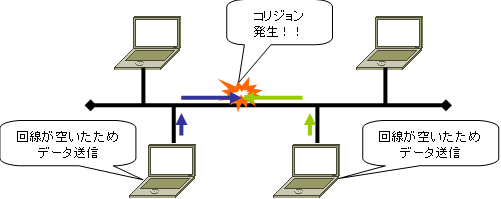
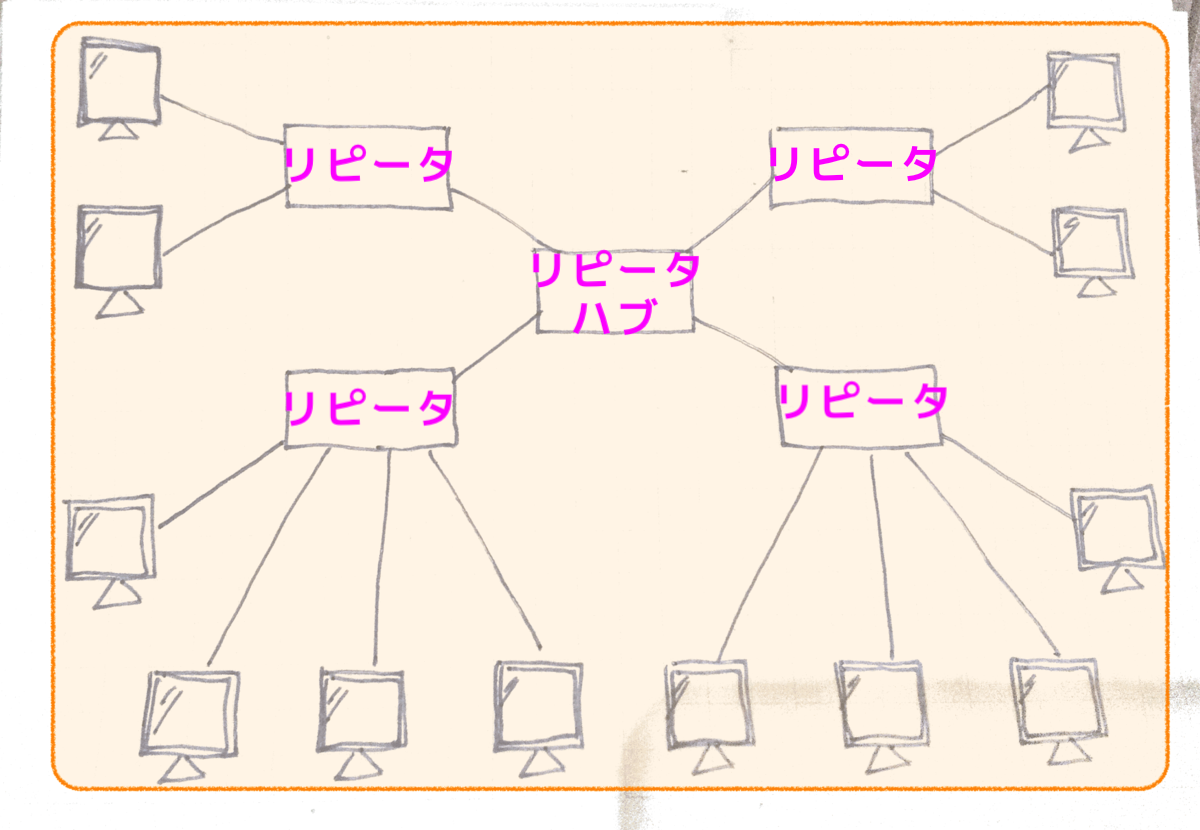
コリジョンが発生する範囲をコリジョンドメインといいます。

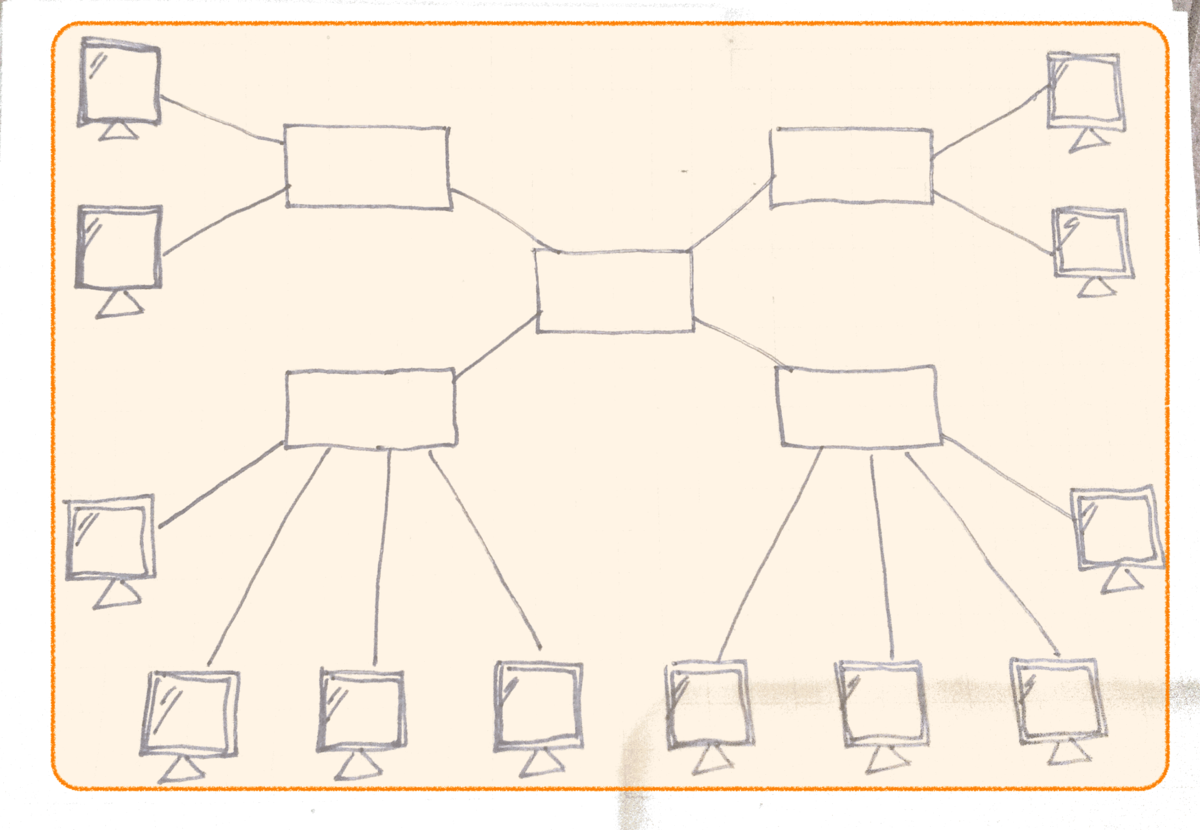
コリジョンを発生しにくくするにはコリジョンドメインを分割します。
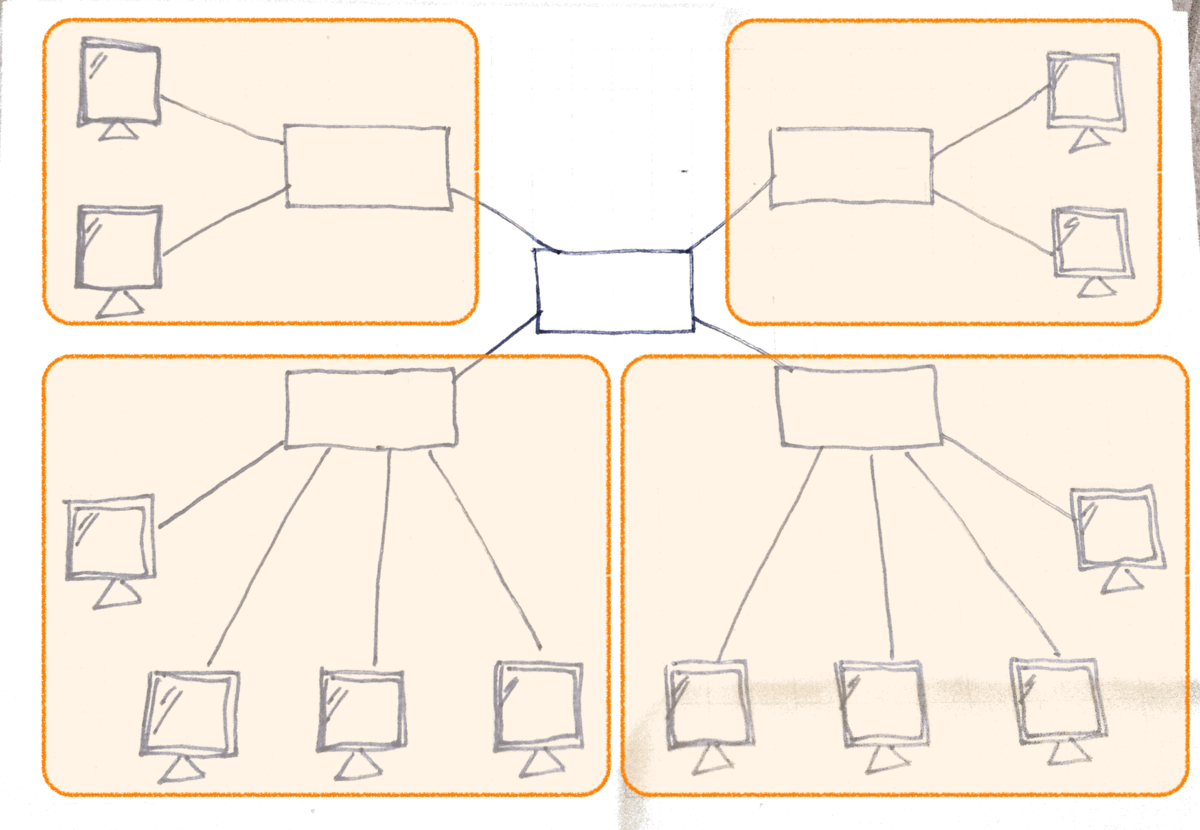
OSI参照モデルでの物理層の機器ではコリジョンドメインを分割できません。
| OSI参照モデル | 機器 | 説明 |
|---|---|---|
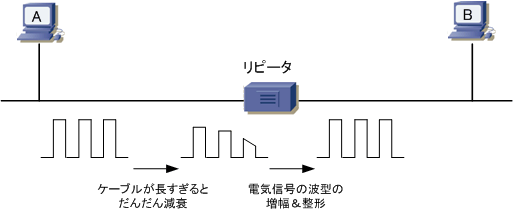
| 物理層 | リピータ | 通信ネットワークの中継機器で、一方のケーブルから流れてきた信号を単純にもう一方のケーブルに送り出す装置 |
| 物理層 | ハブ | ネットワークの中心に位置する集線装置*3であり、複数のネットワーク機器を接続する装置 |
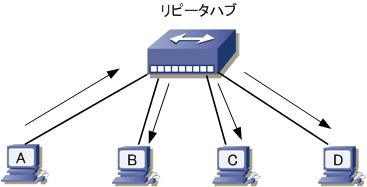
| 物理層 | リピータハブ | 通信ネットワークのハブの一つで、すべての信号をすべての端末に送る機器、複数のポートを持ってるリピータ |
OSI参照モデルでのデータリンク層とネットワーク層の機器でコリジョンドメインを分割できます。
| OSI参照モデル | 機器 | 説明 |
|---|---|---|
| ネットワーク層 | L3スイッチ | ネットワークの中継機器の一つで、 ネットワーク層とリンク層の両方の制御情報に基づいてデータの転送先の決定を行う |
| ネットワーク層 | ルータ | 異なるネットワーク同士を接続する機器 |
| データリンク層 | L2スイッチ | MACアドレスを含んだ情報を使って中継動作を行う |
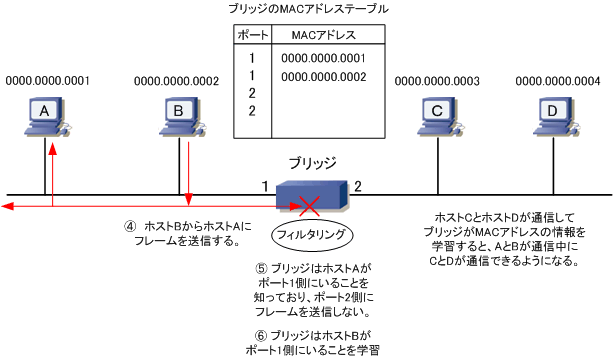
| データリンク層 | ブリッジ | 複数のネットワークを結ぶ中継機器のうち、 受信したデータのMACアドレスなどデータリンク層の宛先情報を参照して中継の可否を判断する |
イーサネットで使用されるアドレスには種類があります。
| 種類 | 説明 |
|---|---|
| ユニアドレス | 特定の機器にデータを送信するために使用されるアドレス |
| マルチキャストアドレス | 特定の複数機器にデータを送信するために使用されるアドレス |
| ブロードキャストアドレス | ネットワーク内のすべての機器にデータを送信するために使用されるアドレス |
ブロードキャストアドレスのIPアドレスは、ホスト部の全ビットが1になります。
IPアドレスが 192.168.0.x でサブネットマスクが 255.255.255.0 の TCP/IPネットワークで,ブロードキャストアドレスはどれか。
イ. 192.168.0.255
平成20年秋期問50 ブロードキャストアドレス|基本情報技術者試験.com
IPアドレス 192.168.57.123/22 が属するネットワークのブロードキャストアドレスはどれか。
ウ. 192.168.59.255
まず、IPアドレス 192.168.57.123 は2進数表記では以下のビット列です。
11000000 10101000 00111001 01111011
ブロードキャストアドレスはホストアドレス部である下位10ビットを全て"1"にした以下のビット列です。
11000000 10101000 00111011 11111111
平成28年春期問34 ブロードキャストアドレスはどれか|基本情報技術者試験.com
ネットワークアドレス192.168.10.192/28のサブネットにおけるブロードキャストアドレスはどれか。
イ. 192.168.10.207
11000000 10100000 00001010 11000000
ブロードキャストアドレスは、ホストアドレス部のビットをすべて「1」にした次のアドレスになります。
11000000 10100000 00001010 11001111
平成19年秋期問52 ブロードキャストアドレス|応用情報技術者試験.com
IPv4アドレス 172.22.29.44/20 のホストが存在するネットワークのブロードキャストアドレスはどれか。
ウ. 172.22.31.255
平成26年春期問33 ブロードキャストアドレスはどれか|応用情報技術者試験.com

ブロードキャストアドレスは、用途が決まっているのでネットワークに接続する機器に割り振っていはいけません。
次のネットワークアドレスとサブネットマスクをもつネットワークがある。このネットワークを利用する場合,PCに割り振ってはいけないIPアドレスはどれか。
ネットワークアドレス: 200.170.70.16
サブネットマスク : 255.255.255.240エ. 200.170.70.31
平成26年秋期問34 割り振ってはいけないIPアドレス|基本情報技術者試験.com
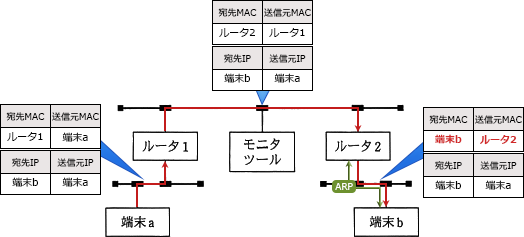
TCP/IPネットワークにおいてARPというプロトコルを使うことでIPアドレスからMACアドレスを得ることができます。
- 正式名称 : Address Resolution(èzəlúːʃən、解明) Protocol
MACアドレスフィルタリングは、ARPを利用してPCのMACアドレスを確認し、事前に登録されているMACアドレスである場合だけ通信を許可する機能です。
https://network.yamaha.com/setting/wireless_lan/airlink/mac-wlx313
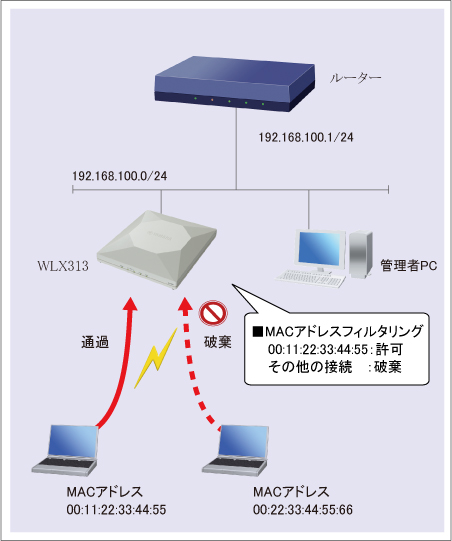
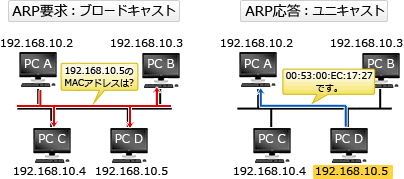
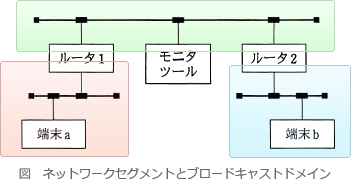
ブロードキャストできるネットワークの範囲をブロードキャストドメインといいます。
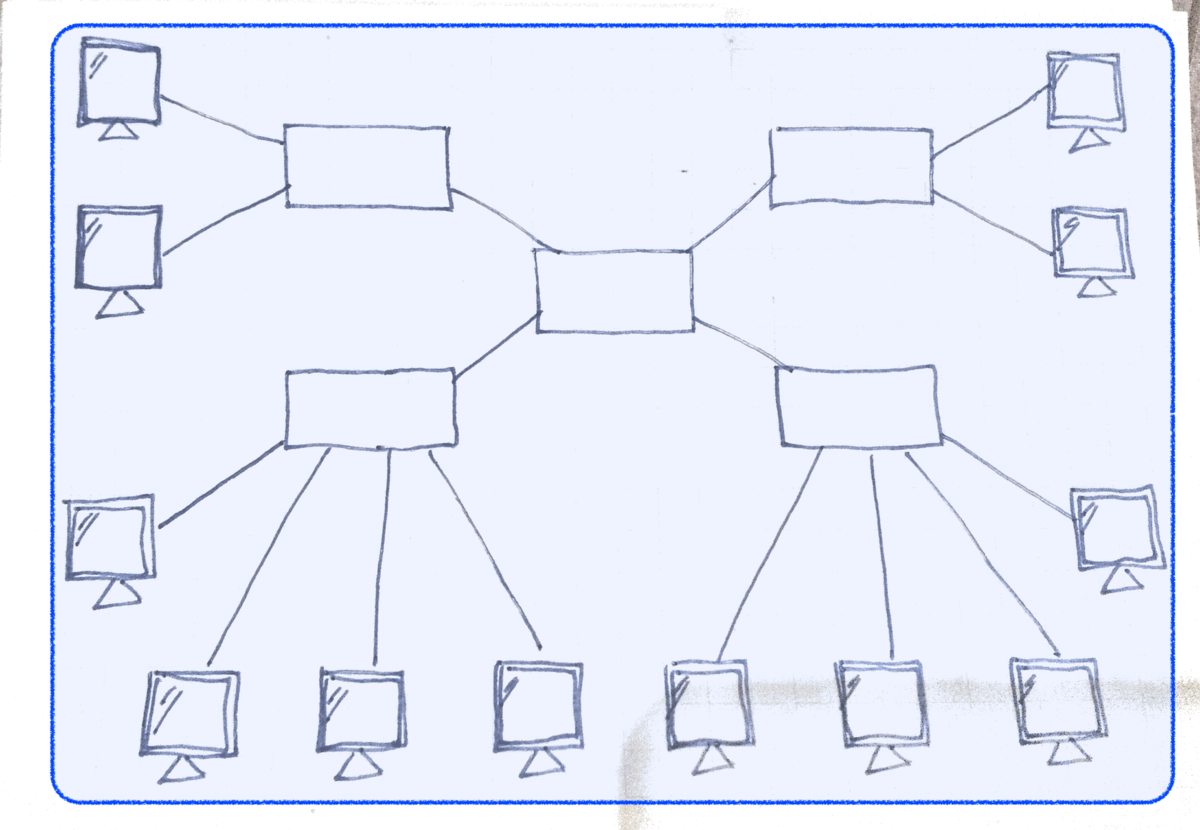
負荷を下げるためにはブロードキャストドメインを分割します。
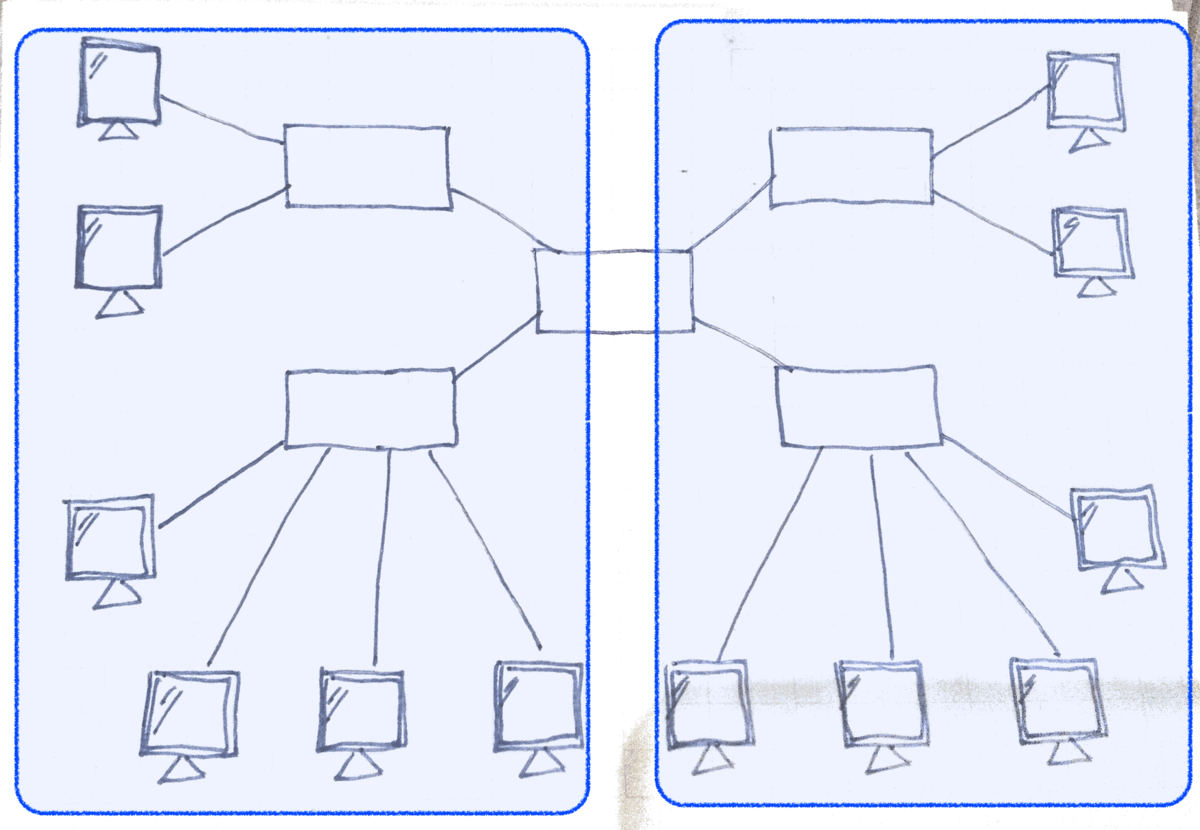

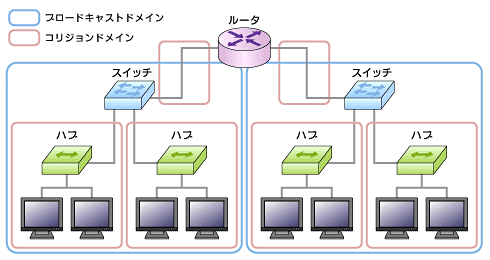
ネットワーク層の機器をまたぐとブロードキャストフレームは伝搬されません。


次回の勉強内容
*1:イーサネットの規格では、ノードのことを「ステーション」と呼んでいる。ステーションはネットワークに接続されるコンピュータの総称で、コンピュータやプリンタなどネットワークを介して通信するすべてのデバイスを表す。出典:第6回 イーサネット(その1) - イーサネットの規格とCSMA/CDアクセス制御方式:詳説 TCP/IPプロトコル(3/5 ページ) - @IT
*3:複数の伝送路を収容、接続する装置
イーサネットの基本
- 前回の勉強内容
- イーサネットは、コンピュータネットワークにおける有線LANの規格です。
- イーサネット機器にあるLANケーブルの差込口の仕様にはMDIとMDI-Xの2種類あります。
- MACアドレスは、ネットワークに接続する機器を識別する16進数のアドレスです。
- ルーターは、異なるネットワーク同士を接続する機器です。
- 次回の勉強内容
前回の勉強内容
イーサネットは、コンピュータネットワークにおける有線LANの規格です。
有線LANを使うときの「物理層」と「データリンク層」の仕様を決めている規格です。
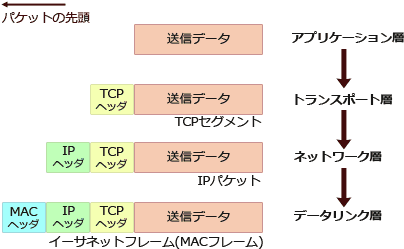
イーサネットフレームは、イーサネットでの通信で使用するデータフォーマットのことです。

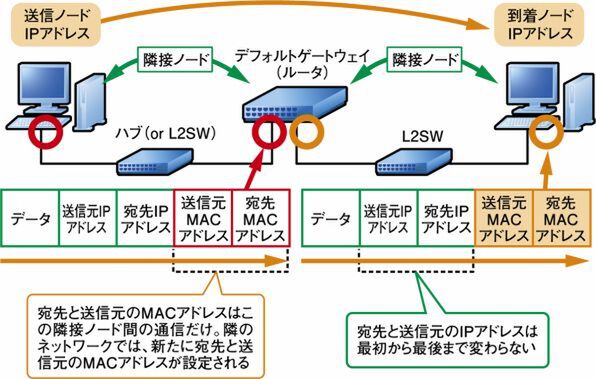
OSI基本参照モデル各層ごとにヘッダをフレームに入れていくので、宛先情報の送出順序は「宛先MACアドレス > 宛先IPアドレス > 宛先ポート番号」になります。
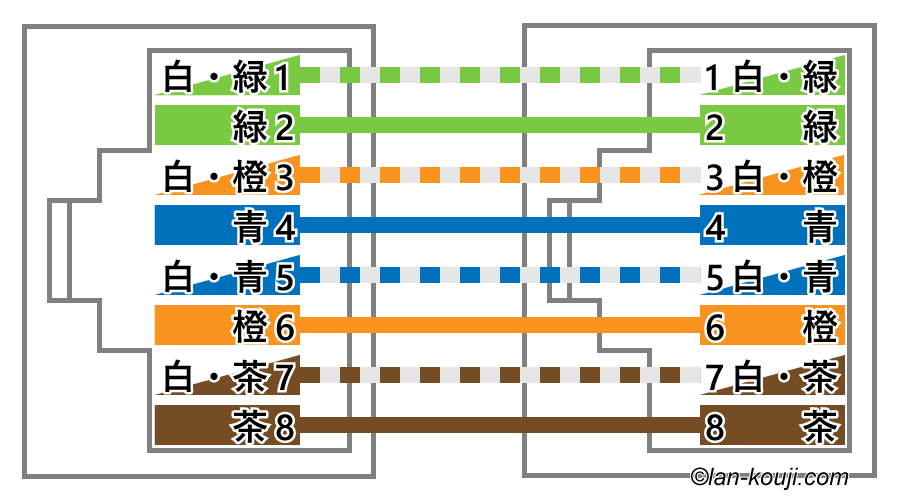
イーサネット機器にあるLANケーブルの差込口の仕様にはMDIとMDI-Xの2種類あります。
LANケーブルのコネクタには8このピンがあります。
| ポート | 送信用のピン | 受信用のピン |
|---|---|---|
| MDI (Medium Dependent Interface) |
1と2番 | 3と6番 |
| MDI-X | 3と6番 | 1と2番 |


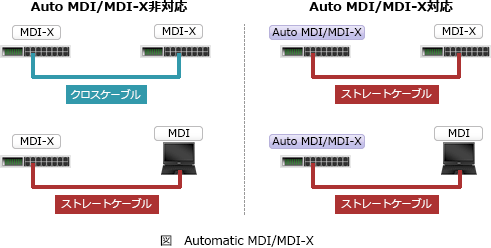
ポートを正しくつなぐには接続機器によってストレートケーブルとクロスケーブルを使い分ける必要があります。

Automatic MDI/MDI-Xは、コネクタの送信端子と受信端子が正しい組合せとなるように自動で判別して切り替える機能なので、対応しているケーブルを使えばケーブルの使い分けを気にしなくてすみます。
PCやスイッチングハブがもつイーサネットインタフェース(物理ポート)の,Automatic MDI/MDI-Xの機能はどれか。
- コネクタの送信端子と受信端子が正しい組合せとなるように,自動で判別して切り替える機能
- 接続した機器のアドレスを学習し,イーサネットフレームを該当するインタフェースにだけ転送する機能
- 通信経路のループを自動的に検出する機能
- 通信速度や,全二重と半二重のデータ通信モードを自動的に設定する機能
MACアドレスは、ネットワークに接続する機器を識別する16進数のアドレスです。
悪さをしている機器を探し出す -- No.3 MACアドレスから機器のメーカーを調べる | 日経クロステック(xTECH)

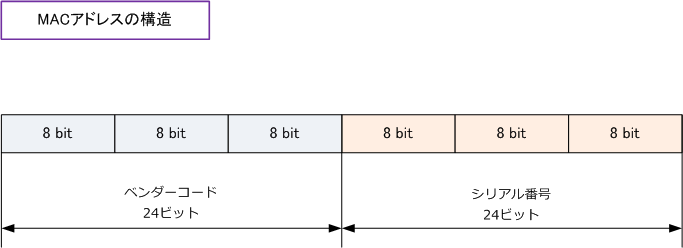
MACアドレスの構成には決まりがあります。
| 位置 | 意味 |
|---|---|
| 最初の24ビット | ベンダーID(OUI) |
| 次の8ビット | 機種ID |
| 最後の16ビット | 製品のシリアルID |
(参照元)平成24年秋期問33 MACアドレスの構成|基本情報技術者試験.com
ルーターは、異なるネットワーク同士を接続する機器です。
複数のネットワークをOSI基本参照モデルの第3層(ネットワーク層)で接続し、パケットを中継します。


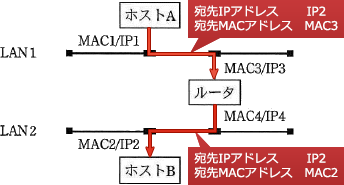
ルーターは「パケットのあて先端末のIPアドレス」と「MACアドレス」に基づいて、宛先のルータだけに中継します。
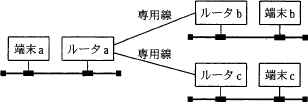
伝送媒体やアクセス制御方式の異なるネットワークの接続が可能であり、送信データのIPアドレスを識別し、データの転送経路を決定します。

次回の勉強内容
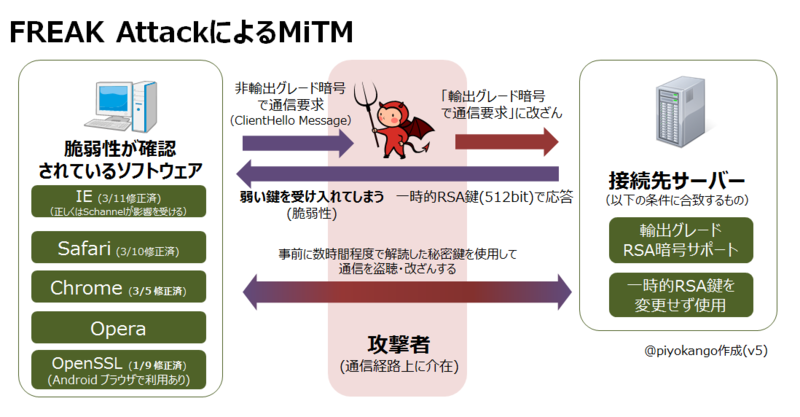
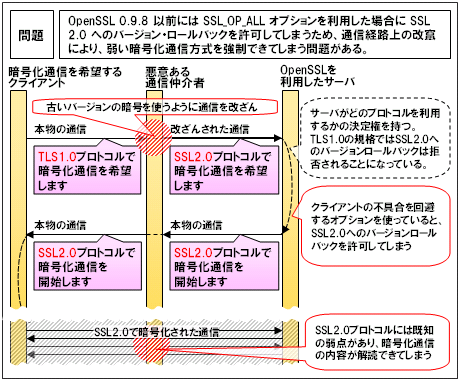
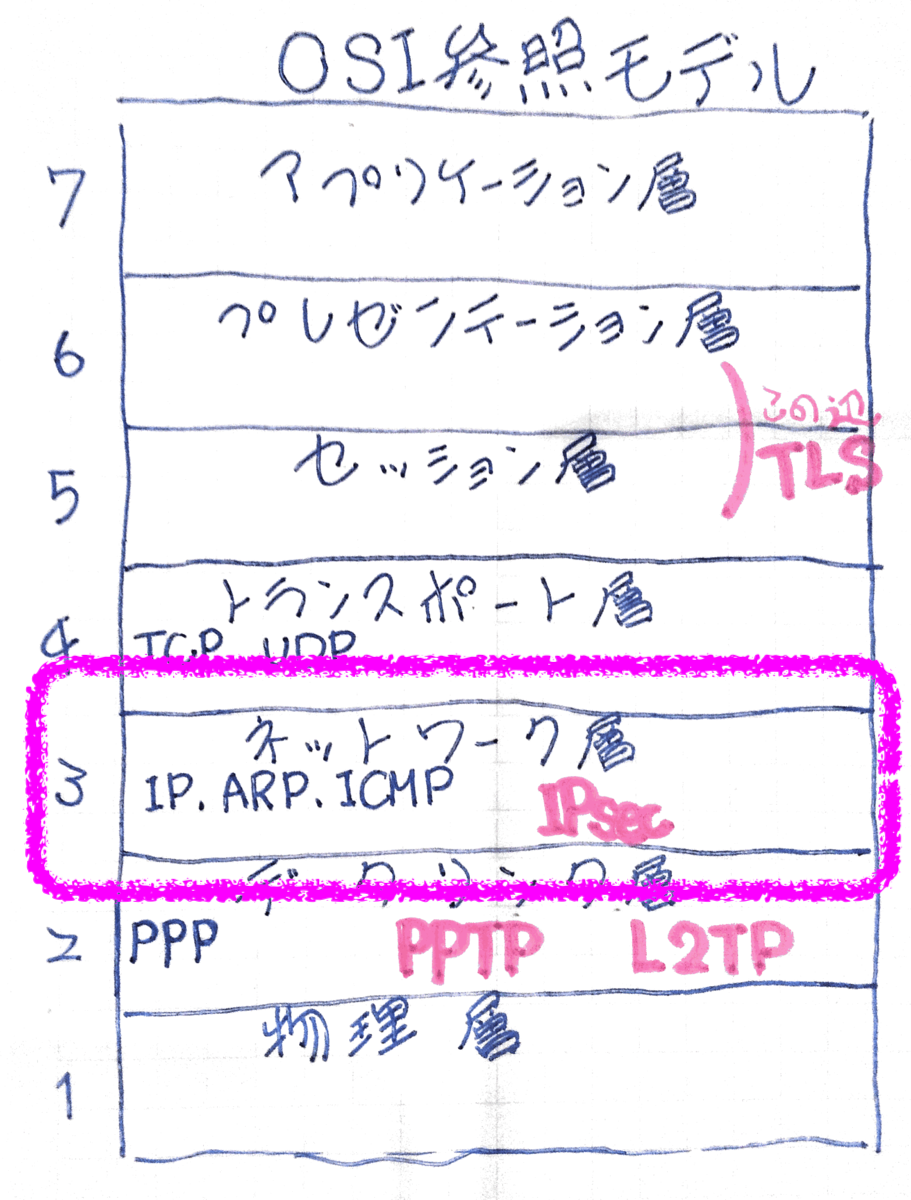
SSL/TLSの基礎知識
- 前回の勉強内容
- 勉強のきっかけになった問題
- インターネット上でのデータの通信を暗号化したプロトコルをSSLといいます。
- SSLが進化してTLSができました。
- SSL/TLSでのクライアントとサーバでのやり取りではディジタル証明書が使われます。
- SSL/TLSは新しいバージョンを使用しないと攻撃を受ける可能性が高まります。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
- 暗号化通信中にクライアントPCからサーバに送信するデータを操作して,強制的にサーバのディジタル証明書を失効させる。
- 暗号化通信中にサーバからクライアントPCに送信するデータを操作して,クライアントPCのWebブラウザを古いバージョンのものにする。
- 暗号化通信を確立するとき,弱い暗号スイートの使用を強制することによって,解読しやすい暗号化通信を行わせる。
- 暗号化通信を盗聴する攻撃者が,暗号鍵候補を総当たりで試すことによって解読する。
インターネット上でのデータの通信を暗号化したプロトコルをSSLといいます。
- 正式名称 : Secure(安全な) Sockets(受け口) Layer
通常インターネット上での通信は「http(HyperText Transfer Protocol)」で行われますが、送受信されるデータは暗号化することができず、盗聴や改ざんを防げません。
しかし、SSLプロトコルを使用することで通信データは暗号化され、第三者が盗み見しようとしても解読することができません。
https://jp.globalsign.com/service/ssl/knowledge/
SSLで暗号化されたサイトのURLは「https」になります。
- 正式名称 : HyperText Transfer Protocol Secure
- 別名: HTTP over TLS
上記のサイトも暗号化されていてURLの先頭は「https」になります。

攻撃者が社内ネットワークに仕掛けたマルウェアによってHTTPSが使われると、通信内容がチェックできないので、秘密情報が社外に送信されてしまいます。
HTTPSではクライアント-サーバ間の通信が暗号化されます。このため、もし通信経路上にプロキシサーバ等が介在したとしても内容のチェックはできません。
応用情報技術者平成29年春期 午前問44
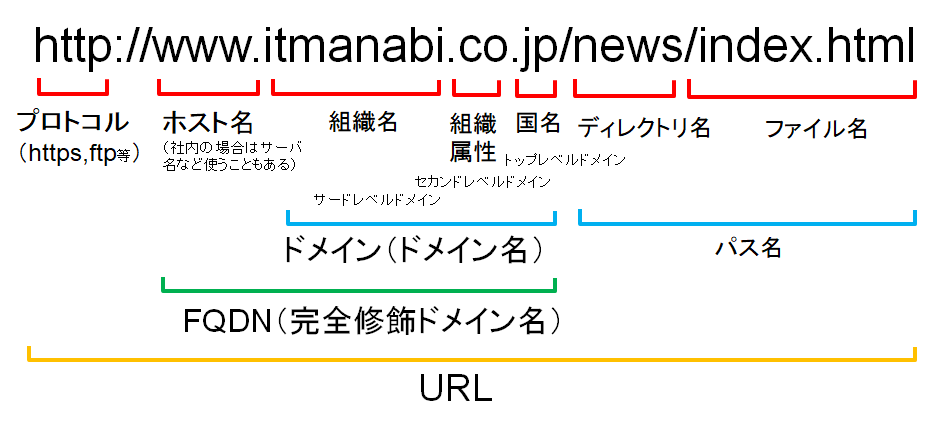
SSLを利用するWebサーバでは、そのFQDNをディジタル証明書に組み込みます。
ディジタル証明書のコモンネームにFQDNを設定します。
ディジタル証明書のコモンネームとサーバに設定されているFQDNを比較して、一致していたらSSL通信を開始することができます。
Google ChromeではFQDNのコモンネームへの設定は非推奨なのでSubject Alternative Nameに設定します。
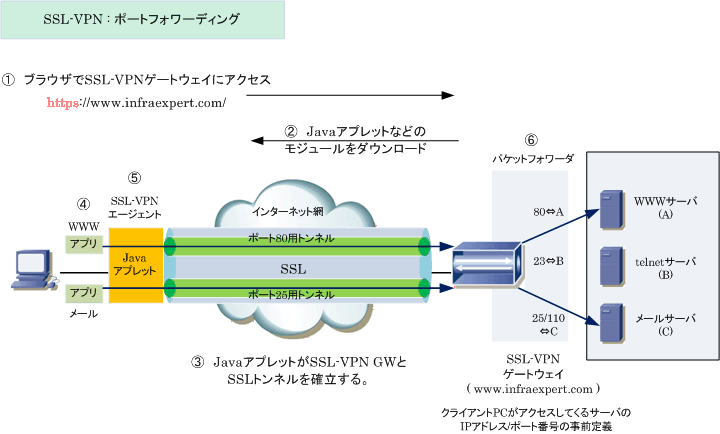
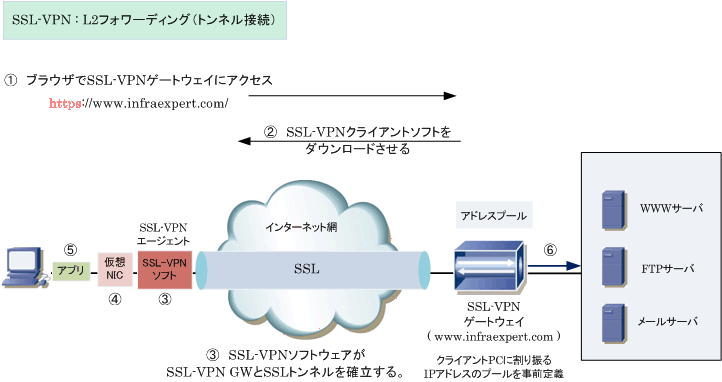
SSLが進化してTLSができました。
インターネットなどのTCP/IPネットワークでデータを暗号化して送受信するプロトコル(通信手順)の一つです。
データを送受信する一対の機器間で通信を暗号化し、中継装置などネットワーク上の他の機器による成りすましやデータの盗み見、改竄などを防ぐことができます。
インターネットに接続された利用者のPCから,DMZ上の公開Webサイトにアクセスし,利用者の個人情報を入力すると,その個人情報が内部ネットワークのデータベース(DB)サーバに蓄積されるシステムがある。このシステムにおいて,利用者個人のディジタル証明書を用いたTLS通信を行うことによって期待できるセキュリティ上の効果はどれか。
- PCとDBサーバ間の通信データを暗号化するとともに,正当なDBサーバであるかを検証することができるようになる。
- PCとDBサーバ間の通信データを暗号化するとともに,利用者を認証することができるようになる。
- PCとWebサーバ間の通信データを暗号化するとともに,正当なDBサーバであるかを検証することができるようになる。
- (答え)PCとWebサーバ間の通信データを暗号化するとともに,利用者を認証することができるようになる。
出典 : 平成30年 秋期 応用情報技術者試験 午前問40
TSLの特徴
TSLの生い立ち
- 1990年代 : SSLをNetscape Communications社が開発
- 1999年
- 2006年 : TLS 1.0で発見された新たな攻撃手法への対処など改良を加えたバージョンとして、TLS 1.1がRFC 4346として公開される
- 2008年 : より安全性の高いハッシュを利用できるようにするなど改良を加えたTLS 1.2がにRFC 5246として公開される
- 2014年 : SSL 3.0に一定の条件の下で通信の一部が第三者に漏えいする可能性があるPOODLEが報告される
- 2018年 : TLS 1.3がRFC 8446として公開される

SSL/TLSでのクライアントとサーバでのやり取りではディジタル証明書が使われます。
- クライアントからのSSL/TLSによる接続要求に対し,Webサーバは証明書をクライアントに送付する。
- クライアントは,保持している認証局の公開鍵によってこのサーバ証明書の正当性を確認する。
- クライアントは,共通鍵生成用のデータを作成し,サーバ証明書に添付されたWebサーバの公開鍵によってこの共通鍵生成用データを暗号化し,Webサーバに送付する。
- 受け取ったWebサーバは,自らの秘密鍵によって暗号化された共通鍵生成用データを復号する。
- クライアントとWebサーバの両者は,同一の共通鍵生成用データによって共通鍵を作成し,これ以降の両者間の通信は,この共通鍵による暗号化通信を行う。

利用者個人のディジタル証明書を用いたTLS通信を行うことによって、PCとWebサーバ間の通信データを暗号化するとともに利用者を認証することができるようになります。
TLS通信では、必須のサーバ認証とは別にオプションでクライアント認証を行うこともできます。利用者PCと通信を行うWebサーバは、利用者個人のディジタル証明書に付された認証局の署名を検証することで、ディジタル証明書の正当性を確認します。ディジタル証明書が正当なものならば、利用者(クライアント)の真正性が証明されます。
平成30年秋期問40 TLS通信で期待できるセキュリティ効果|応用情報技術者試験.com