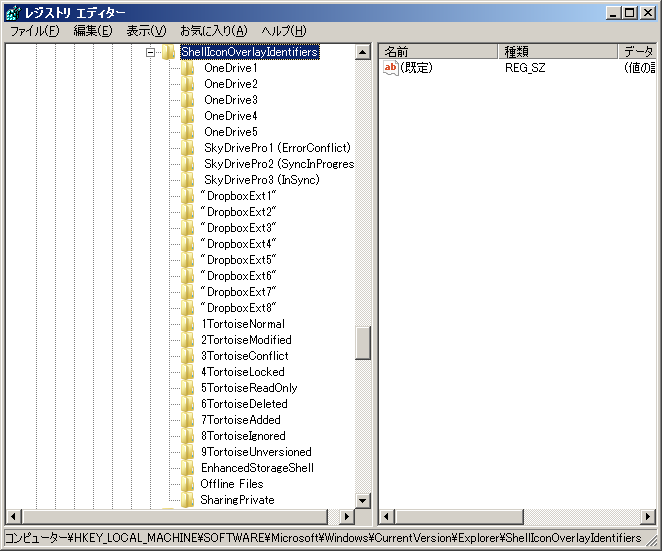
Windowsのオーバーレイが表示されない時の対応
事象
Windowsのエクスプローラで表示されるマークみたいなのが「オーバーレイ」ですが、アプリをたくさん使っていると表示されなくなることがあります。
なぜなら、「オーバーレイ」は「15個」という上限があり、上限値を超えると超えた分は表示されなくなるからです。
しかもWindows自体が「4個」くらい使っているので、その残りをアプリで取り合うことになります。
「オーバーレイ」を使うアプリは「Skype」「DropBox」「TortoiseSVN」・・・と結構あります。
人によって、別に「オーバーレイ」がなくてもいいアプリもあれば、あった方が使いやすいアプリもあります。
対応 : いらない「オーバーレイ」を削除する
間違えるとパソコンが壊れるかもしれないので、設定は自己責任でやりましょう。



誰かの決断で誰かの運命も決まるみたいな感じが関数従属
- 前回の勉強内容
- 勉強のきっかけになった過去問
- 関数従属とは、1つの項目値が決まるともう1つの項目値も決まる関係のことです。
- 部分関数従属とは、候補キーの1つの項目値が決まると他の項目値も決まる関係のことです。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった過去問
関係R(A,B,C)の候補キーが{A,B}と{A,C}であり,{A,B}→C及びC→Bの関数従属性があるとき,関係Rはどこまでの正規形の条件を満足しているか。
- 第1正規形
- 第2正規形
- 第3正規形
- ボイス・コッド正規形
出典 : データベーススペシャリスト試験 令和3年秋期 午前Ⅱ 問3
関数従属とは、1つの項目値が決まるともう1つの項目値も決まる関係のことです。
誰かの決断で誰かの運命も決まるみたいな感じがします。
次の表において,属性Aに対して関数従属性を満たしている属性はどれか。
A B C D E 100 3100 10 東京都 2006年5月 100 1200 60 東京都 2006年11月 100 1200 20 東京都 2007年1月 200 1100 10 大阪府 2006年6月 200 2200 20 大阪府 2006年10月 300 3200 10 北海道 2006年7月 300 1200 30 北海道 2006年9月 400 4030 40 東京都 2006年8月 400 2200 40 東京都 2006年9月 400 1200 20 東京都 2006年12月 出典 : 基本情報技術者試験 平成18年秋期 午前問60
上記過去問の場合、「A列の値」によって「D列の値」が決まっています。
例えば「A列が100」と決まると「D列が東京都」に決まります。
| A | D |
|---|---|
| 100 | 東京都 |
| 200 | 大阪府 |
| 300 | 北海道 |
| 400 | 東京都 |
こんな関係を「DはAに関数従属している」といい「A->D」と書きます。
六つのタプルから成る関係Rの単一の属性間において成立する全ての関数従属性を挙げたものはどれか。ここで,X→Yは,XがYを関数的に決定することを表す。
R
A B C 300 阿部商店 3 300 阿部商店 3 400 鈴木商店 2 400 鈴木商店 2 500 鈴木商店 1 500 鈴木商店 1
- A→B
- A→C,C→A
- (正解)A→B,A→C,C→A,C→B
- A→B,A→C,B→C,C→A,C→B
上記過去問では、「A列の値」によって「B列の値」が決まっています(A->B)。
| A | B |
|---|---|
| 300 | 阿部商店 |
| 400 | 鈴木商店 |
| 500 | 鈴木商店 |
「A列の値」によって「C列の値」も決まっちゃいます(A->C)。
しかも、逆に「C列の値」によって「A列の値」が決まるとも考えることができます(C->A)。
| A | C |
|---|---|
| 300 | 3 |
| 400 | 2 |
| 500 | 1 |
よく見ると「C列の値」によって「B列の値」が決まっています(C->B)。
| B | C |
|---|---|
| 阿部商店 | 3 |
| 鈴木商店 | 2 |
| 鈴木商店 | 1 |

候補キーとは、レコードを一意にすることができる項目の組み合わせです。
主キーの候補になるキーです。
関係R(A,B,C,D,E,F)において,関数従属A→B,C→D,C→E,{A,C}→Fが成立するとき,関係Rの候補キーはどれか。
ア. A イ. C ウ. (正解){A,C} エ. {A,C,E}
出典 : 応用情報技術者試験 平成26年秋期 午前問26
「A→B」なのでAでBは決まります。
「C→D,C→E」なのでCでDとEは決まります。
そして「{A,C}→F」もあるので{A,C}でBとDとEとFがきまるので、{A,C}でレコードを一意にすることができます。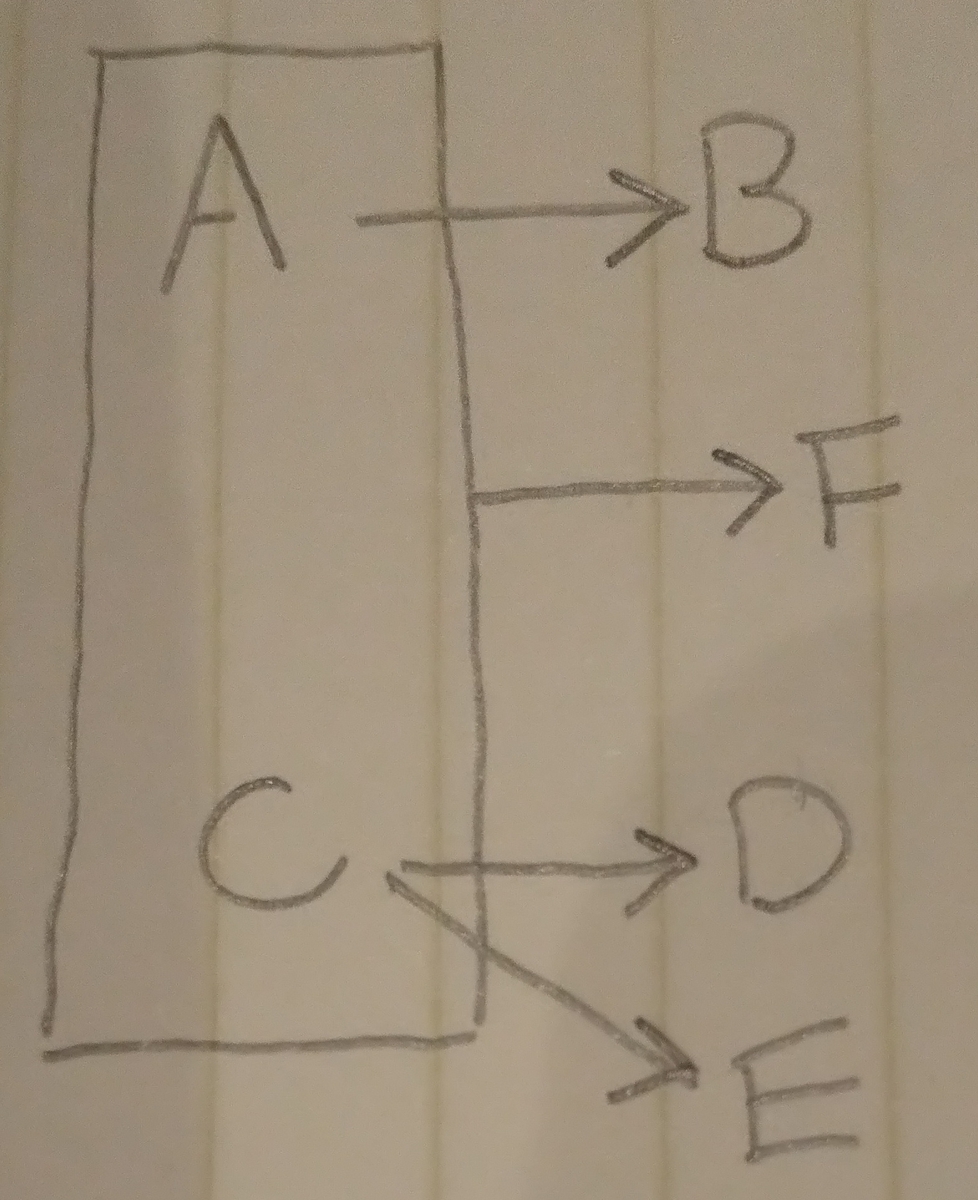
関係モデルの候補キーの説明のうち,適切なものはどれか。
- 関係Rの候補キーは関係Rの属性の中から選ばない。
- 候補キーは主キーの中から選ぶ。
- (正解)タプルごとに,候補キーの値は異なる。
- 一つの関係に候補キーが複数あってはならない。
出典 : データベーススペシャリスト試験 平成24年春期 午前Ⅱ 問6
「レコード(タプル)を一意にする」ので、候補キーの具体的な値はため異なります。
関係Rは属性{A,B,C,D,E}から成り,関数従属性 A→{B,C},{C,D}→E が成立する。これらの関数従属から決定できるRの候補キーはどれか。
ア. {A,C} イ. {A,C,D} ウ. (正解){A,D} エ. {C,D}
出典 : データベーススペシャリスト試験 平成27年春期 午前Ⅱ 問3

候補キーでレコードを一意にすることができるので、候補キーのないテーブルを外部キーの参照先とすることはできません。
関係モデルにおける外部キーに関する記述のうち,適切なものはどれか。
- 外部キーの値は,その関係の中で一意でなければならない。
- 外部キーは,それが参照する候補キーと比較可能でなくてもよい。
- 参照先の関係に,参照元の外部キーの値と一致する候補キーが存在しなくてもよい。
- (正解)一つの関係に外部キーが複数存在してもよい。
出典 : 情報セキュリティスペシャリスト試験 平成26年春期 午前Ⅱ 問21
推移的関数従属とは、1つの項目値が決まると玉突き的に他の項目値も決まる関係のことです。
関係R(A,B,C,D,E,F)において,次の関数従属が成立するとき,候補キーとなるのはどれか。
〔関数従属〕
A→B,A→F,B→C,C→D,{B,C}→E,{C,F}→A
ア. B イ. {B,C} ウ. (正解){B,F} エ. {B,D,E}
出典 : 応用情報技術者試験 平成27年秋期 午前問28
上記過去問では、「A列の値」によって「B列の値」が決まって、「B列の値」が決まったから「C列の値」も決まっています。
「A->B->C」な感じです。
しかし、「{C,F}->A」はあるけど「B->A」はなので、逆流的に「B列の値」が決まっても「A列の値」は決まりません。
こんな関係を「CはAに推移的関数従属ししている」といいます。

部分関数従属とは、候補キーの1つの項目値が決まると他の項目値も決まる関係のことです。
| 部署ID | 部署名 | 部員名 |
|---|---|---|
| 1 | 森 | くま |
| 1 | 森 | きつね |
| 2 | 海 | くらげ |
| 2 | 海 | 鯛 |
| 2 | 海 | くじら |
上記の表の場合、候補キーは{部署ID, 部員名}です。
そして、候補キーの1つである「部署ID」の値が決まると「部署名」の値も決まります。
こんな状態を「部分関数従属」といいます。
「繰り返す項目をなくした状態」だけの「第1正規形」から「部分関数従属を排除した状態」が「第2正規形」となります。
ponsuke-tarou.hatenablog.com
次回の勉強内容
勉強中・・・
ACID特性の隔離性で安全なトランザクション処理をしよう
前回の勉強内容
勉強のきっかけになった問題
トランザクションの隔離性水準のうち,次の(1),(2)に該当するSQLの指定はどれか。
(1)対象の表のダーティリードは回避できる。
(2)一つのトランザクション中で,対象の表のある行を2回以上参照する場合,1回目の読込みの列値と2回目以降の読込みの列値が同じであることが保証されない。
- READ COMMITTED
- READ UNCOMMITTED
- REPEATABLE READ
- SERIALIZABLE
出典 : データベーススペシャリスト試験 令和3年秋期 午前Ⅱ 問7

「ACID特性」とは、トランザクション処理で守らないといけない4つの性質のことです。
トランザクションが,データベースに対する更新処理を完全に行うか,全く処理しなかったのように取り消すか,のどちらかの結果になることを保証する特性はどれか。
- 一貫性(consistency)
- 原子性(atomicity)
- 耐久性(durability)
- 独立性(isolation)
トランザクション処理に求められる特性の頭文字をとって「ACID特性」といいます。
| 特性 | 日本語 | 説明 |
|---|---|---|
| Atomicity | 原子性、不可分性 | トランザクションの処理が「すべて実行される」か「全く実行されない」のどちらかの結果になる |
| Consistency | 一貫性、整合性 | テーブルの定義を満たすようにトランザクションが実行されることで、データの破損やエラーが起きた場合でもデータの整合性が保たれる |
| Isolation | 独立性、隔離性 | 複数のトランザクションが同時進行しても干渉したり、他の処理の影響を受けない |
| Durability | 耐久性、永続性 | 完了したトランザクションの結果は記録されることで、システム障害が発生しても失われない |
隔離性が満たされないと発生する残念な事象
「ACID特性」にある「隔離性」は、「他の処理に影響を与えない」という特性です。
| 事象 | 他の言い方 | 意味 |
|---|---|---|
| ダーティリード | 未コミット読み取り、非コミット読み取り | 処理中の未確定データを他のトランザクションが読み込んでしまうこと |
| アンリピータブルリード | 反復不能読み取り、ファジーリード | 同じデータを複数回読み込んだ場合、他のトランザクションが内容を更新・削除したことにより途中で内容が変わること |
| ファントムリード | 幻像読み取り、仮読み取り | 同じデータを複数回読み込んだ場合、他のトランザクションが内容を追加したことにより途中でレコードが増えること |
試験問題で具体的な例を考えます。
データベースのトランザクションT2の振る舞いのうち,ダーティリード(dirty read)に関する記述はどれか。
- トランザクションT1が行を検索し,トランザクションT2がその行を更新する。その後T1は先に読んだ行を更新する。その後にT2が同じ行を読んでも,先のT2による更新が反映されない値を得ることになる。
- トランザクションT1が行を更新し,トランザクションT2がその行を検索する。その後T1がロールバックされると,T2はその行に存在しない値を読んだことになる。
- トランザクションT2がある条件を満たす行を検索しているときに,トランザクションT1がT2の検索条件を満たす行を挿入する。その後T2が同じ条件でもう一度検索を実行すると,前回は存在しなかった行を読むことになる。
- トランザクションT2が行を検索し,トランザクションT1がその行を更新する。その後T2が同じ行を検索した場合,同じ行を読んだにもかかわらず,異なる値を得ることになる。
出典 : データベーススペシャリスト試験 平成26年春期 午前Ⅱ問14
「ダーティリード」は「未確定データを他のトランザクションが読み込んでしまうこと」なので以下の流れになる「2.」が正解です。
- トランザクションT1が行を更新し,
- -> 未確定のデータができる
- トランザクションT2がその行を検索する。
- -> 未確定データを他のトランザクションが読み込む
- その後T1がロールバックされると,T2はその行に存在しない値を読んだことになる。

隔離性水準とは、トランザクションの独立性の指標のことです。
「隔離性が満たされないと発生する残念な事象」を防ぐための「他のトランザクションへ影響を与えない度合い」が、隔離性水準です。
SQLでトランザクションの隔離性水準を READ COMMITTED に指定したときに発生する状態はどれか。
- ダーティリードとアンリピータブルリードとファントムリードが発生する。
- ダーティリードとアンリピータブルリードは発生しないが,ファントムリードが発生する。
- ダーティリードは発生しないが,アンリピータブルリードとファントムリードが発生する。
- ダーティリードもアンリピータブルリードもファントムリードも発生しない。
出典 : データベーススペシャリスト試験 平成24年春期 午前Ⅱ問15
| 隔離性水準 | 参照時 のロック |
更新時 のロック |
ダーティリード の発生 |
アンリピータブル リード の発生 |
ファントムリード の発生 |
|---|---|---|---|---|---|
| READ UNCOMMITTED | なし | 更新時に 占有ロック |
o | o | o |
| READ COMMITTED | なし | トランザクション開始時 に占有ロック |
x | o | o |
| REPEATABLE READ | 参照時に 共有ロック |
トランザクション開始時 に占有ロック |
x | x | o |
| SERIALIZABLE | トランザクション開始時 に占有ロック |
トランザクション開始時 に占有ロック |
x | x | x |
いろんなところの隔離性水準
「SERIALIZABLEにすれば何の問題もない!」ように見えますが、PostgreSQLでは「READ COMMITTED」、MySQLでは「REPEATABLE READ」がデフォルトになっています。
PostgreSQLではリードコミッティドがデフォルトの分離レベルです。 トランザクションがこの分離レベルを使用すると、SELECT問い合わせ(FOR UPDATE/SHARE句を伴わない)はその問い合わせが実行される直前までにコミットされたデータのみを参照し、まだコミットされていないデータや、その問い合わせの実行中に別の同時実行トランザクションがコミットした更新は参照しません。
13.2. トランザクションの分離
- REPEATABLE READ
これが InnoDB のデフォルトの分離レベルです。 同じトランザクション内の Consistent reads は、最初の読取りによって確立された snapshot を読み取ります。 つまり、同じトランザクション内で複数のプレーン (非ロック) SELECT ステートメントを発行すると、これらの SELECT ステートメントも互いに一貫性が保たれます。
MySQL :: MySQL 8.0 リファレンスマニュアル :: 15.7.2.1 トランザクション分離レベル
PythonのフレームワークであるDjangoでは、MySQLを使う場合に「READ COMMITTED」が使われるようになっていました。
引用元 : https://github.com/django/django/blob/8aa83464664938367a425f011a7df5663a955d09/django/db/backends/mysql/base.py#L237C15-L237C15
# django.db.backends.mysql.base.DatabaseWrapper#get_connection_params
# ↓指定がなければ「READ COMMITTED」になる
isolation_level = options.pop("isolation_level", "read committed")
if isolation_level:
isolation_level = isolation_level.lower()なぜ、DjangoはMySQLのデフォルトである「REPEATABLE READ」を使わないのでしょう?答えはDjangoのドキュメントサイトにありました。
頑張って訳すと「REPEATABLE READでデータ損失が発生する可能性があり、データベースのリレーショナル整合性で問題があっても検知できないかもしれないから」みたいなことが理由のようです。
Data loss is possible with repeatable read. In particular, you may see cases where get_or_create() will raise an IntegrityError but the object won’t appear in a subsequent get() call.
Databases | Django documentation | Django
隔離性水準は、バランスが大切です。
隔離性水準を高めれば、「不確実なデータは減る」けれど「ロック待ちなどで実行できる処理も減る」のです。
トランザクションの隔離性水準を高めたとき,不整合なデータを読み込むトランザクション数と,単位時間に処理できるトランザクション数の傾向として,適切な組合せはどれか。
選択肢 不整合なトランザクションを読み込む
トランザクション数単位時間に処理できる
トランザクション数ア 増える 増える イ 増える 減る ウ 減る 増える エ 減る 減る 出典 : データベーススペシャリスト試験 平成30年春期 午前Ⅱ問17
なので、「隔離性水準」と「パフォーマンス」はバランスよく設定できるようになるといいですね。
経験豊富なユーザーは、実際にトランザクションが互いに干渉しないと確信できれば、パフォーマンスと並列性の向上の代わりに保護の低下をトレードオフするように分離レベルを調整できます。
MySQL :: MySQL 8.0 リファレンスマニュアル :: MySQL 用語集

最後に「勉強のきっかけになった問題」を考えます。
「対象の表のある行を2回以上参照する場合,1回目の読込みの列値と2回目以降の読込みの列値が同じであることが保証されない」ということは「アンリピータブルリードが発生する」ということになります。
なので「ダーティリードは発生しない」かつ「アンリピータブルリードが発生する」ということなので答えは「READ COMMITTED」になります。
次回の勉強内容
等価結合の仲間たち
前回の勉強内容
勉強のきっかけになった問題
関係R,Sの等結合演算は,どの演算によって表すことができるか。
- 共通
- 差
- 直積と射影と差
- 直積と選択
出典 : 平成30年 春期 データベーススペシャリスト試験 午前Ⅱ 問9
等価結合は、同じ値のカラムで結合します。
2つのテーブルにおいて、結合に使うカラムが同じ値の場合に結合を行うのが「等価結合」です。
等価結合には、結合方法の違いでいくつか種類があります。
| 結合 | カラム指定 | 指定カラムの表示 |
|---|---|---|
| 等結合:ON | 必要 | まとめない |
| USING | 必要 | まとめる |
| 自然結合:NATURAL JOIN | 不要 | まとめる |
等結合:ON
等結合は、「=だけ」を使ってテーブルをくっつける方法です。
ON 結合は、すべてのテーブルのすべてのカラムを選択します。
MySQL :: MySQL 8.0 リファレンスマニュアル :: 13.2.10.2 JOIN 句
結合に使われたカラムを2テーブル分2つ表示します。
"商品"表と"納品"表を商品番号で等結合した結果はどれか。
商品
商品番号 商品名 価格 S01 ボールペン 150 S02 消しゴム 80 S03 クリップ 200 納品
商品番号 顧客番号 納品数 S01 C01 10 S01 C02 30 S02 C02 20 S02 C03 40 S03 C03 60
ア. 商品番号 商品名 価格 顧客番号 納品数
----------------------------------------------
S01 ボールペン 150 C01 10
S02 消しゴム 80 C02 30
S03 クリップ 200 C03 20
イ. 商品番号 商品名 価格 商品番号 顧客番号 納品数
----------------------------------------------
S01 ボールペン 150 S01 C01 10
S02 消しゴム 80 S02 C02 30
S03 クリップ 200 S03 C03 20
ウ. 商品番号 商品名 価格 顧客番号 納品数
----------------------------------------------
S01 ボールペン 150 C01 10
S01 ボールペン 150 C02 30
S02 消しゴム 80 C02 20
S02 消しゴム 200 C03 40
S03 クリップ 200 C03 60
エ. 商品番号 商品名 価格 商品番号 顧客番号 納品数
----------------------------------------------
S01 ボールペン 150 S01 C01 10
S01 ボールペン 150 S01 C02 30
S02 消しゴム 80 S02 C02 20
S02 消しゴム 200 S02 C03 40
S03 クリップ 200 S03 C03 60
出典 : 平成27年 春期 データベーススペシャリスト試験 午前Ⅱ 問10
「"商品"表と"納品"表を商品番号で等結合」というわけで、「商品番号」を「=だけ」を使ってテーブルをくっつけています。
mysql> SELECT * FROM 商品 INNER JOIN 納品 ON 商品.商品番号=納品.商品番号; +--------------+-----------------+--------+--------------+--------------+-----------+ | 商品番号 | 商品名 | 価格 | 商品番号 | 顧客番号 | 納品数 | +--------------+-----------------+--------+--------------+--------------+-----------+ | S01 | ボールペン | 150 | S01 | C01 | 10 | | S01 | ボールペン | 150 | S01 | C02 | 30 | | S02 | 消しゴム | 80 | S02 | C02 | 20 | | S02 | 消しゴム | 80 | S02 | C03 | 40 | | S03 | クリップ | 200 | S03 | C03 | 60 | +--------------+-----------------+--------+--------------+--------------+-----------+ 5 rows in set (0.00 sec)
USING
ON句を使うと「ON table1.col=table2.col」とカラム名を2回指定しますが、
USING句を使うと「USING (col)」とカラム名の指定が1回ですみます。
ただし、指定できるのは「同じ名前のカラム」になります。
SELECT * の展開に対してどのカラムを表示するかの判定に関しては、この 2 つの結合は意味的に同一ではありません。 USING 結合が対応するカラムの合体した値を選択するのに対して、ON 結合は、すべてのテーブルのすべてのカラムを選択します。
MySQL :: MySQL 8.0 リファレンスマニュアル :: 13.2.10.2 JOIN 句
結合に使われたカラムは冗長なので1つだけ表示します。
mysql> SELECT * FROM 商品 INNER JOIN 納品 USING (商品番号); +--------------+-----------------+--------+--------------+-----------+ | 商品番号 | 商品名 | 価格 | 顧客番号 | 納品数 | +--------------+-----------------+--------+--------------+-----------+ | S01 | ボールペン | 150 | C01 | 10 | | S01 | ボールペン | 150 | C02 | 30 | | S02 | 消しゴム | 80 | C02 | 20 | | S02 | 消しゴム | 80 | C03 | 40 | | S03 | クリップ | 200 | C03 | 60 | +--------------+-----------------+--------+--------------+-----------+ 5 rows in set (0.00 sec)
自然結合:NATURAL JOIN
自然結合は、結合条件に使うカラムを指定せず、「同じカラム名かつ同じ型」のカラムが自動で選ばれて結合される方法です。
NATURAL 結合の冗長カラムは表示されません。
MySQL :: MySQL 8.0 リファレンスマニュアル :: 13.2.10.2 JOIN 句
結合に使われた「同じカラム名かつ同じ型」のカラムは、USING句と同じく1つだけ表示します。
関係“履修”と関係“担当”を自然結合した結果はどれか。
履修
学生 科目 山田太郎 情報処理 山田太郎 代数 加藤花子 情報処理 担当
科目 教官 情報処理 鈴木一郎 代数 斎藤正樹 ア.
学生 科目 教官 山田太郎 情報処理 鈴木一郎 山田太郎 代数 斎藤正樹 加藤花子 情報処理 鈴木一郎 イ.
履修.学生 履修.科目 担当.科目 担当.教官 山田太郎 情報処理 情報処理 鈴木一郎 山田太郎 代数 代数 斎藤正樹 加藤花子 情報処理 情報処理 鈴木一郎 ウ.
履修.学生 履修.科目 担当.科目 担当.教官 山田太郎 情報処理 代数 斎藤正樹 山田太郎 代数 情報処理 鈴木一郎 加藤花子 情報処理 代数 斎藤正樹 エ.
履修.学生 履修.科目 担当.科目 担当.教官 山田太郎 情報処理 情報処理 鈴木一郎 山田太郎 情報処理 代数 斎藤正樹 山田太郎 代数 情報処理 鈴木一郎 山田太郎 代数 代数 斎藤正樹 加藤花子 情報処理 情報処理 鈴木一郎 加藤花子 情報処理 代数 斎藤正樹 出典 : 平成22年 春期 データベーススペシャリスト試験午前Ⅱ 問13
mysql> select * from 履修 natural join 担当; +--------------+--------------+--------------+ | 科目 | 学生 | 教官 | +--------------+--------------+--------------+ | 情報処理 | 山田太郎 | 鈴木一郎 | | 代数 | 山田太郎 | 斎藤正樹 | | 情報処理 | 加藤花子 | 鈴木一郎 | +--------------+--------------+--------------+ 3 rows in set (0.00 sec)

演算
演算は、「+」「-」などは分かりやすいですが、日本語で書かれるととても分かりにくいです。
| 演算 | 意味 | SQLでは |
|---|---|---|
| 直積 | 全部の掛け合わせ | CROSS JOIN |
| 射影 | カラムを取り出す | SELECT句 |
| 選択 | レコードを取り出す | WHERE句/HAVING句 |

等結合演算は「直積」の結果を「選択」します。
「勉強のきっかけになった問題」を考えます。
「直積結合」の結果から・・・
mysql> select * from 履修 cross join 担当; +--------------+--------------+--------------+--------------+ | 学生 | 科目 | 科目 | 教官 | +--------------+--------------+--------------+--------------+ | 山田太郎 | 情報処理 | 代数 | 斎藤正樹 | | 山田太郎 | 情報処理 | 情報処理 | 鈴木一郎 | | 山田太郎 | 代数 | 代数 | 斎藤正樹 | | 山田太郎 | 代数 | 情報処理 | 鈴木一郎 | | 加藤花子 | 情報処理 | 代数 | 斎藤正樹 | | 加藤花子 | 情報処理 | 情報処理 | 鈴木一郎 | +--------------+--------------+--------------+--------------+ 6 rows in set (0.00 sec)
「選択」をすると・・・
mysql> select * from 履修 cross join 担当 where 履修.科目=担当.科目; +--------------+--------------+--------------+--------------+ | 学生 | 科目 | 科目 | 教官 | +--------------+--------------+--------------+--------------+ | 山田太郎 | 情報処理 | 情報処理 | 鈴木一郎 | | 山田太郎 | 代数 | 代数 | 斎藤正樹 | | 加藤花子 | 情報処理 | 情報処理 | 鈴木一郎 | +--------------+--------------+--------------+--------------+ 3 rows in set (0.01 sec)
「等結合」と同じになります。
mysql> select * from 履修 join 担当 on 履修.科目=担当.科目; +--------------+--------------+--------------+--------------+ | 学生 | 科目 | 科目 | 教官 | +--------------+--------------+--------------+--------------+ | 山田太郎 | 情報処理 | 情報処理 | 鈴木一郎 | | 山田太郎 | 代数 | 代数 | 斎藤正樹 | | 加藤花子 | 情報処理 | 情報処理 | 鈴木一郎 | +--------------+--------------+--------------+--------------+ 3 rows in set (0.00 sec)

次回の勉強内容
結合!Let's JSON!
- 前回の勉強内容
- 勉強のきっかけになった問題
- 結合にはいろんな方法がある
- 自己結合
- 外部結合 : OUTER JOIN
- 内部結合/単純結合 : INNER JOIN / JOIN
- 直積結合/交差結合 : CROSS JOIN
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
"部品"表から,部品名に'N11'が含まれる部品情報(部品番号,部品名)を検索するSQL文がある。このSQL文は,検索対象の部品情報のほか,対象部品に親部品番号が設定されている場合は親部品情報を返し,設定されていない場合はNULLを返す。aに入れる字句はどれか。ここで,実線の下線は主キーを表す。
部品(部品番号,部品名,親部品番号)
〔SQL文〕
SELECT B1.部品番号, B1.部品名,
B2.部品番号 AS 親部品番号, B2.部品名 AS 親部品名
FROM 部品 [ a ]
ON B1.親部品番号=B2.部品番号
WHERE B1.部品名 LIKE ‘%N11%’
- B1 JOIN 部品 B2
- B1 LEFT OUTER JOIN 部品 B2
- B1 RIGHT OUTER JOIN 部品 B2
- B2 LEFT OUTER JOIN 部品 B1
出典 : 平成30年 春期 データベーススペシャリスト試験 午前Ⅱ 問8
結合にはいろんな方法がある
結合にはたくさん種類があります。「〜結合」がたくさんあるんです、しかも「結合」とは別に「連結」すらあります。
試験はよく日本語で書かれるのですが、日頃SQLでしか書かないのでとっても分かりづらいです。
このページでは「MySQL8.0」を使ってSQLを実際に実行してみました。
自己結合
自己結合は、1つのテーブルを2つあるように見立てて結合することです。自分同士をくっつけます。
「勉強のきっかけになった問題」は、1つの部品テーブルを「B1」「B2」の2つあるように見立てて結合しています。
-- ↓自分と ↓自分をJOIN ... FROM 部品 B1 LEFT JOIN 部品 B2 ON B1.親部品番号=B2.部品番号 WHERE ...
外部結合 : OUTER JOIN
外部結合は、くっつけるテーブルの「どちらかにしかないレコード」も取得する方法です。
SQLでは「外部結合」という方法で、結合先のテーブルに対応する値を含む行が存在しなくても、結合元の行をすべて表示させることができます。
独習SQL 第2版(長谷川 裕行 黒石 博明)|翔泳社の本
「勉強のきっかけになった問題」の部品テーブルがこんな感じだった場合で考えます。
mysql> select * from 部品; +--------------+---------------------+-----------------+ | 部品番号 | 部品名 | 親部品番号 | +--------------+---------------------+-----------------+ | P01 | ペンN11 | NULL | | P02 | 修正用品 | NULL | | P03 | 留め具 | NULL | | P04 | メモ用紙N111 | NULL | | S01 | ボールペンN110 | P01 | | S02 | N11消しゴム | P02 | | S03 | クリップM10 | P03 | | S04 | のりN11 | P03 | | S05 | N110付箋 | NULL | +--------------+---------------------+-----------------+ 9 rows in set (0.01 sec)
「勉強のきっかけになった問題」では「対象部品に親部品番号が設定されている場合は親部品情報を返し,設定されていない場合はNULLを返す」ので左に指定される「部品 B1」を全部表示させるために「B1 LEFT OUTER JOIN 部品 B2」が答えになります。
mysql> SELECT B1.部品番号, B1.部品名, B2.部品番号 AS 親部品番号, B2.部品名 AS 親部品名 FROM 部品 B1 LEFT OUTER JOIN 部品 B2 ON B1.親部品番号=B2.部品番号 WHERE B1.部品名 LIKE '%N11%'; +--------------+---------------------+-----------------+--------------+ | 部品番号 | 部品名 | 親部品番号 | 親部品名 | +--------------+---------------------+-----------------+--------------+ | P01 | ペンN11 | NULL | NULL | | P04 | メモ用紙N111 | NULL | NULL | | S01 | ボールペンN110 | P01 | ペンN11 | | S02 | N11消しゴム | P02 | 修正用品 | | S04 | のりN11 | P03 | 留め具 | | S05 | N110付箋 | NULL | NULL | +--------------+---------------------+-----------------+--------------+ 6 rows in set (0.00 sec)
左外部結合 : LEFT OUTER JOIN / LEFT JOIN
「左」に指定するテーブルのレコードを全部取得する方法です。

"社員取得資格"表に対し,SQL文を実行して結果を得た。SQL文のaに入れる字句はどれか。
社員取得資格
社員コード 資格 S001 FE S001 AP S001 DB S002 FE S002 SM S003 FE S004 AP S005 NULL 〔結果〕
社員コード 資格1 資格2
------------------------------
S001 FE AP
S002 FE NULL
S003 FE NULL
〔SQL文〕
SELECT C1.社員コード, C1.資格 AS 資格1, C2.資格 AS 資格2
FROM 社員取得資格 C1 LEFT OUTER JOIN 社員取得資格 C2 [ a ]
- ON C1.社員コード = C2.社員コード AND C1.資格 = 'FE' AND C2.資格 = 'AP' WHERE C1.資格 = 'FE'
- ON C1.社員コード = C2.社員コード AND C1.資格 = 'FE' AND C2.資格 = 'AP' WHERE C1.資格 IS NOT NULL
- ON C1.社員コード = C2.社員コード AND C1.資格 = 'FE' AND C2.資格 = 'AP' WHERE C2.資格 = 'AP'
- ON C1.社員コード = C2.社員コード WHERE C1.資格 = 'FE' AND C2.資格 = 'AP'
出典 : 令和3年 秋期 データベーススペシャリスト試験 午前Ⅱ 問8
-- ①「LEFT OUTER JOIN」なのでC1の全レコードに mysql> SELECT C1.社員コード, C1.資格 AS 資格1 FROM 社員取得資格 C1; +-----------------+---------+ | 社員コード | 資格1 | +-----------------+---------+ | S001 | FE | | S001 | AP | | S001 | DB | | S002 | FE | | S002 | SM | | S003 | FE | | S004 | AP | | S005 | NULL | +-----------------+---------+ 8 rows in set (0.00 sec) -- ②C2の「AP」になるレコードを mysql> SELECT C2.社員コード, C2.資格 AS 資格2 FROM 社員取得資格 C2 WHERE C2.資格 = 'AP'; +-----------------+---------+ | 社員コード | 資格2 | +-----------------+---------+ | S001 | AP | | S004 | AP | +-----------------+---------+ 2 rows in set (0.00 sec) -- ③資格1が「FE」になるレコードだけにくっつけて mysql> SELECT C1.社員コード, C1.資格 AS 資格1, C2.資格 AS 資格2 FROM 社員取得資格 C1 LEFT OUTER JOIN 社員取得資格 C2 ON C1.社員コード = C2.社員コード AND C1.資格 = 'FE' AND C2.資格 = 'AP'; +-----------------+---------+---------+ | 社員コード | 資格1 | 資格2 | +-----------------+---------+---------+ | S001 | FE | AP | | S001 | AP | NULL | | S001 | DB | NULL | | S002 | FE | NULL | | S002 | SM | NULL | | S003 | FE | NULL | | S004 | AP | NULL | | S005 | NULL | NULL | +-----------------+---------+---------+ 8 rows in set (0.00 sec) -- ④資格1が「FE」のレコードだけに絞り込むと〔結果〕になる mysql> SELECT C1.社員コード, C1.資格 AS 資格1, C2.資格 AS 資格2 FROM 社員取得資格 C1 LEFT OUTER JOIN 社員取得資格 C2 ON C1.社員コード = C2.社 員コード AND C1.資格 = 'FE' AND C2.資格 = 'AP' WHERE C1.資格 = 'FE'; +-----------------+---------+---------+ | 社員コード | 資格1 | 資格2 | +-----------------+---------+---------+ | S001 | FE | AP | | S002 | FE | NULL | | S003 | FE | NULL | +-----------------+---------+---------+ 3 rows in set (0.01 sec)
右外部結合 : RIGHT OUTER JOIN / RIGHT JOIN
「右」に指定するテーブルのレコードを全部取得する方法です。

完全外部結合 : FULL OUTER JOIN / FULL JOIN
「左右両方」に指定するテーブルのレコードを全部取得する方法です。

表Rと表Sに対し,SQL文を実行して結果を得るとき,aに入れる字句はどれか。ここで,結果のNULLは値が存在しないことを表す。
R
ID 名称1 1 AAA 2 BBB 3 CCC S
ID 名称2 2 bbb 3 ccc 4 ddd 〔結果〕
ID 名称1 名称2
------------------------------
1 AAA NULL
2 BBB bbb
3 CCC ccc
4 NULL ddd
〔SQL文〕
SELECT [ a ] (R.ID, S.ID) AS ID, 名称1, 名称2 FROM R FULL OUTER JOIN S ON R.ID = S.ID ORDER BY IDア. COALESCE イ. DISTINCT ウ. NULLIF エ. UNIQUE
-- この「FULL JOIN」は、MySQLでは使えません。なので、「LEFT JOIN」「RIGHT JOIN」をくっつけて「FULL JOIN」と同じ結果を取得します。 mysql> SELECT * FROM R LEFT JOIN S ON R.ID = S.ID UNION SELECT * FROM R RIGHT JOIN S ON R.ID = S.ID; +------+---------+------+---------+ | ID | 名称1 | ID | 名称2 | +------+---------+------+---------+ | 1 | AAA | NULL | NULL | | 2 | BBB | 2 | bbb | | 3 | CCC | 3 | ccc | | NULL | NULL | 4 | ddd | +------+---------+------+---------+ 4 rows in set (0.01 sec) --2つある「ID」のうちNULLじゃない方を返却する関数なのでCOALESCEが正解です。日本語で「融合する」で「コウアレス」と読みます。 mysql> SELECT COALESCE(RID,SID) AS ID,名称1,名称2 FROM (SELECT R.ID AS RID,S.ID AS SID,名称1,名称2 FROM R LEFT JOIN S ON R.ID = S.ID UNION SELECT R.ID AS RID,S.ID AS SID,名称1,名称2 FROM R RIGHT JOIN S ON R.ID = S.ID) AS A; +------+---------+---------+ | ID | 名称1 | 名称2 | +------+---------+---------+ | 1 | AAA | NULL | | 2 | BBB | bbb | | 3 | CCC | ccc | | 4 | NULL | ddd | +------+---------+---------+ 4 rows in set (0.00 sec)
内部結合/単純結合 : INNER JOIN / JOIN
内部結合は、くっつけるテーブルの「どっちにもあるレコード」も取得する方法です。

直積結合/交差結合 : CROSS JOIN
直積結合は、くっつけるテーブルの「全部を全組合せ」で取得する方法です。
-- Rテーブルと mysql> SELECT * FROM R; +----+---------+ | ID | 名称1 | +----+---------+ | 1 | AAA | | 2 | BBB | | 3 | CCC | +----+---------+ 3 rows in set (0.01 sec) -- Sテーブルを mysql> SELECT * FROM S; +----+---------+ | ID | 名称2 | +----+---------+ | 2 | bbb | | 3 | ccc | | 4 | ddd | +----+---------+ 3 rows in set (0.00 sec) -- 直積結合すると全組み合わせが取得できる mysql> select * from r cross join s; +----+---------+----+---------+ | ID | 名称1 | ID | 名称2 | +----+---------+----+---------+ | 3 | CCC | 2 | bbb | | 2 | BBB | 2 | bbb | | 1 | AAA | 2 | bbb | | 3 | CCC | 3 | ccc | | 2 | BBB | 3 | ccc | | 1 | AAA | 3 | ccc | | 3 | CCC | 4 | ddd | | 2 | BBB | 4 | ddd | | 1 | AAA | 4 | ddd | +----+---------+----+---------+ 9 rows in set (0.01 sec)

次回の勉強内容
はじめてのReactの環境を作ってみる
- 環境
- Docker Compose version v2.15.1
- Docker version 20.10.22, build 3a2c30b
1. compose.ymlを書く
ファイル名は、これまでdocker-compose.ymlとしていましたが以下の記載があったので、compose.ymlにします
ファイルのデフォルトのパスは compose.yaml (推奨)か compose.yml です。Compose 実装は、下位互換性のために docker-compose.yaml と docker-compose.yml もサポート すべきです。SHOULD 両方のファイルが存在する場合、 Compose 実装は標準である compose.yaml を優先 しなければいけませんMUST 。
Compose Specification(仕様) — Docker-docs-ja 20.10 ドキュメント
以下のように記載されているので、versionは指定しません。
Compose 実装は、 Compose ファイルの検証にあたり、正確なスキームを選ぶためにこの version を使う べきではありませんSHOULD NOT 。そうではなく、 Compose ファイルが設計された時点での最新のスキーマを優先すべきです。
Compose Specification(仕様) — Docker-docs-ja 20.10 ドキュメント
サービス名は「node」、コンテナ名は「reactapp」とします。 コンテナの元になるイメージにはNode.jsを使います。 Node.jsのサイト(https://nodejs.org)でLTSとなっている「18.16.1」(2023-06-29時点)を指定します。
node:
container_name: reactapp
image: node:18.16.1
サービスがボリュームをマウントする場所を指定します。 「reactapp」ディレクトリはこの時点ではありませんが、後で作成します。
volumes:
- ./reactapp:/usr/src/app
コンテナ実行時には後で作るReactプロジェクトのディレクトリに移動してプロジェクトを実行するように指定します。
command: sh -c 'cd reactapp && yarn start'
command はコンテナ イメージによって宣言済み(例: Dockerfile の CMD )のデフォルト コマンドを上書きします。
Compose Specification(仕様) — Docker-docs-ja 20.10 ドキュメント
CMD の主な目的は、コンテナ実行時のデフォルト(初期設定)を指定するためです 。
Dockerfile リファレンス — Docker-docs-ja 20.10 ドキュメント
ポートマッピングは、コンテナ内でNode.jsが使う「3000」をホストの「13000」へマッピングします。
ports:
- '13000:3000'
全体
services:
node:
container_name: reactapp
image: node:18.16.1
volumes:
- ./reactapp:/usr/src/app
command: sh -c 'cd reactapp && yarn start'
ports:
- '13000:3000'
2. Reactのプロジェクトを作成する
コンテナ構築
まずはコンテナを構築します。
使い方: docker-compose build [オプション] [--build-arg key=val...] [サービス...]
docker-compose build — Docker-docs-ja 20.10 ドキュメント
$ docker-compose build node
プロジェクト作成
$ docker-compose run --rm node sh -c 'git config --global user.email "ponsuke@example.com" && git config --global user.name "ponsuke" && npx create-react-app reactapp --template typescript'
上記を実行します。意味は・・・
「docker-compose run」は「サービスに対して1回コマンドを実行する」という意味で「--rm」オプションをつけて「コンテナ実行後に削除」します。
参考 : docker-compose run — Docker-docs-ja 20.10 ドキュメント
そして、「sh -c」を使ってコンテナの中でReactプロジェクトを作成します。
まずは、「git config --global user.email "{メールアドレス}" && git config --global user.name "{ユーザー名}"」でGitのユーザー情報を設定します。
Ractプロジェクトを作成する際にGitのコミットが行われるため、ユーザー情報が必要になるからです。
qiita.com
「npx create-react-app {アプリ名}」でプロジェクトを作ることができます。
参考 : 新しい React アプリを作る – React
「--template typescript」を指定して一緒にTypeScriptを使えるようにします。
参考 : Getting Started | Create React App
# 「コンテナを実行」して「ReactプロジェクトをTypeScriptを合わせて作成」して「コンテナ削除」する $ docker-compose run --rm node sh -c 'git config --global user.email "ponsuke@example.com" && git config --global user.name "ponsuke" && npx create-react-app reactapp --template typescript' [+] Running 1/0 ⠿ Network docker_default Created 0.0s [+] Running 9/9 ⠿ node Pulled 23.9s ⠿ d52e4f012db1 Pull complete 5.8s ⠿ 7dd206bea61f Pull complete 6.6s ⠿ 2320f9be4a9c Pull complete 8.5s ⠿ 6e5565e0ba8d Pull complete 18.3s ⠿ 5f1526a28cf9 Pull complete 18.4s ⠿ 2f0191f7d60a Pull complete 19.8s ⠿ 1104f0e2cc5e Pull complete 20.2s ⠿ 3f3e951e9c53 Pull complete 20.2s Need to install the following packages: create-react-app@5.0.1 Ok to proceed? (y) y npm WARN deprecated tar@2.2.2: This version of tar is no longer supported, and will not receive security updates. Please upgrade asap. Creating a new React app in /usr/src/app/reactapp. Installing packages. This might take a couple of minutes. Installing react, react-dom, and react-scripts with cra-template-typescript... added 1413 packages in 3m 226 packages are looking for funding run `npm fund` for details Initialized a git repository. Installing template dependencies using npm... added 52 packages, and changed 2 packages in 26s 235 packages are looking for funding run `npm fund` for details We detected TypeScript in your project (src/App.test.tsx) and created a tsconfig.json file for you. Your tsconfig.json has been populated with default values. Removing template package using npm... removed 1 package, and audited 1465 packages in 4s 235 packages are looking for funding run `npm fund` for details 6 high severity vulnerabilities To address all issues (including breaking changes), run: npm audit fix --force Run `npm audit` for details. Created git commit. Success! Created reactapp at /usr/src/app/reactapp Inside that directory, you can run several commands: npm start Starts the development server. npm run build Bundles the app into static files for production. npm test Starts the test runner. npm run eject Removes this tool and copies build dependencies, configuration files and scripts into the app directory. If you do this, you can’t go back! We suggest that you begin by typing: cd reactapp npm start Happy hacking! npm notice npm notice New minor version of npm available! 9.5.1 -> 9.8.0 npm notice Changelog: https://github.com/npm/cli/releases/tag/v9.8.0 npm notice Run npm install -g npm@9.8.0 to update! npm notice # こんな感じでディレクトリやファイルができました。 node/reactapp/ ├node_modules/ ├README.md ├public/ |├favicon.ico |├index.html |├logo512.png |├manifest.json |├robots.txt |└logo192.png ├src/ |├index.tsx |├App.tsx |├App.test.tsx |├App.css |├index.css |├setupTests.ts |├reportWebVitals.ts |├react-app-env.d.ts |└logo.svg ├.gitignore ├package-lock.json ├package.json └tsconfig.json
コンテナを起動する
$ docker-compose up -d node [+] Running 1/1 ⠿ Container reactapp Started 7.2s $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 17ae1d5a6c19 node:18.16.1 "docker-entrypoint.s…" 15 seconds ago Up 7 seconds 0.0.0.0:13000->3000/tcp reactapp $ docker-compose logs node reactapp | yarn run v1.22.19 reactapp | $ react-scripts start reactapp | (node:36) [DEP_WEBPACK_DEV_SERVER_ON_AFTER_SETUP_MIDDLEWARE] DeprecationWarning: 'onAfterSetupMiddleware' option is deprecated. Please use the 'setupMiddlewares' option. reactapp | (Use `node --trace-deprecation ...` to show where the warning was created) reactapp | (node:36) [DEP_WEBPACK_DEV_SERVER_ON_BEFORE_SETUP_MIDDLEWARE] DeprecationWarning: 'onBeforeSetupMiddleware' option is deprecated. Please use the 'setupMiddlewares' option. reactapp | Starting the development server... reactapp | reactapp | One of your dependencies, babel-preset-react-app, is importing the reactapp | "@babel/plugin-proposal-private-property-in-object" package without reactapp | declaring it in its dependencies. This is currently working because reactapp | "@babel/plugin-proposal-private-property-in-object" is already in your reactapp | node_modules folder for unrelated reasons, but it may break at any time. reactapp | reactapp | babel-preset-react-app is part of the create-react-app project, which reactapp | is not maintianed anymore. It is thus unlikely that this bug will reactapp | ever be fixed. Add "@babel/plugin-proposal-private-property-in-object" to reactapp | your devDependencies to work around this error. This will make this message reactapp | go away. reactapp | reactapp | Compiled successfully! reactapp | reactapp | You can now view reactapp in the browser. reactapp | reactapp | Local: http://localhost:3000 reactapp | On Your Network: http://172.28.0.2:3000 reactapp | reactapp | Note that the development build is not optimized. reactapp | To create a production build, use npm run build. reactapp | reactapp | webpack compiled successfully reactapp | No issues found.
画面を表示する
compose.ymlでホストのポート「13000」にマッピングしたので、http://localhost:13000/ をブラウザで表示します。

Sambaって何だろう?
ネットワーク上のファイルやプリンタを共有するための決まりをSMBといいます。
「えすえむびー」と呼んで、正式名称は「Server Message Block」です。 主にWindows上で利用されるファイルやプリンタを共有するためのプロトコル(決まり事)です。
LinuxやmacOSなどWindows以外のOSにあるファイルをWindowsからも見られるようにしてくれます。
| OSI参照モデル | プロトコル |
|---|---|
| アプリケーション層 | FTP,SMB |
| プレゼンテーション層 | |
| セッション層 | |
| トランスポート層 | |
| ネットワーク層 | |
| データリンク層 | |
| 物理層 |

SambaはLinuxやUnixでWindowsのファイルサーバみたいに動いてくれるソフトウェアです。
「さんば」と読んで、「SMB」に母音をつけ足して「Samba」というのが名前の由来だそうです。
LinuxやUnixなどWindows以外の環境でWindowsの「ファイルサーバ」「プリンタサーバ」「ドメインコントローラ(アカウントやコンピュータなどの権限や認証を管理する機能)」を実現してくれるのがSambaです。 SambaはGPLというライセンスなので、無料で利用することができます。
SambaはWindowsとの通信に「SMB(Server Message Block)」を使います。 なのでSambaを使うことで、Windows以外のサーバをWindowsから利用できる「ファイルサーバ」にすることができます。

Cloud9でDjangoを使ってRDSに接続するまで
RDSに接続先用のMySQLを作成する
Cloud9の環境を作成する
- AWSのコンソールにログイン > Cloud9 > [Create enviroment]ボタンで環境作成を開始します。
- [Name environment]で項目を入力して[Next step]ボタンを押下します。
- [Name] : 環境の名前
- 今回は「PythonDjango」にしました
- (任意)[Description] : 環境の説明文
- [Name] : 環境の名前
- [Configure settings]で項目を入力して[Next step]ボタンを押下します。
- [Environment type] : 環境タイプで、いずれかのオプションを選択
- 選択値の説明はEC2 環境を作成する - AWS Cloud9参照
- 今回は「Create a new EC2 instance for environment (direct access):環境用の新しいEC2インスタンスを作成する(直接アクセス)」にしました
- [Instance type] : インスタンスタイプを選択
- EC2の料金に関わるので小さめに「t2.micro」を選択しました
- [Platform] : 作成されるAmazon EC2 インスタンスのタイプを選択
- [Cost-saving setting] : コスト削減の設定で、指定した待機時間Cloud9を使っていないと自動でEC2を停止してくれます
- Network settings (advanced)
- [Environment type] : 環境タイプで、いずれかのオプションを選択
- [Review]で内容を確認して[Create environment]ボタンでCloud9の環境を作成します。
- 環境が作成されるとIDEの画面が起動します。

Python環境の設定
- [Preferences] > [Python Support] > [Python version]で「Python3」を設定します。
- [Window] > [New Terminal]でターミナルを起動
- PythonとDjangoのバージョンを確認します。
- Djangoは既にインストールされているはずですが、インストールされていなければ
pip install Djangoでインストールします。
- Djangoは既にインストールされているはずですが、インストールされていなければ
- RDSのMySQLに接続するために「PyMySQL」をインストールします。

# Pythonのバージョン確認 $ python -V Python 3.7.10 # Djangoのバージョン確認 $ python -m django --version 2.0.2 # PyMySQLをインストールする $ pip install PyMySQL Defaulting to user installation because normal site-packages is not writeable Collecting PyMySQL Downloading PyMySQL-1.0.2-py3-none-any.whl (43 kB) |████████████████████████████████| 43 kB 2.3 MB/s Installing collected packages: PyMySQL Successfully installed PyMySQL-1.0.2

Cloud9からRDSへ接続できるように設定する
参考 : AWS Cloud9 環境を作成してAmazon Aurora Serverless MySQL データベースに接続する | DevelopersIO
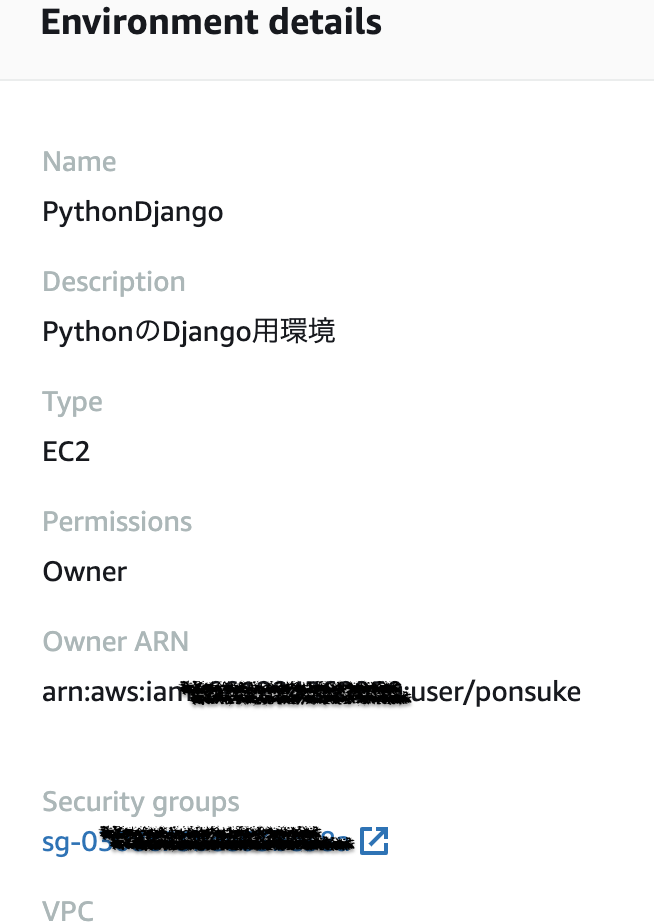
- Cloud9に割り当てられたセキュリティグループを確認します。
- Cloud9のコンソール > [Your environments] > 作成したCloud9の環境名リンク
- [Security groups]に表示されているセキュリティグループIDをメモします。
- Cloud9のコンソール > [Your environments] > 作成したCloud9の環境名リンク
- RDSのセキュリティグループにCloud9のセキュリティグループを設定する
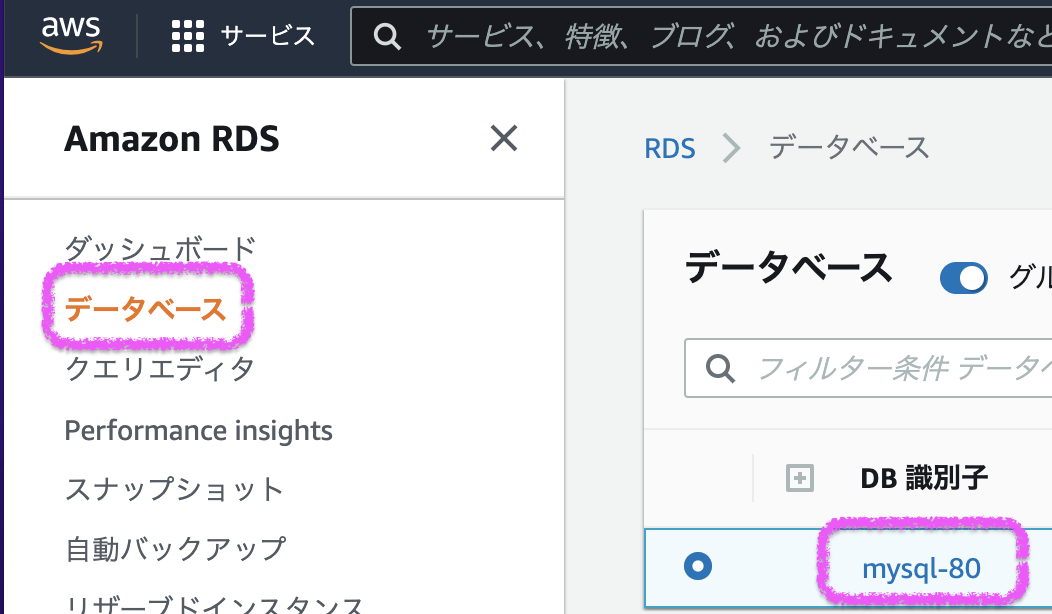
- RDS コンソール(https://console.aws.amazon.com/rds/) > [データベース] > 接続対象の[DB識別子]リンクを押下します。
- [接続とセキュリティ]タブ > [VPC セキュリティグループ]のリンクからセキュリティグループの画面を表示
- [インバウンドルール]タブ > [インバウンドルールを編集]ボタン > [ルールを追加]ボタン
- 以下を設定して[ルールを保存]ボタンで設定を追加します。
- タイプ : MySQL/Aurora
- ソース : Cloud9のセキュリティグループID
- RDS コンソール(https://console.aws.amazon.com/rds/) > [データベース] > 接続対象の[DB識別子]リンクを押下します。
- Cloud9のIDEを起動し、ターミナルでRDSに接続確認します。

# mysqlコマンドはデフォルトでインストールされています(便利だ・・・) $ mysql --version mysql Ver 15.1 Distrib 10.2.38-MariaDB, for Linux (x86_64) using EditLine wrapper # RDSに接続する $ mysql -h {RDSに作ったMySQLのエンドポイント} -P 3306 -u {マスターユーザー} -p Enter password: {マスターユーザーのパスワード} Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 12 Server version: 8.0.28 Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. # 「myDatabase」というデータベースはあるけれど MySQL [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | myDatabase | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.04 sec) MySQL [(none)]> use myDatabase Database changed # まだテーブルは何にもない MySQL [myDatabase]> show tables; Empty set (0.00 sec) MySQL [myDatabase]>

Djangoプロジェクトを作成する
django-admin startproject {プロジェクト名}でプロジェクトを作成します。
RDSへの接続を設定する

manage.py
manage.pyで「PyMySQL」を利用できるよう設定します。
#!/usr/bin/env python import os import sys # PyMySQLを利用できるように以下を追記する import pymysql pymysql.install_as_MySQLdb() # ...省略...
setting.py
setting.pyの[DATABASES]部分を設定します。 「OPTIONS」部分を記載しないとModuleNotFoundError: No module named 'MySQLdb' - Qiitaとなるので注意です。
# ...省略... DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'データベース名', 'USER': 'マスターユーザー名', 'PASSWORD': 'マスターユーザーのパスワード', 'HOST': 'RDSに作ったMySQLのエンドポイント', 'PORT': '3306', 'OPTIONS': { 'init_command': "SET sql_mode='STRICT_TRANS_TABLES'", }, } } # ...省略...
接続確認する
# 接続確認する
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying sessions.0001_initial... OK

はじめてのAmazon Simple Storage Service(S3)
Amazon Simple Storage Service、略してS3
S3は、AWSのストレージサービスです。はじめてS3を使ってみます。 docs.aws.amazon.com
バケットを作成する
- AWS Management Console にサインインし、Amazon S3 コンソール を表示
- [バケットの作成]ボタンを押下して、[バケットの作成]ウィザードを表示して以下を入力
- [バケット名] : バケットの名前付け - Amazon Simple Storage Serviceを参考に任意の文字列を指定
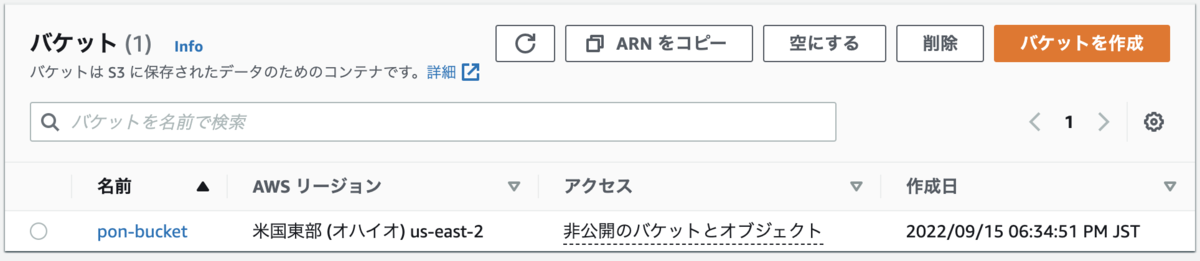
- 今回は
pon-bucketを入力
- 今回は
- [リージョン] : 料金 - Amazon S3 |AWSを参考にバケットを作成するリージョンを選択する
- 今回は「米国東部 (オハイオ)us-east-2」を選択
- [オブジェクト所有者] : 「ACL無効」を選択
- 他の項目は初期値のまま
- [バケット名] : バケットの名前付け - Amazon Simple Storage Serviceを参考に任意の文字列を指定
- [バケットの作成]ボタンでバケットを作成
出来上がり
AWS CLIで接続する
- (インストールしていなかったら)AWS CLIをインストールする
- AWS CLIで接続する
$ aws s3 {コマンド} s3://{バケット名}でS3をいろいろ操作できる- AWS CLIの使い方 : AWS CLI での高レベル (S3) コマンドの使用 - AWS Command Line Interface
# バケットの一覧を見る $ aws s3 ls 2022-09-15 18:34:53 pon-bucket # バケットの中にはまだ何もない $ aws s3 ls s3://pon-bucket # ローカルPCからファイルをアップロードする $ aws s3 cp ~/Downloads/hoge.md s3://pon-bucket upload: ../../Downloads/hoge.md to s3://pon-bucket/hoge.md # アップロードできた $ aws s3 ls s3://pon-bucket 2022-09-15 18:59:54 132 hoge.md
はじめて作ったIAMユーザーでRDSに接続してみる
AWSでアカウントを作るとルートユーザーができますが、このルートユーザーを日頃使わないようにするためにIAMユーザーを作成します。
参考 : AWS アカウントのルートユーザー - AWS Identity and Access Management
IAMユーザーを作成する
- AWSのコンソールにログイン > [IAM] > ユーザー > [ユーザーを追加する]ボタン押下
- 以下を入力 > [次のステップ...]
- [ユーザー名] : ログイン時に[サインイン名]として使いたい文字
- [AWS 認証情報タイプを選択] : 「アクセスキー...」「パスワード...」両方にチェック
- それぞれの意味は以下の「4.」を参照
- [コンソールのパスワード][パスワードのリセットが必要] : 初期値のまま

- [既存のポリシーを直接アタッチ] > [AdministratorAccess]をチェック > [次のステップ...]

権限の設定は自己責任でやりましょう
- [タグの追加 (オプション)]画面では何も設定しない > [次のステップ...]

[確認]画面で内容を確認 > [ユーザーの作成]ボタンを押下してユーザーを作成する - [.csvのダウンロード]ボタンでSecret access keyなどが記載されたCSVファイルをダウンロードする > [閉じる]ボタンでIAMユーザー一覧へ戻る

ダウンロードしたCSVファイルは誰にも見せずにとっても大切に管理しましょう
作ったユーザーを確認する
AWS Management Consoleにログインする
ユーザー作成時に[AWS 認証情報タイプを選択]で「パスワード...」にチェックを入れていないとログインはできません。
- ダウンロードしたCSVファイルの[Console login link]にあるURLを表示する
- ダウンロードしたCSVファイルの[User name]と[Password]でログインする
- パスワード変更画面が表示されるので新しいパスワードを設定する

AWS Management Consoleが表示されたらOK
多要素認証を設定する
作成したIAMユーザーを安全に使えるように多要素認証(Multi-Factor Authentication : MFA)を設定します。 今回は、仮想MFAを使います。
- AWS Management Console > IAM コンソール > [ユーザー] > 作成したユーザー名のリンクを押下
- [認証情報]タブ > [MFAデバイスの割り当て]にある[管理]リンク押下
- [仮想 MFA デバイス]を選択 > [続行] > スマホのGoogle認証システムアプリなどでQRコードを読み取って登録
RDSに接続してみる
さっそく作ったIAMユーザーを使ってみます。今回は、IAM認証を使ってRDSに接続してみます。
RDSを作成する
RDSでMySQLを作ります。 ポイントは、IAMユーザーで接続できるように[データベース認証]に「パスワードと IAM データベース認証」を設定することです。 ponsuke-tarou.hatenablog.com
「IAM データベース認証」が有効になっているかは、「RDS > データベース > {DB インスタンス識別子}リンク > [設定]タブ > IAM DB 認証」とたどっていくと確認できます。

データベースにIAMユーザー用のアカウントを作成する
参考 : IAM 認証を使用したデータベースアカウントの作成 - Amazon Relational Database Service
- mysqlコマンドを使って、マスターユーザー(RDS作成時に作成したユーザー)でRDSに接続します。
- IAMユーザー用のアカウントを作成します。
- AWSAuthenticationPlugin : IAMユーザーの認証をしてくれるプラグイン
- AS 'RDS' : 認証方式を指定
# マスターユーザーでRDSに接続 $ mysql -h {DB インスタンス識別子}...{リージョン}.rds.amazonaws.com -P 3306 -u {マスターユーザー} -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 21 Server version: 8.0.28 Source distribution # IAMユーザー用のアカウント「iam_ponsuke」を作成 mysql> CREATE USER iam_ponsuke IDENTIFIED WITH AWSAuthenticationPlugin AS 'RDS'; Query OK, 0 rows affected (0.31 sec) # 作成されたアカウントを確認 mysql> select host,user,plugin,password_expired,account_locked from mysql.user; +-----------+------------------+-------------------------+------------------+----------------+ | host | user | plugin | password_expired | account_locked | +-----------+------------------+-------------------------+------------------+----------------+ | % | {マスターユーザー} | mysql_native_password | N | N | | % | iam_ponsuke | AWSAuthenticationPlugin | N | N | | localhost | mysql.infoschema | caching_sha2_password | N | Y | | localhost | mysql.session | caching_sha2_password | N | Y | | localhost | mysql.sys | caching_sha2_password | N | Y | | localhost | rdsadmin | mysql_native_password | N | N | +-----------+------------------+-------------------------+------------------+----------------+
一時IAM認証トークンを使ってmysqlコマンドでRDSに接続する
参考 : コマンドラインから IAM 認証を使用して、DB インスタンスに接続する: AWS CLI および mysql クライアント - Amazon Relational Database Service
- (インストールされていなかったら)AWS CLIをインストールする
- 一時IAM認証トークンの生成します。
- 生成されたトークン文字列に「X-Amz-Expires=900」とあるのが気になった・・・有効時間は「900秒=15分」だそうです。
- IAM認証でRDS PostgreSQLに接続してみた | DevelopersIO
- mysqlコマンドでの接続します。
- 毎回、トークン生成して超長い文字列を指定するのは大変なのでよく使う場合は何か考えたほうがよさそうです。
# 一時IAM認証トークンの生成 $ aws rds generate-db-auth-token --hostname {DB インスタンス識別子}...{リージョン}.rds.amazonaws.com --port 3306 --region us-east-2 --username {IAMユーザー用のアカウント} {DB インスタンス識別子}...{リージョン}.rds.amazonaws.com:3306/?Action=connect&DBUser={IAMユーザー用のアカウント}&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAZT5ALBP3CG7P753L%2F20220826%2Fus-east-2%2Frds-db%2Faws4_request&X-Amz-Date=20220826T072830Z&X-Amz-Expires=900&X-Amz-SignedHeaders=ho.... # mysqlコマンドでの接続 $ mysql --host={DB インスタンス識別子}...{リージョン}.rds.amazonaws.com --port=3306 --enable-cleartext-plugin --user={IAMユーザー用のアカウント} --password="{一時IAM認証トークン}" mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 29 Server version: 8.0.28 Source distribution Copyright (c) 2000, 2022, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
ネットワークの未来を切り開くSDNとNFV
- 前回の勉強内容
- 勉強のきっかけになった問題
- SDNは、ネットワーク構成をソフトウェアで管理する技術です。
- OpenFlowは、「経路制御の機能」と「データ転送の機能」を分離する技術です。
- NFVは、ネットワーク機器を仮想化してソフトウェアにしちゃう技術です。
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
ETSI(欧州電気通信標準化機構)が提唱するNFV(Network Functions Virtualisation)に関する記述のうち,適切なものはどれか。
- ONF(Open Networking Foundation)が提唱するSDN(Software-Defined Networking)を用いて,仮想化を実現する。
- OpenFlowコントローラやOpenFlowスイッチなどのOpenFlowプロトコルの専用機器だけを使ってネットワークを構築する。
- ルータ,ファイアウォールなどのネットワーク機能を,汎用サーバを使った仮想マシン上のソフトウェアで実現する。 << 正解
- ロードバランサ,スイッチ,ルータなどの専用機器を使って,VLAN,VPNなどの仮想ネットワークを実現する。
出典 : 令和3年 春期 情報処理安全確保支援士試験 午前Ⅱ 問18

SDNは、ネットワーク構成をソフトウェアで管理する技術です。
ネットワーク(network)の構築や設定をソフトウェア(sftware)で定義(defined)して管理・制御しちゃおうという考え方や技術のことで、英語では「Software Defined Network」、略して「SDN」です。
なんでそんなもんが現れたのか?
近年、サーバもストレージもクラウドで便利に構築できる時代です。
なのにネットワークだけ、物理的なルーターやらスイッチやら通信回線を管理したり設定したりと大変なので、ネットワークもソフトウェアで便利に仮想化しちゃおう!というわけなのです。
ネットワークを構築する機器をソフトウェアで制御して、構成変更したい時もソフトウェアでちゃちゃっとできるようにしようというわけです。
OpenFlowは、「経路制御の機能」と「データ転送の機能」を分離する技術です。
OpenFlowは、「経路制御の機能」と「データ転送の機能」を分離しておいて、ソフトウェアで一括して「経路制御」しちゃう技術です。
SDNを実現した技術の1つです。
OpenFlowを使ったSDN(Software-Defined Networking)の説明として,適切なものはどれか。
- 単一の物理サーバ内の仮想サーバ同士が,外部のネットワーク機器を経由せずに,物理サーバ内部のソフトウェアで実現された仮想スイッチを経由して,通信する方式
- データを転送するネットワーク機器とは分離したソフトウェアによって,ネットワーク機器を集中的に制御,管理するアーキテクチャ << 正解
- プロトコルの文法を形式言語を使って厳密に定義する,ISOで標準化された通信プロトコルの規格
- ルータやスイッチの機器内部で動作するソフトウェアを,オープンソースソフトウェア(OSS)で実現する方式
出典 : 平成29年 春期 応用情報技術者試験 午前問34
「経路制御の機能」はControl Panel、「データ転送の機能」はData Panelというものがやっています。
これまでのネットワーク機器は、Control PanelとData Panelが同居していました。
そして、更新があるたびに各機器を1つ1つ設定していました。
OpenFlowでは、Control PanelとData Panelを分割して、更新するときはControl Panelの部分から指示を出してData Panelを管理します。
Control Panelを入れているのがOpenFlowコントローラで「経路制御の機能」の部分を担当します。
Data Panelを入れているのがOpenFlowスイッチで「データ転送の機能」の部分を担当します。スイッチは物理的なネットワーク機器になります。

ONFは、OpenFlowを標準化して広げようと頑張る団体です。
OpenFlowは、マーティン・カサドさんが作り出しました。
マーティン・カサドさんのOpenFlowのコンセプトに「いいね!」を感じたMicrosoftやGoogle、Facebookなどの企業や組織が集まって「OpenFlowを良くして広げていこう」とういう団体を作りました。
それが、Open Networking Foundation、略して「ONF」です。
特定ベンダーに管理されずにみんなで改善して広めていこう!ということで「オープン」を大切にしているそうです。
ONF(Open Networking Foundation)が標準化を進めているOpenFlowプロトコルを用いたSDN(Software-Defined Networking)の説明として,適切なものはどれか。
- 管理ステーションから定期的にネットワーク機器のMIB(Management Information Base)情報を取得して,稼働監視や性能管理を行うためのネットワーク管理手法
- データ転送機能をもつネットワーク機器同士が経路情報を交換して,ネットワーク全体のデータ転送経路を決定する方式
- ネットワーク制御機能とデータ転送機能を実装したソフトウェアを,仮想環境で利用するための技術
- ネットワーク制御機能とデータ転送機能を論理的に分離し,コントローラと呼ばれるソフトウェアで,データ転送機能をもつネットワーク機器の集中制御を可能とするアーキテクチャ << 正解
出典 : 平成29年 秋期 応用情報技術者試験 午前問35
コントローラがフローテーブルをスイッチへ送って経路を制御します。
OpenFlowを使ったSDN(Software-Defined Networking)の説明として,適切なものはどれか。
- RFIDを用いるIoT(Internet of Things)技術の一つであり,物流ネットワークを最適化するためのソフトウェアアーキテクチャ
- 音楽や動画,オンラインゲームなどの様々なソフトウェアコンテンツをインターネット経由で効率的に配信するために開発された,ネットワーク上のサーバの最適配置手法
- データ転送と経路制御の機能を論理的に分離し,データ転送に特化したネットワーク機器とソフトウェアによる経路制御の組合せで実現するネットワーク技術 << 正解
- データフロー図やアクティビティ図などを活用して,業務プロセスの問題点を発見し改善を行うための,業務分析と可視化ソフトウェアの技術
出典 : 平成29年 春期 基本情報技術者試験 午前問35
OpenFlowのコントローラなので、英語で「OpenFlow Controller」、略して「OFC」です。
このコントローラが、データの転送や宛先書換えなどの振舞いを決めたフローテーブルを作って、ONSへ送ります。
OpenFlowのスイッチは、もらったフローテーブルに基づいてデータの転送や破棄、宛先の書き換えなどを実施します。

NFVは、ネットワーク機器を仮想化してソフトウェアにしちゃう技術です。
ネットワーク機器(netowork)の機能(functuion)を汎用サーバ上で仮想化(virtualization)してソフトウェアっぽくすることで、英語では「Network Functions Virtualization」、略して「NFV」です。
ルータとかスイッチとかを仮想マシンみたいにしちゃうんです。
NFVは、SDNとは違う技術です。
SDNは、ネットワーク機器の構成や接続を仮想化する技術です。
NFVは、ネットワーク機器自体を仮想化する技術です。
似ているけど、違うんです。
ETSI(欧州電気通信標準化機構)によって提案されたNFV(Network Functions Virtualisation)に関する記述として,適切なものはどれか。
- インターネット上で地理情報システムと拡張現実の技術を利用することによって,現実空間と仮想空間をスムーズに融合させた様々なサービスを提供する。
- 仮想化技術を利用し,ネットワーク機能を汎用サーバ上にソフトウェアとして実現したコンポーネントを用いることによって,柔軟なネットワーク基盤を構築する。<< 正解
- 様々な入力情報に対する処理結果をニューラルネットワークに学習させることによって,画像認識や音声認識,自然言語処理などの問題に対する解を見いだす。
- プレースとトランジションと呼ばれる2種類のノードをもつ有向グラフであり,システムの並列性や競合性の分析などに利用される。
出典 : 平成30年 春期 応用情報技術者試験 午前問32

次回の勉強内容
PPPにもいろいろある
- 前回の勉強内容
- 勉強のきっかけになった問題
- シリアル通信は、1本の線で順番にデータを送信します。
- データリンク層は、通信回線の部分で接続された機器間のデータ転送をします。
- LANは、決まった範囲で接続できるネットワークのことです。
- MPLSは、パケットに宛先情報のラベルをくっつけてデータ転送する技術です。
- PPPは、WAN回線やISDN接続でよく使うシリアル通信用のデータリンク層のプロトコルです。
- PPPoEは、有線LANの規格であるEthernet上でPPPをできるようにしたプロトコルです。
- PPTPは、データをカプセル化してPPPを使います。
- まとめ
- 次回の勉強内容
前回の勉強内容
勉強のきっかけになった問題
シリアル回線で使用するものと同じデータリンクのコネクション確立やデータ転送を、LAN上で実現するプロトコルはどれか。
- MPLS
- PPP
- PPPoE << 正解
- PPTP
出典 : 平成31年 春期 情報処理安全確保支援士試験 午前Ⅱ 問19
シリアル通信は、1本の線で順番にデータを送信します。
1本の線で1ビットずつ順番(serial)にデータを送受信する転送していく通信(communication)のことで、英語で「serial communication」、日本語で「直列伝送」ともいいます。
| 通信 | 方式 | いいこと |
|---|---|---|
| シリアル通信 | 1つの線で順番に転送 | 送受信タイミングの同期が不要 |
| パラレル通信 | 複数の線で一気に転送 | 通信速度が速い |
コンピュータ本体に外部記憶装置を繋いで通信する方式である「ATA」をシリアル通信にした仕様は「シリアルATA」といいます。
シリアルATAの説明として,適切なものはどれか。
- PCと周辺機器とを結ぶシリアルインタフェースであり,キーボード,マウス,スピーカ,プリンタ,CD-RWドライブなど多岐に渡る周辺装置を接続する。
- PCと周辺機器とを結ぶシリアルインタフェースであり,磁気ディスク装置,DVDドライブなどの高速な周辺装置を接続する。 <<正解
- PCと周辺機器とを結ぶシリアルインタフェースであり,ルータ又はモデムを接続する。
- PCとディジタルAV機器とを結ぶシリアルインタフェースであり,セットトップボックス,DVDプレーヤなどを接続する。
出典 : 平成21年 秋期 ネットワークスペシャリスト試験 午前Ⅱ 問22
データリンク層は、通信回線の部分で接続された機器間のデータ転送をします。
OSI参照モデルでは、ネットワーク層と物理層の間にある層です。
「データのの変換や調整・優先制御などを行うネットワーク層」と「物理的な通信機器である物理層」との間を取り持って、通信相手の識別やコリジョン検知・回避、フレームの分割や組み立てなどを担当します。
複数のLANを接続するために用いる装置で,OSI基本参照モデルのデータリンク層のプロトコル情報に基づいてデータを中継する装置はどれか。
LANは、決まった範囲で接続できるネットワークのことです。
決まった範囲(local area)で接続できるネットワーク(network)のことで、英語で「Local Area Network」、略して「LAN」、「らん」って読みます。
Ethrnetは、有線LANの規格です。
ケーブルを機器に挿してLAN接続するのが有線LANです。
文字通り線(ケーブル)の有るLANです。
この有線LANを使うときの「物理層」と「データリンク層」の仕様を決めている規格がEthrnetです。
ponsuke-tarou.hatenablog.com

MPLSは、パケットに宛先情報のラベルをくっつけてデータ転送する技術です。
特定のネットワーク内でラベルと呼ばれる短い符号をパケットなどに付与することで高速に転送処理を行う技術です。
ルータでは、普通IPヘッダを見て宛先を判断します。
MPLSを使った場合は、パケットにくっつけたラベルを見て宛先を判断します。
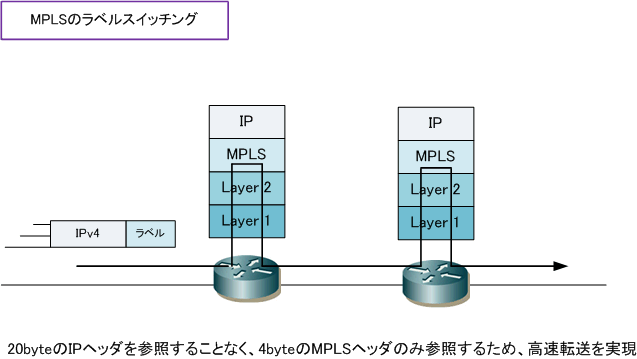
MPLSを使うにはラベル(label)交換(switching)に対応したルータ(router)、英語では「Label Switching Router」、略して「LSR」を使う必要があります。
なぜならば、LSRは専用のプロトコル(LDP : Label Distribution Protocl)でラベル情報を付加したり、参照したりしてくれるからです。
ネットワーク層で働くルータによってラベルがくっつくのならば、MPLSもネットワーク層の技術にも思えるのですが、OSI参照モデルの層にきっちりハマるものでもなくネットワーク層〜データリンク層あたりの技術のようです。
MPLSがレイヤ2とレイヤ3のどちらなのかについては、多少不明瞭な部分もあるが、MPLSは7階層のOSI参照モデルにぴったり収まるものではなく、時にはレイヤ2.5と分類されることもある。
MPLSが生きながらえる理由(上) - MPLSが生きながらえる理由:Computerworld
PPPは、WAN回線やISDN接続でよく使うシリアル通信用のデータリンク層のプロトコルです。
2点間で仮想の経路を確立してデータを送受信できるようにするデータリンク層のプロトコルです。
点(point)から点(point)へ(to)データを送受信するプロトコル(protocol)、英語では「Point to Point Protocol」、略して「PPP」です
PPPには、ユーザ認証機能やエラー処理を行う機能があります。
ponsuke-tarou.hatenablog.com
PPPoEは、有線LANの規格であるEthernet上でPPPをできるようにしたプロトコルです。
イーサネット(ethrnet)上(over)で使えるPPP、英語では「PPP over Ethernet」、略して「PPPoE」です。
PPPのやり方の1つなので、PPPと同じデータリンク層のプロトコルです。
そしてEthernet上で使えるのでLANで使えることになります。
PPTPは、データをカプセル化してPPPを使います。
GREというプロトコルでパケットをカプセル化してPPPでデータを送受信します。
PPPのやり方の1つなので、PPPと同じデータリンク層のプロトコルです。
インターネット上に専用線を構築するVPNであるインターネットVPNで使われます。
ponsuke-tarou.hatenablog.com
まとめ
| 階層 | 階層名 | 役割 | 機器 | プロトコル |
|---|---|---|---|---|
| 第7層 | アプリケーション層 | アプリケーションごと固有の規定 | ゲートウェイ | |
| 第6層 | プレゼンテーション層 | 文字コードなどデータの表現形式の変換 | ゲートウェイ | |
| 第5層 | セッション層 | 通信プログラム間の通信の確立から終了までの管理 | ゲートウェイ | TLS |
| 第4層 | トランポート層 | ノード間のデータ転送の管理 | ゲートウェイ | TCP / UDP |
| 第3層 | ネットワーク層 | ネットワーク機器間のアドレスや経路の管理 | ルータ / L3スイッチ | IP / DHCP / RIP |
| 第2層 | データリンク層 | 直接接続された機器間データフレームの識別や転送 | ブリッジ / L2スイッチ | MAC / PPP / PPPoP / PPTP |
| 第1層 | 物理層 | ビット列の電気信号への変換 | リピータ / ハブ |
参考 : OSI参照モデルとTCP/IPについて - けんのへや

次回の勉強内容
CASBでシャドーITを撲滅して便利なSaaS利用
前回の勉強内容
CASBは、SaaS環境に特化した情報セキュリティを守るサービスです。
組織のメンバーがクラウドサービスを利用する際に一つのポイントを作ってそこでセキュリティを一括管理する考えやサービスのことで、英語では「Cloud Access Security Broker」、略して「CASB」、「きゃすびー」って読みます。

なんでこんな機能が必要になったのでしょう?
SaaSは、アプリケーションソフトウェアの機能を,必要なときだけ利用者に提供するサービスのことです。
シャドーITは、会社が管理できていない社員が勝手に使っているサービスのことです。
Officeアプリを提供する「Microsoft 365」、オンライン会議ができる「Zoom」、Webメールの「Gmail」、グループウェアの「Kintone」と便利で使いやすいSaaSがいっぱいで、使わない手はありません!
そんな、状況下では会社のIT管理者が社員がどんなサービスを使っているか把握しきれない!なんてことが発生します。それがシャドーITです。
許可も管理もされていないと、セキュリティ管理も情報漏洩対策も個人任せになってしまいます。
だからこそ、会社の社員がルールに従って安全にSaaSを使えるように「CASB」が必要になったのです。
CASBの「可視化」「制御」「データセキュリティ」「脅威防御」でSaaSをしっかり管理!
社員がどんなサービスを使っているか「可視化」することで、危ないサービスは使っていないか?禁止しているサービスは使っていないか?業務ファイルのアップロードやダウンロードはどんな状況か?などを分析できるようにします。
セキュリティ対策として,CASB(Cloud Access Security Broker)を利用した際の効果はどれか。
- クラウドサービスプロバイダが,運用しているクラウドサービスに対してDDoS攻撃対策を行うことによって,クラウドサービスの可用性低下を緩和できる。
- クラウドサービスプロバイダが,クラウドサービスを運用している施設に対して入退室管理を行うことによって,クラウドサービス運用環境への物理的な不正アクセスを防止できる。
- クラウドサービス利用組織の管理者が,組織で利用しているクラウドサービスに対して脆弱性診断を行うことによって,脆弱性を特定できる。
- クラウドサービス利用組織の管理者が,組織の利用者が利用している全てのクラウドサービスの利用状況の可視化を行うことによって,許可を得ずにクラウドサービスを利用している者を特定できる。
出典 : 令和3年 春期 情報処理安全確保支援士試験 午前Ⅱ 問11
SaaSとの通信や通知を会社で決めたセキュリテーポリシーでしっかり「制御」します。
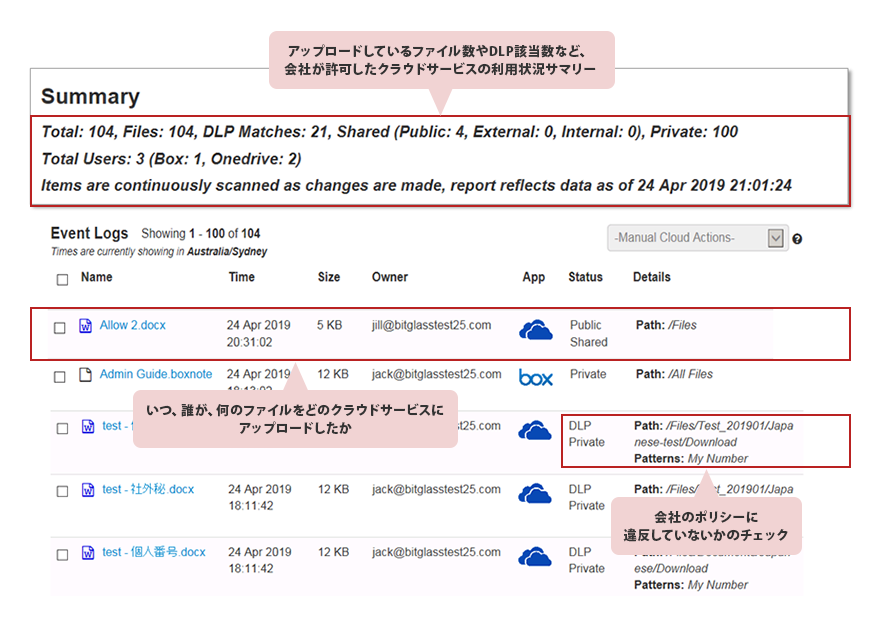
機密情報を定義して「データセキュリティ」を計り情報漏洩を防止します。
マルウェアやランサムウェアを検知・隔離したり、データのコピーや大量データのダウンロードといった異常を検出することで「脅威防御」します。
次回の勉強内容
TLS1.3の暗号スイートは甘くない
- 前回の勉強内容
- TLSは、「公開鍵証明書による認証」「共通鍵暗号による通信暗号化」「ハッシュ関数による改竄検知」をしてくれるプロトコルです。
- TLSで使う暗号アルゴリズムやハッシュ関数、鍵長などの組み合わせを暗号スイートといいます。
- TLS1.3では、TLS1.2より暗号スイートが厳しくなりました。
- 次回の勉強内容
前回の勉強内容
TLSで使う暗号アルゴリズムやハッシュ関数、鍵長などの組み合わせを暗号スイートといいます。
暗号(cipher)ひとそろい(suite)、英語で「Cipher Suites」、日本語で「暗号スイート」です。
この仕様では、TLS 1.3で使用する次の暗号スイートを定義しています。
+------------------------------+-------------+
|Description |Value |
+------------------------------+-------------+
|TLS_AES_128_GCM_SHA256 |{0x13,0x01} |
|TLS_AES_256_GCM_SHA384 |{0x13,0x02} |
|TLS_CHACHA20_POLY1305_SHA256|{0x13,0x03} |
|TLS_AES_128_CCM_SHA256 |{0x13,0x04} |
|TLS_AES_128_CCM_8_SHA256 |{0x13,0x05} |
+------------------------------+-------------+
RFC 8446 - The Transport Layer Security (TLS) Protocol Version 1.3 日本語訳
「TLS_AES_128_GCM_SHA256」や「TLS_AES_128_CCM_SHA256」が暗号スイートのお名前になります。
暗号スイートのお名前にはルールがあります。
TLS1.3からは「TLS_AEAD_HASH 」ルールになりました。
TLS_AEAD_HASH ↑ ↑ ↑ | | 「HASH」にはHKDFで使用されるハッシュアルゴリズムがはい | 「AEAD」にはAEADアルゴリズムがはい 「TLS」は固定の文字 例) TLS_AES_128_GCM_SHA256 => 「TLS_」+「AESの鍵長128でGCMモード」+「ハッシュアルゴリズムはSHA256」
参考 : RFC 8446 - The Transport Layer Security (TLS) Protocol Version 1.3 日本語訳の「B.4. 暗号スイート」
AEADは、「公開鍵証明書による認証」「共通鍵暗号による通信暗号化」「ハッシュ関数による改竄検知」を一気にやってくれます。
関連する(associated)データによる認証(authenticated)付き暗号化(encryptio)、英語では「AuthenticatedEncryption with Associated Data」、略して「AEAD」です、短く日本語で「認証暗号」とも言います。
TLS1.2から採用されました。
そのため、「ハッシュ関数による改竄検知」はAEADでやっちゃいます。
なので、TLS1.3の暗号スイートのお名前にはルールにある「HASH」には、HKDFで使用されるハッシュアルゴリズムが使われます。
HKDFは、HMACベースの鍵導出関数です。
ハッシュ関数(hashed)を使って作られたMACを基礎(base)にした秘密値から鍵(key)を導出(derivation)する関数(function)で、日本語では「HMACベース鍵導出関数」、英語では「Hashed Message Authentication Code(HMAC)-based key derivation function」、略して「HKDF」です。長すぎて覚えられません。
MACといっても世の中いろいろありますが「メッセージ認証コード」の意味のMACです。
ponsuke-tarou.hatenablog.com
暗号アルゴリズムには、ブロック暗号とストリーム暗号があります。
| 方式 | 暗号化の方法 | 特徴 | 対象の暗号アルゴリズム例 |
|---|---|---|---|
| ストリーム暗号 | 平文をビット単位あるいはバイト単位で順次処理する | まとまった単位になるまで待たないので複合が早い | RC4 |
| ブロック暗号 | 特定のビット数のまとまり毎に処理する | ストリーム暗号より安全性の研究が進んでいて広く使われている | DES, 3DES, AES |
ブロック暗号で処理する「特定のビット数のまとまり」をブロック長と言います。
米国NISTが制定した,AESにおける鍵長の条件はどれか。
- 128ビット,192ビット,256ビットから選択する。<<正解
- 256ビット未満で任意に指定する。
- 暗号化処理単位のブロック長より32ビット長くする。
- 暗号化処理単位のブロック長より32ビット短くする。
出典 :平成24年 春期 情報セキュリティスペシャリスト 午前Ⅱ 問4
ブロック暗号で暗号化を繰り返す方法のことを「モード」といいます。
ブロック暗号は「特定のビット数のまとまり」の暗号化を繰り返して処理します。その繰り返し方法のことを「モード」といいます。
| モード名 | 英語 | 繰り返し方 |
|---|---|---|
| ECB | Electronic(電子) CodeBook(符号表) Mode | ブロック毎に暗号化する処理を繰り返す |
| CBC | Cipher(暗号) Block Chaining(連鎖) Mode | 「直前ブロックの暗号文」と「次ブロックの平文」のXOR(排他的論理和)の値を暗号化する |
| CFB | Cipher(暗号)-FeedBack Mode | 「直前ブロックの暗号文をさらに暗号化した値(鍵ストリーム)」と「次ブロックの平文」のXOR(排他的論理和)の値を暗号文とする |
| GCM | Galois/Counter Mode | 改竄検知までやってくれる認証付きのモードらしいのですが難しくてよくわかりません |
ECBのように「ブロック毎に暗号化する」だけだと危険が伴います。
悪い人が大切そうなところのブロックだけ解読しようとして総当たり攻撃をしてくるかもしれません。全部を解読するより特定のブロックだけ解読する方が楽ですからね。
そんな危険を避けるために「直前の暗号文など他の要素を合わせる」というECB以外のモードがあります(上記表に書いてある以外のモードもたくさんあります)。
しかし、CBCの脆弱性が発覚してしまいました。
CBCは、「直前ブロックの暗号文」を使うので一番最初のブロックには「直前ブロックの暗号文」がありません。そこで、1ブロック分のビット列を代わりに用意して使います。
この「1ブロック分のビット列」を初期化(initialization)ベクトル(vector)、英語で「initialization vector」、略して「IV」といいます。
CBCの脆弱性はIVの部分にありました。
SSL プロトコルと TLS プロトコルには、CBC モードで選択平文攻撃を受ける脆弱性が存在します。
SSL プロトコルと TLS プロトコルが CBC モードで動作する際、初期化ベクトル (IV) の決定方法に問題があり、選択平文攻撃を受ける脆弱性が存在します。
JVNDB-2011-002305 - JVN iPedia - 脆弱性対策情報データベース

TLS1.3では、TLS1.2より暗号スイートが厳しくなりました。
TLSでは、暗号スイートにそれぞれ何を使うかサーバとクライアントで合意してから通信を開始します。
セキュリティの強化により暗号スイートで、TLS1.2で使えたけれどTLS1.3で非推奨になったものがいくつかあります。
| 技術分類 | 非推奨になったもの | 残念なこと |
|---|---|---|
| 暗号アルゴリズム | RC4 | TLS プロトコルおよび SSL プロトコルで使用される RC4 アルゴリズムにおけるストリームの最初のバイトへの平文回復攻撃の脆弱性 - JVN |
| 暗号アルゴリズム | DES | TLS プロトコルなどの製品で使用される DES および Triple DES 暗号における平文のデータを取得される脆弱性 - JVN |
| 暗号アルゴリズム | AES-CBC | AEADでないCBC モードは非推奨になった |
| ハッシュ関数 | MD5 | コリジョン攻撃への脆弱性 |
| ハッシュ関数 | SHA-1 | SHA-1の安全性低下について - CRYPTREC |
TLS1.3は、RFC8446で規格化されて2018年に公開されました。
参考 : RFC 8446 - The Transport Layer Security (TLS) Protocol Version 1.3 日本語訳
TLS1.3の暗号スイートに関する説明のうち,適切なものはどれか。
- TLS1.2で規定されている共通鍵暗号AES-CBCを必須の暗号アルゴリズムとして継続利用できるようにしている。
- Wi-Fiアライアンスにおいて規格化されている。
- サーバとクライアントのそれぞれがお互いに別の暗号アルゴリズムを選択できる。
- 認証暗号アルゴリズムとハッシュアルゴリズムの組みで構成されている。 << 正解
出典 : 令和3年 秋期 情報処理安全確保支援士試験 午前Ⅱ 問17
ダウングレード攻撃は、いまいちな暗号スイートを無理やり使わせることで盗み読みをします。
中間者攻撃で輸出グレードである512bit以下の強度が超弱いRSA鍵を使わせる「FREAK」、
DH鍵交換の脆弱性を利用して中間者攻撃で中間者攻撃で輸出グレードである512bit以下の強度が超弱い鍵を使わせる「Logjam」、
脆弱性のあるSSL3.0以下での通信を強制する「バージョンロールバック攻撃」
などがあります。
- 暗号化通信中にクライアントPCからサーバに送信するデータを操作して,強制的にサーバのディジタル証明書を失効させる。
- 暗号化通信中にサーバからクライアントPCに送信するデータを操作して,クライアントPCのWebブラウザを古いバージョンのものにする。
- 暗号化通信を確立するとき,弱い暗号スイートの使用を強制することによって,解読しやすい暗号化通信を行わせる。<< 正解
- 暗号化通信を盗聴する攻撃者が,暗号鍵候補を総当たりで試すことによって解読する。
出典 : 平成29年 春期 情報処理安全確保支援士試験 午前Ⅱ 問2

次回の勉強内容
SAMLを使ったSSO
前回の勉強内容
シングルサインオンにはクッキーやリバースプロキシ、SAMLを使う方法があります。
シングルサインオンは、1度(single)の認証(sign on)で複数のシステムやサービスが使えるようになるので、「Single Sign On」、略してSSOです。
そんなSSOはいくつかの方法で実現されます。
シングルサインオンの説明のうち,適切なものはどれか。
エージェント方式 : Cookieを使うSSOの流れ
- ユーザのログイン時にWebサーバが認証サーバに接続して認証を行う。
- その認証情報をCookieに設定してユーザーに返す。
- 別のWebサーバにアクセスする時は、Webサーバが認証サーバにCookieの情報で認証を行う。
Cookieを使うSSOでは、サービスのWebサーバにエージェントというソフトウェアを設定する必要があります。
そのため「エージェント方式」といいます。
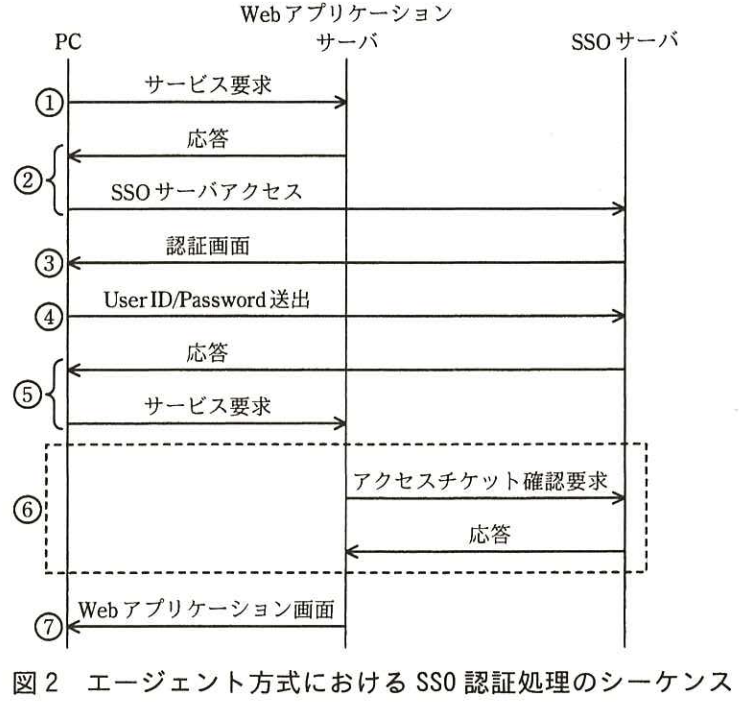
エージェント方式におけるSSO認証処理のシーケンスは,次のとおりである。
- PCからWebアプリケーションサーバに、サービス要求を行う。
- Webアプリケーションサーバ内のエージェントは、サービス要求中のCookieに認証済資格情報(以下、アクセスチケットという)が含まれているか確認する。含まれていなければ,サービス要求はSSOサーバヘ[ イ : リダイレクト ]される。
- SSOサーバからPCに、認証画面を送る。
- PCからSSOサーバに、UserIDとPasswordを送出する。
- SSOサーバは、UserIDとPasswordから利用者のアクセスの正当性を確認したら、アクセスチケットを発行して、Cookieに含めて応答を返す。サービス要求は、Webアプリケーションサーバヘ[ イ : リダイレクト ]される。
- Webアプリケーションサーバ内のエージェントは、SSOサーバにアクセスチケット確認要求を送り、SSOサーバは、確認して応答を返す。
- Webアプリケーションサーバは、6.の応答によって利用者のアクセスの正当性が確認できた場合、Webアプリケーション画面を送出する。
エージェント方式におけるSSO認証処理のシーケンスの1~7を図示すると,図2のようになる。
出典 : 平成27 年秋期 ネットワークスペシャリスト試験 午後Ⅰ

SAMLは、認証情報を交換するためのマークアップ言語です。
安全(security)を判定(assertion)するためのマークアップ言語(markup language)ということで、「Security Assertion Markup Language」、略してSAML(サムル)です。
異なるインターネットドメイン間で認証情報を交換するためのXMLをベースにした規格です。
SAML(Security Assertion Markup Language)の説明として,最も適切なものはどれか。
- Webサービスに関する情報を公開し,それらが提供する機能などを検索可能にするための仕様
- 権限がない利用者による読取り,改ざんから電子メールを保護して送信するための仕様
- ディジタル署名に使われる鍵情報を効率よく管理するためのWebサービスの仕様
- 認証情報に加え,属性情報とアクセス制御情報を異なるドメインに伝達するためのWebのサービス仕様 << 正解
出典 : 令和2年 秋期 情報処理安全確保支援士試験 午前Ⅱ 問2
IdPは、認証情報を管理するサービスです。
認証する(identify)サービスを供給する(provider)ので、「Identify Provider」、略してIdPです。
使うサービスがたくさんあると、その分IDやらパスワードやらの認証情報を管理しなくてはならなくなります。
IdPが、ユーザとサービスの間を仲介してくれることで1つの認証情報でたくさんのサービスを使うことができます。
また、ユーザを管理する人も1か所で管理できるので、ユーザの追加や削除が楽になりますね。
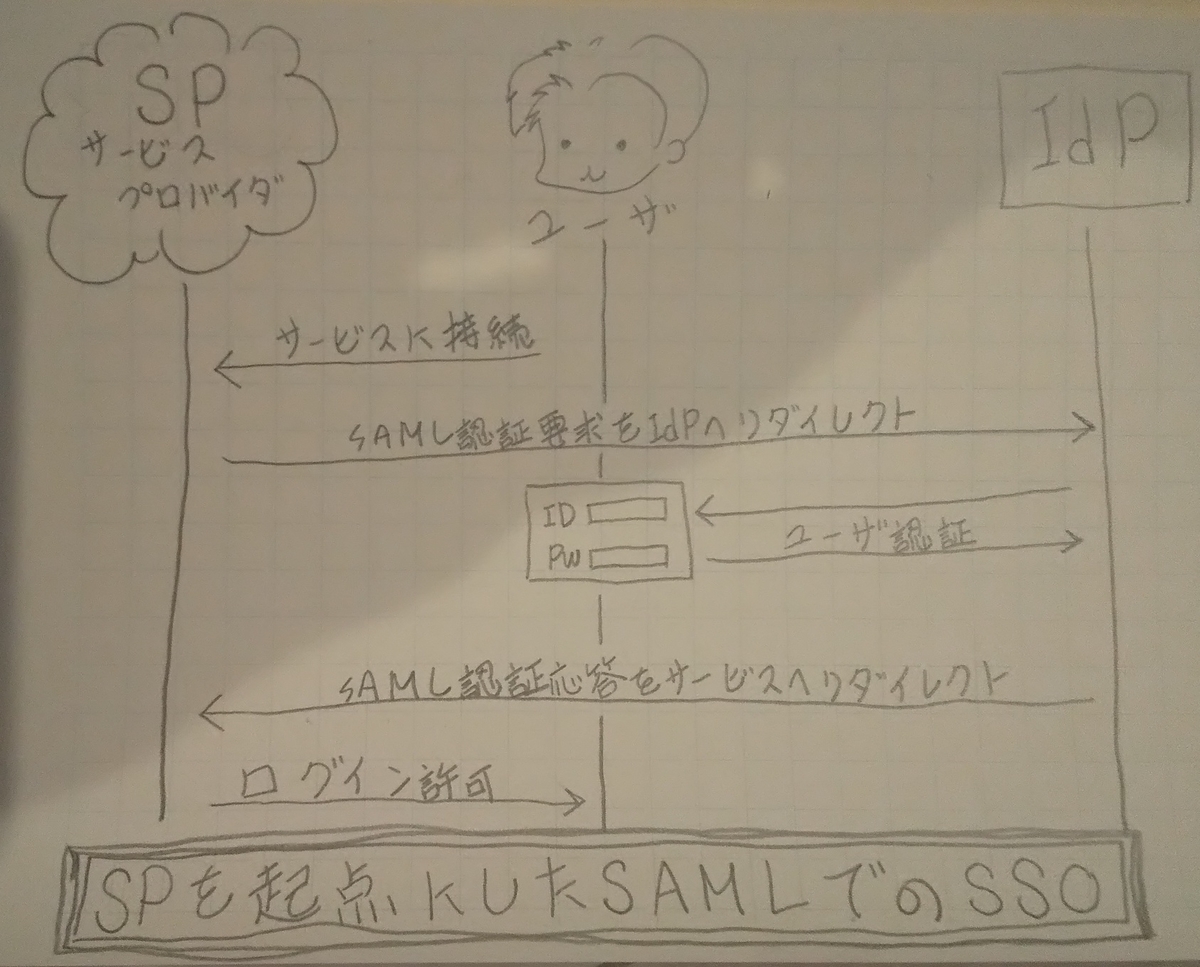
SAMLを使うSSOの流れ
- ユーザがサービスに接続する
- サービスがSAML認証要求をユーザを経てIdPに送信する
- IdPの認証画面でユーザはログインすることで認証処理をする
- IdPがSAML認証応答をユーザ経てサービスに送信する(SAMLアサーション)
- ユーザがサービスにログインできる
シングルサインオンの実装方式の一つであるSAML認証の特徴はどれか。
- IdP(Identity Provider)がSP(Service Provider)の認証要求によって利用者認証を行い,認証成功後に発行されるアサーションをSPが検証し,問題がなければクライアントがSPにアクセスする。<< 正解
- Webサーバに導入されたエージェントが認証サーバと連携して利用者認証を行い,クライアントは認証成功後に利用者に発行されるcookieを使用してSPにアクセスする。
- 認証サーバはKerberosプロトコルを使って利用者認証を行い,クライアントは認証成功後に発行されるチケットを使用してSPにアクセスする。
- リバースプロキシで利用者認証が行われ,クライアントは認証成功後にリバースプロキシ経由でSPにアクセスする。
出典 : 令和3年 秋期 情報処理安全確保支援士 午前Ⅱ 問4
ぽんすけは、Chromeを使う時にChromeにログインしようとするとCloudGate UNOのログイン画面が表示されてログインするとChromeのアカウントにログインできます。
これは「CloudGate UNOというIdP」が「Google Workspaceというサービスプロバイダ」から認証要求を受けて「ぽんすけというクライアント」をSSOできるようにしているのです。
参考 : Google Workspace向けSSOサービス | CloudGate UNO(クラウドゲートウノ)
